文字识别 tesseract-ocr 安装和配置
1,先找到需要使用版本的tesseract,并下载tesseract安装包到本地,执行.exe文件安装到本地。下载地址:https://github.com/UB-Mannheim/tesseract/wiki或:https://tesseract-ocr.github.io/tessdoc/4.0-with-LSTM.html#400-alpha-for-windows 找到自己需要的安装包2,
1,先找到需要使用版本的tesseract,并下载tesseract安装包到本地,执行.exe文件安装到本地。
下载地址:https://github.com/UB-Mannheim/tesseract/wiki
或: https://tesseract-ocr.github.io/tessdoc/4.0-with-LSTM.html#400-alpha-for-windows 找到自己需要的安装包
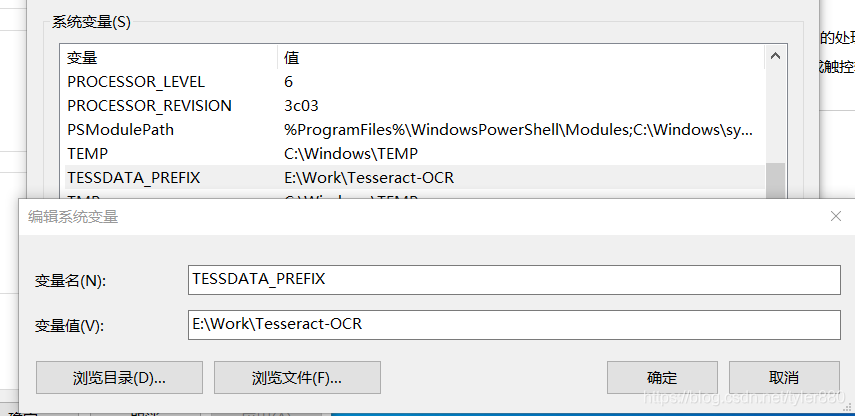
2,安装完成后,需要在环境变量的系统变量添加 变量名为:TESSDATA_PREFIX ,值为tesseract的安装路径,如下
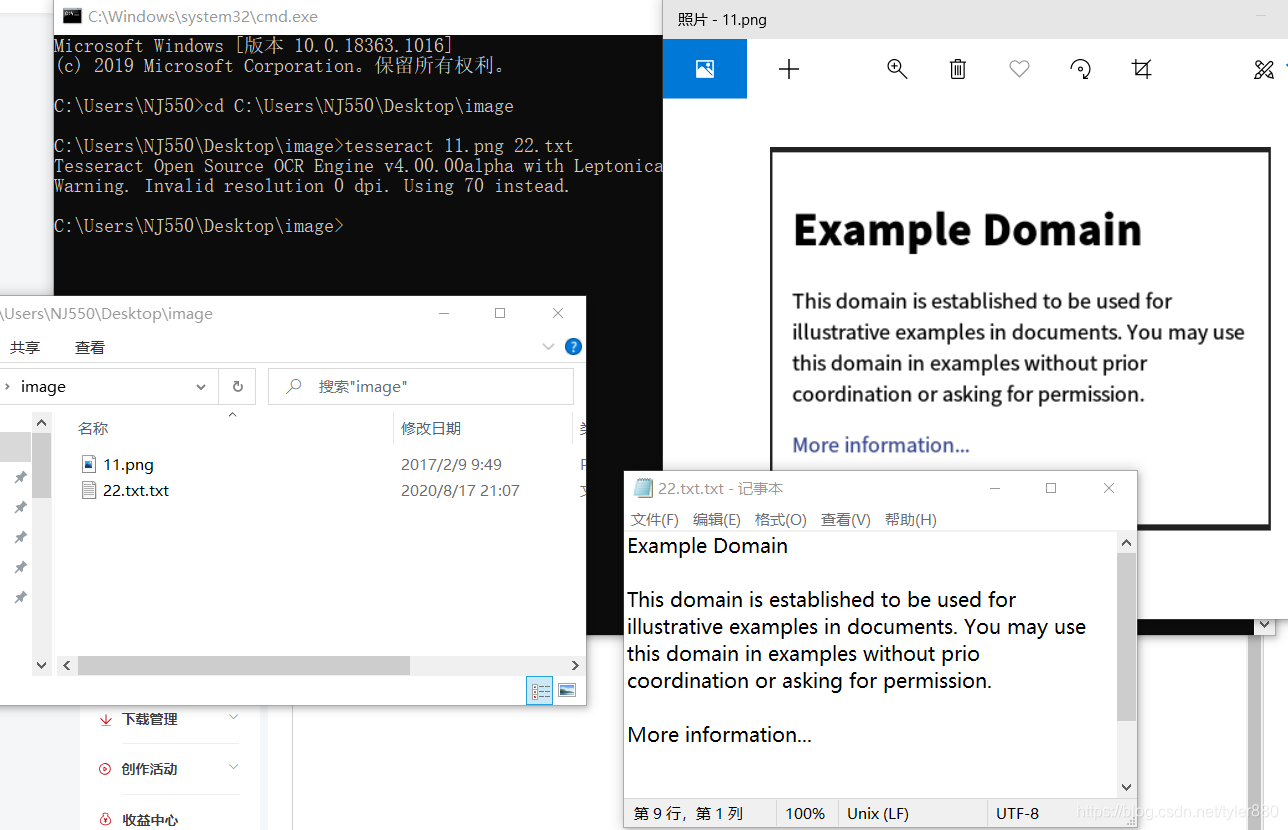
3,环境变量配置好后,就可以在cmd命令窗口用命令:tesseract 11.png 22.txt 识别图片的文字并保存为txt文本,如下:
4,在python使用时,需要用pip install pytesseract 安装pytesseract , 在使用时如发生错误,如下:
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
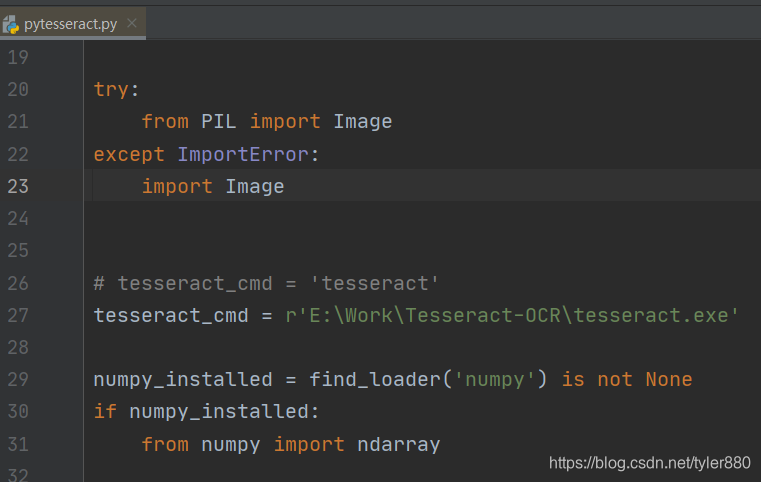
则需要在pytesseract.py 文件中将 tesseract_cmd = 'tesseract' 改成安装tesseract的路径,如:
tesseract_cmd = r'E:\Work\Tesseract-OCR\tesseract.exe'
一切就绪后,则可以在python编写代码如下:
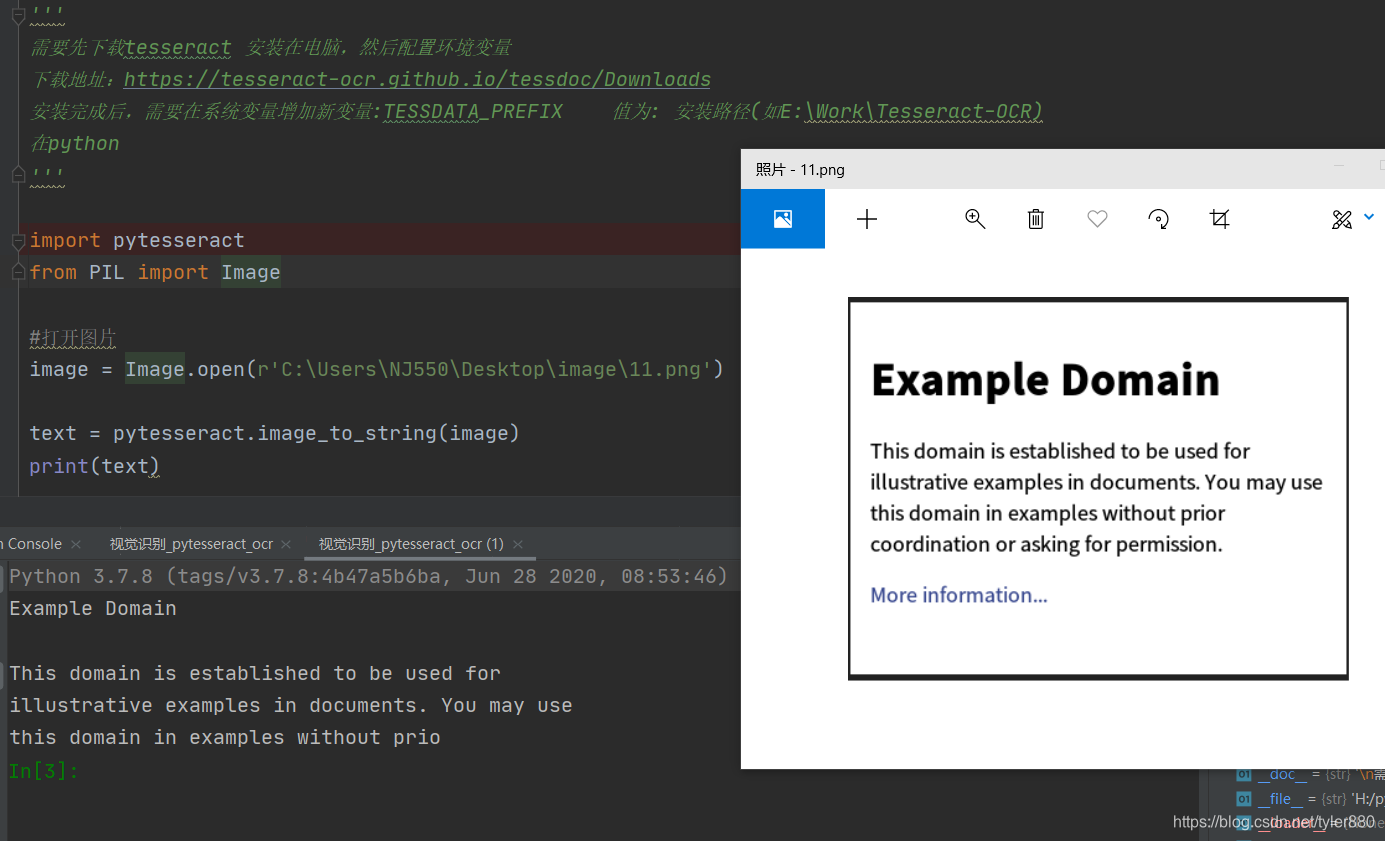
运行正常,照片字体越大越清晰,识别率越高!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)