【论文翻译】有效的转移和无监督的深度学习医学图像分析方法
1 RESEARCH PROBLEM
1.1 Introduction
Thanks to computational and algorithmic advances, as well as an increasing availability of vast amounts of data, deep learning techniques have substantially improved over the past decade (LeCun et al., 2015). Specifically,inrecentyears,deep learning techniques have been successfully applied to the field of image analysis (Szegedy et al., 2016a), speech recognition(Hintonetal.,2012),and natural language processing (Mikolov et al., 2013), showing that they are increasingly able to outperform traditional machine learning approaches that typically rely on manual feature engineering. Furthermore, in collaboration with healthcareinstitutes,companieslikeGoogle and IBM have recently started with the application of deep learning techniques to medical use cases. As an example, the authors of (Wong and Bressler, 2016) discuss the usage of deep learning techniques for diagnosingdiabeticretinopathy,aneyediseasethatoccurs when diabetes causes damage to the retina.
Compared to the application of conventional machine learning approaches to medical images, the application of deep learning techniques remains challenging. Indeed, medical image sets are often limited in size and (partially) unlabeled (Chen and Lin, 2014), due to privacy concerns, acquisition difficulties, and/or the time-consuming nature of manual labeling. However, when applying deep learning techniques, the following rule of thumb usually holds true: themoredatathatcanbeleveragedduringtraining, the higher the effectiveness of prediction (LeCun etal.,2015). Asaresult,giventhatitisdifficulttoget access to vast collections of properly labeled medical images, predictive models obtained through the usage of deep learning techniques typically suffer from overfitting, thus leading to inaccurate diagnoses.
Restrictions in terms of size and labeling are not limited to medical datasets; datasets in other application areas are facing these challenges as well(Santoro et al., 2016). Therefore, more and more research efforts are dedicated to addressing these shortcomings. One promising approach towards dealing with small-sized datasets is the usage of transfer learning, a technique that can be used to improve a model from one domain by leveraging knowledge from a related domain. Compared to training from scratch withsmalldatasets,experimentalanalysishasdemonstrated that transfer learning may reduce the relative error with up to 50% (Yosinski et al., 2014; Azizpour et al., 2015). However, compared to training from scratch with vast datasets, there is still significant room for improvement (Szegedy et al., 2016a). Another interesting approach towards dealing with small-sized datasets, as well as with a lack of labeled samples, is the usage of unsupervised deep learning,whichallowsexposingstructureandsemantics in unlabeled datasets. Indeed, several unsupervised deep learning techniques have recently been introduced, for instance making it possible to generate similar images out of a given set of images. Our doctoral research will focus on the constructionandevaluationofnewpredictivemodelsformedical image diagnosis, through the development of novel methods for effective transfer learning and unsupervised deep learning, so to be able to overcome limitations in terms of size and labeling. In the following section, we outline a number of relevant research questions that we set out to answer.
由于计算和算法的进步,以及海量数据的日益可用性,深度学习技术在过去十年中得到了极大的改善(LeCun et al., 2015)。具体来说,inrecentyears,深度学习技术已经成功地应用于图像分析领域(Szegedy et al ., 2016),语音识别(Hintonetal, 2012),和自然语言处理(Mikolov et al ., 2013),表明他们越来越能够超越传统的机器学习方法,通常依靠手动功能工程。此外,在与医疗保健机构的合作中,谷歌和IBM等公司最近开始将深度学习技术应用于医疗用例。例如,(Wong和Bressler, 2016)的作者讨论了利用深度学习技术诊断糖尿病视网膜病变的方法。
与传统机器学习方法在医学图像上的应用相比,深度学习技术的应用仍然具有挑战性。事实上,由于隐私问题、获取困难和/或人工标记的耗时性,医学图像集的大小往往有限,(部分)未标记(Chen and Lin, 2014)。然而,在应用深度学习技术时,以下经验法则通常是成立的:训练中数据越多,预测的有效性越高(LeCun etal.,2015)。结果,由于难以获得大量正确标记的医学图像,通过使用深度学习技术获得的预测模型通常会出现过拟合,从而导致诊断不准确。
在尺寸和标签方面的限制不限于医疗数据集;其他应用领域的数据集也面临这些挑战(Santoro et al., 2016)。因此,越来越多的研究致力于解决这些缺点。处理小型数据集的一个很有前途的方法是使用转移学习,这种技术可以利用相关领域的知识来改进一个领域的模型。与使用小数据集从零开始训练相比,实验分析表明,转移学习可以减少50%的相对误差(Yosinski等,2014;Azizpour等人,2015)。然而,与使用大量数据集从零开始的培训相比,仍然有很大的改进空间(Szegedy et al., 2016a)。另一种处理小型数据集和缺少标记样本的有趣方法是使用无监督深度学习,它将未标记数据集的结构和语义简化。事实上,一些无监督的深度学习技术最近已经被引入,例如使从一组给定的图像生成类似的图像成为可能。我们的博士研究将通过开发有效转移学习和无监督深度学习的新方法,以构建和贬值医学图像诊断的新预测模型,从而克服在尺寸和标记方面的限制。在接下来的章节中,我们将概述一些我们打算回答的相关研究问题。
2 STATE-OF-THE-ART
In this section, we examine a couple of state-of-theart approaches related to transfer learning and unsupervised deep learning. By having a close look at these approaches, we are able to develop our own approaches towards overcoming challenges in the area of deep learning-based medical image analysis.
在这一节中,我们研究了与转移学习和无监督深度学习相关的两种最先进的方法。通过仔细研究这些方法,我们能够开发自己的方法来克服基于深度学习的医学图像分析领域的挑战。
2.1 TransferLearning
Transfer learning is typically implemented by means of the following two steps (Yosinski et al., 2014):
- Given a task, train a source network on a source dataset.
- Given another task, transfer the learned features to a target network for a particular target dataset.
The above two steps can be formally expressed as follows (Pan and Yang, 2010):
”Given a source domain DS and a learning task TS, a target domain DT and a learning task TT, transfer learning aims at improving the learning of the target prediction function fT() in DT using the knowledge in DS and TS, where DS 6= DT, or TS 6=TT.” In (Yosinski et al., 2014), the authors demonstrate thehightranferabilityofadeepneuralnetwork,using an AlexNet architecture trained on ImageNet. In doingso,theymakeuseoffine-tuning,atechniquesthat adapts the pre-trained network to the target dataset and task by adjusting the learned features, with the goalofachievingahighereffectiveness. Inparticular, the last layer of the network is replaced with a new layer that takes into account the characteristics of the targetdataset(Girshicketal.,2014). Theauthorsthen experiment with freezing different layers and retrainingtheremaininglayerstofindthebestwaytorealize transfer learning. In summary, the authors of (Yosinski et al., 2014) were able to make the following observations. First, when the source and target datasets were similar, transfer learning slightly outperformed a source network by 0.02 in terms of top-1 accuracy. However, when dissimilar datasets were fed to the network, the effectiveness dropped by 0.10 in terms of top-1 accuracy. The latter observation was also confirmed by (Azizpour et al., 2015), illustrating that effective transfer learning remains an open research challenge.
给定一个任务,在源数据集上训练一个源网络。2. 给定另一个任务,将学到的特性转移到特定目标数据集的目标网络。以上两个步骤可以正式表述为(Pan and Yang, 2010):
”Given 源 域 DS 和 学习 任务 TS, 目标 域 DT 和 学习 任务 TT, 转移 目标 预测 的 学习 旨在 提高 学习 函数 fT() DT 使用 DS 中的 知识 和 TS, DS 6 = DT, 或 TS 6 =TT.(Yosinski et al., 2014),作者使用在ImageNet上训练的AlexNet架构,证明了一个神经网络的高可移植性。在此过程中,他们利用调优技术,通过调整学习到的特征,使预先训练好的网络适应目标数据集和任务,从而达到提高效率的目的。特别是,网络的最后一层被考虑到targetdataset特征的新层所取代(Girshicketal.,2014)。然后,作者尝试冻结不同的层次,并对其中的一个层次进行再培训,以找到实现转移学习的最佳方式。总之,(Yosinski et al., 2014)的作者能够做出以下观察。首先,当源数据集和目标数据集相似时,传输学习的正确率比源网络略高0.02。然而,当将不同的数据集输入网络时,效率在前1名的准确度上下降了0.10。后一种观点也得到了(Azizpour et al., 2015)的证实,表明有效的迁移学习仍然是一个开放的研究挑战。
2.2 UnsupervisedDeepLearning
A generative model is self-explanatory in nature,producing samples that share similar features with samples available in a source dataset. Producing samples is often done by making use of Markov Chain Monte Carlo sampling, and Gibbs sampling in particular. Proposed by Geoffrey Hinton in 1985 (Ackley et al., 1985), Boltzmann Machines and derivative models such as Restricted Boltzmann Machines, Deep Belief Networks, and Deep Boltzmann Machines are representativeexamplesofdeepgenerativemodels(Goodfellowetal.,2016). Asdiscussedinthenextsections, new approaches for sample generation have recently been proposed, seeing their combination with deep learning techniques.
生成模型本质上是自解释的,生成的样本与源数据集中可用的样本具有相似的特征。生产样品通常采用马尔可夫链蒙特卡罗抽样,特别是吉布斯抽样。1985年Geoffrey Hinton (Ackley etal., 1985)提出,Boltzmann机器和受限Boltzmann机器、深度信念网络、深度Boltzmann机器等衍生模型是deepgenerativemodels的代表性实例(Goodfellowetal.,2016)。在讨论范围内,最近提出了新的样本生成方法,将其与深度学习技术相结合。
2.2.1 Variational Auto encoders
The Variational Auto encoder (VAE) proposed by (Kingma and Welling, 2013) has a structure that is similar to the structure of the vanilla auto encoder introduced in (Rumelhart et al., 1985). However, the VAE is a stochastic model that makes use of a probabilistic encoder qφ = (z|x) to approximate the true posterior distribution p(z|x) of the latent variables, where x is a discrete or continuous variable and where z is an unobserved continuous random variable. Due to the intractability of the posterior distribution, the authors suggest the use of the Stochastic Gradient Variational Bayes (SGVB) estimator to approximate the true posterior distribution of the latent variables. The SGVB estimator enables backpropagation by adopting ε, where ε∼N (µ,σ) and where z = µ+εσ, with µ denoting the mean and σ the standard deviation. By leveraging a stochastic graphical model with a Bayesian network, VAEs have been successfully used for the purpose of generating handwritten digits(KingmaandWelling,2013;Salimansetal.,2015) and face images (Rezende et al., 2014).
(Kingma and Welling, 2013)提出的变分自动编码器(ational Auto encoder, VAE)的结构与Rumelhart等人(1985)介绍的vanilla 自动编码器的结构相似。然而,VAE概率的随机模型,利用编码器qφ= (z | x)近似真实的后验分布p (z | x)的潜在变量,其中x是一个离散的或连续的变量,z是一个难以察觉的连续随机变量。由于后验分布的复杂性,作者建议使用随机梯度变分贝叶斯(SGVB)估计器来近似潜在变量的真实后验分布。SGVB估计量使反向传播采用ε,ε∼N(µσ)和z =µ+εσµ指示均值和标准差σ。通过利用贝叶斯网络的随机图形模型,VAEs已经成功地用于生成手写数字(KingmaandWelling,2013;Salimansetal,2015)和人脸图像(Rezende等,2014)。
2.2.2 Generative Adversarial Networks
A Generative Adversarial Network (GAN), as proposed in (Goodfellow et al., 2014) and as visualized in Figure 1, consists of two parts: a generator and a discriminator. The generator produces new samples similartotherealdatathatwerefedintothenetwork. The newly produced samples are then judged by the discriminator, to determine whether they are counterfeitinnatureornot. Byrepeatingthetrainingprocess, the network is able to find an equilibrium for both. A deep convolutional GAN(Radfordetal.,2015), typically abbreviated as DCGAN, also consists of a generator and a discriminator. However, the sample generationanddiscriminationprocessesaredifferent. In particular, in a DCGAN, the generator makes use ofdeep convolutionalnetworks, whereasthe discriminator is implemented by means of deconvolutions. As discussed by (Frans, 2016), since VAEs follow an encoding-decoding scheme, we can compare the generated images directly to the original images, something that is not possible to do with GANs. Moreover, GANs are more difficult to optimize due to unstable training dynamics (the generator and discriminator sub-networks within a GANa retrained using opposed target functions). However, given that VAEs use mean squared error instead of an adversarial network, GAN images are currently more sharp than VAE images. Indeed, GANs are able to detect and thus reject blurry images. Given the focus of GANs to learn to make images that look real in general, the synthesized images tend to combine features from different types of objects. Two research efforts that aim at exercising more control over this behaviour are (Salimans et al., 2016) and (Chen et al., 2016), and where both research effortsaddmultipleobjectivestothecostfunctionofthe discriminator. Furthermore,research efforts have also been dedicated to mitigating VAE bluriness, eitherby making use of perceptual quality metrics (Dosovitskiy and Brox, 2016) or by making use of a recurrent generative autoencoder(Guttenbergetal.,2016). Finally, it is interesting to point out that initial research has also been done on combining VAEs and GANs, using the same encoder-decoder configuration,but leveraging an adversarial network as a metric for training the decoder (Boesen et al., 2015).
在(Goodfellow et al., 2014)中提出并在图1中显示的生成式对抗网络(GAN)由两个部分组成:生成器和鉴别器。发电机产生的新样品与网络上的数据相似。然后,鉴别器对新生产的样品进行判断,以确定它们是否是天然的仿制品。通过重复训练过程,网络能够找到两者之间的平衡。一个深卷积GAN(Radfordetal.,2015),通常缩写为DCGAN,也包括一个发生器和一个鉴别器。然而,样本产生和鉴别过程是不同的。特别是在DCGAN中,发生器利用深卷积网络,而鉴别器是通过反卷积实现的。正如(Frans, 2016)所讨论的,由于VAEs遵循编码-解码方案,我们可以直接将生成的图像与原始图像进行比较,而这是GANs无法做到的。此外,由于不稳定的训练动态(GANa中使用反目标函数再训练的生成器和鉴别器子网络),GANs更难以优化。然而,考虑到VAEs使用的是均方误差而不是对抗网络,GAN图像比VAE图像更清晰。事实上,GANs能够检测并因此拒绝模糊的图像。由于GANs的重点是学习如何使图像看起来更真实,因此合成的图像往往结合了不同类型对象的特征。两项旨在对这种行为施加更多控制的研究分别是(Salimans等,2016)和(Chen等,2016),这两项研究都努力增加了多目标识别器的功能。此外,研究工作也致力于减轻VAE的模糊性,无论是通过使用感知质量度量(Dosovitskiy和Brox, 2016)还是通过使用循环生成式自动编码器(Guttenbergetal,2016)。最后,有趣的是,最初的研究也结合了VAEs和GANs,使用相同的编码-解码器配置,但利用对抗网络作为训练解码器的度量(Boesen等人,2015)。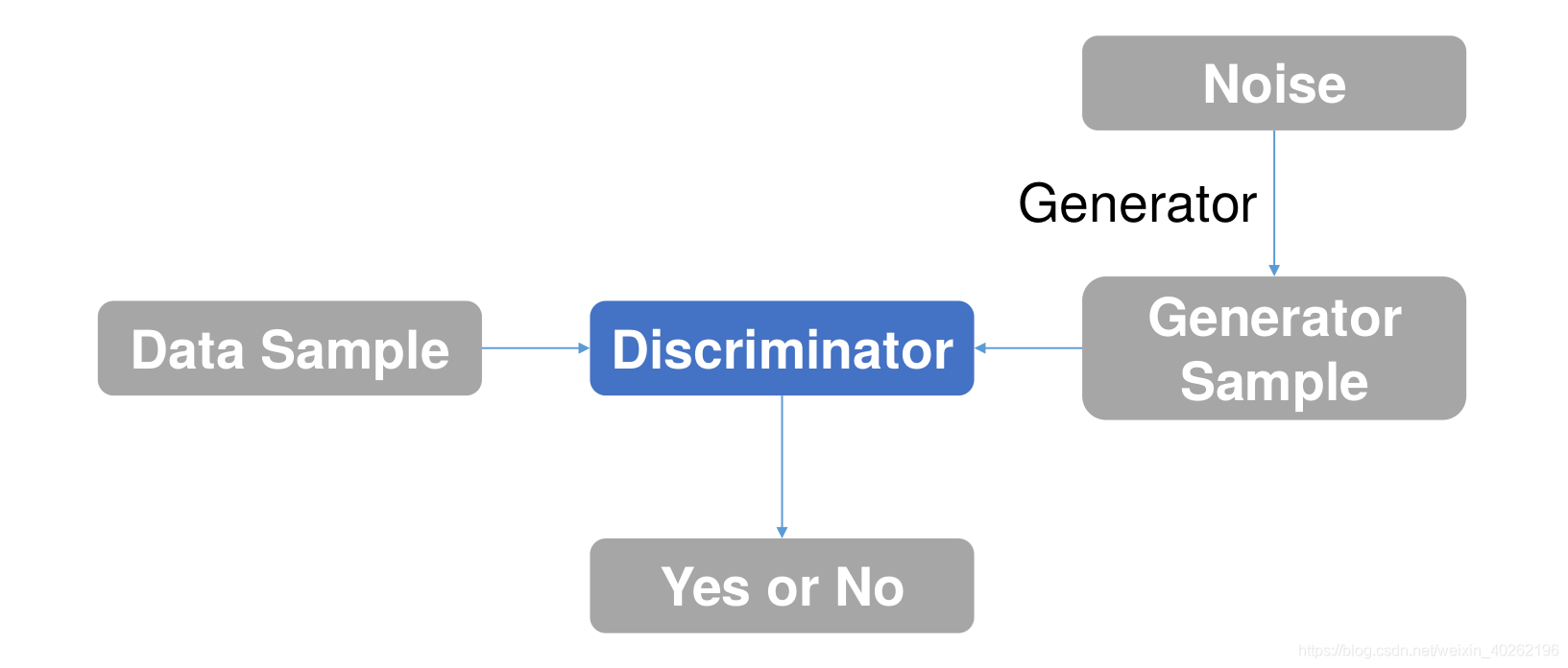
3 OUTLINEOFOBJECTIVES
The main objective of our research is to construct novel predictive models for medical image diagnosis. In that regard, we plan to develop and evaluate novel deep learning-based techniques that are complementary to already existing techniques, answering the research questions formulated in Section1.2. Particular attentionwillbepaidtotheconstructionofnovelpredictivemodelsthatmeetthefollowingsub-objectives:
• Reliability - This is he most important factor in medical use cases. Therefore, our research will focus on obtaining high values for metrics such as accuracy, sensitivity, and specificity, and where these metrics are widely used inthe field of medical image analysis(LalkhenandMcCluskey, 2008). We discuss these metrics in more detail in Section 4.2.
• Transferability-Thenewlydevelopedpredictive models need to be transferable. This means that, regardless of the dataset(s) they were trained on, the predictive models will be applicable to other data domains, while still producing reliable results. In other words, thanks to transferability,our predictive models may not only be applied within the same domain, but also across different domains, and where these domains may also come with small-sized data sets (e.g., from analysis of mammogram images to analysis of lung X-ray images).
• Scalability - Since sets of medical images are continuouslyincreasinginsize,wewillbuildpredictive models that can take advantage of an incremental availability of training data.
本研究的主要目的是建立新的医学影像诊断预测模型。在这方面,我们计划开发和评估新的基于深度学习的技术,这些技术是对现有技术的补充。
- 可靠性——这是医疗用例中最重要的因素。因此,我们的研究将集中在获得高价值的指标,如准确性、敏感性和特异性,以及这些指标在医学图像分析领域的广泛应用(LalkhenandMcCluskey, 2008)。我们将在第4.2节中更详细地讨论这些度量。
- 可转移性——新开发的预测模型需要可转移。这意味着,无论他们所训练的数据集是什么,预测模型都将适用于其他数据域,同时仍然产生可靠的结果。换句话说,由于可转移性,我们的预测模型不仅可以应用于同一领域,还可以应用于不同的领域,这些领域也可以使用小型数据集(例如,从乳房x线照片分析到肺部x线图像分析)。
- 可扩展性——由于医学图像集的尺寸不断增加,我们将建立可利用增量可用性训练数据的预测模型。
4 METHODOLOGY
We make a distinction between two stages:
(1) development of novel predictive models for medical image analysis, leveraging techniques for transfer learning and unsupervised deep learning, and
(2) an extensive quantitativeevaluationofthenewlydevelopedpredictive models.
我们将其分为两个阶段:(1)开发新的医学图像分析预测模型,利用转移学习和无监督深度学习技术,(2)对新开发的预测模型进行广泛的定量评估。
4.1 Development
• Datasets - Starting from a mammography image dataset for the purpose of detecting breast cancer,severaladditionalmedicalimagedatasetswill be selected, related to different image modalities (e.g., X-ray and Computed Tomography (CT)) and diseases (e.g., diabetic retinopathy, tuberculosis, and lung cancer). The selection of proper datasets will be followed by data-specific preprocessing.
• Source Network-Asoursourcenetwork,we will make use of InceptionV4(Szegedyetal.,2016b), a deep neural network architecture developed by Google. We have selected this network because it achieved the best top-5 accuracy in 2016 for the task of image recognition (that is, a top-5 accuracy of 95.2%), outperforming other state-of-theart deep neural networks. Also, since it is a deep neuralnetworkwithrepeatedinceptionblocks,we can easily observe the occurrence of overfitting, and a poor effectiveness of prediction in general, when doing vanilla training by means of a small dataset. Thus, we will demonstrate the effectiveness of our approach by comparing the results obtained through vanilla training with the result sobtained through transfer learning and fine-tuning.
• Vanilla Training - We will train the source network on a given dataset, using the network obtained as a baseline.
• Tranfer Learning with Fine-tuning - As shown in Figure 2, transfer learning will be performed,
followed by fine-tuning. In our research, we will experiment with different strategies for transfer leaning and fine-tuning.• Data Augmentation - Depending on the dataset used, various techniques for data augmentation will be implemented for the purpose of vanilla training and transfer learning. Commonly used data augmentation techniques are rotation, vertical flipping, horizontal flipping, translation, contrast enhancement, and saturation.
• Unsupervised Learning - Considering the presenceofunlabeledimagesandthedata-hungrynature of deep learning techniques, we will develop unsupervised neural networks, combining VAEs and DCGANs. For example, samples can be generated by a VAE, and these samples can then be investigated by a deep discriminator, constructed through transfer learning, so to see whether the samples are real (representative) or fake (nonrepresentative) in nature.
从用于检测乳腺癌的乳房x光造影图像数据集开始,将选择与不同的图像模式(如x射线和计算机断层扫描(CT))和疾病(如糖尿病视网膜病变、结核病和肺癌)相关的几种额外的医学图像集。选择适当的数据集之后,将进行数据特定的预处理。我们将使用由谷歌开发的深度神经网络架构InceptionV4(szege染料tal.,2016b)。我们选择这个网络是因为它在2016年的图像识别任务中获得了最好的前5名精度(即95.2%的前5名精度),超过了其他最先进的深度神经网络。此外,由于它是一个带有重复切感块的深神经网络,我们可以很容易地观察到过度拟合的发生,并且在使用小数据集进行常规训练时,预测效果通常很差。因此,我们将通过比较通过普通训练获得的结果和通过转移学习和微调获得的结果来证明我们的方法的有效性。
• Vanilla训练——我们将在给定数据集上训练源网络,使用获得的网络作为基线。
•微调转移学习-如图2所示,将进行转移学习,其次是微调。在我们的研究中,我们将尝试不同的转移学习和微调策略。
•数据扩充——根据使用的数据集,不同的数据扩充技术将用于普通的培训和转移学习。常用的数据增强技术有旋转、垂直翻转、水平翻转、平移、对比度增强和饱和度。
•无监督学习——考虑到无监督学习的存在和深度学习技术对数据的渴求,我们将开发结合VAEs和DCGANs的无监督神经网络。例如,样本可以由VAE生成,然后通过传输学习构造的深层鉴别器对这些样本进行调查,从而了解样本在本质上是真实的(有代表性的)还是虚假的(无代表性的)。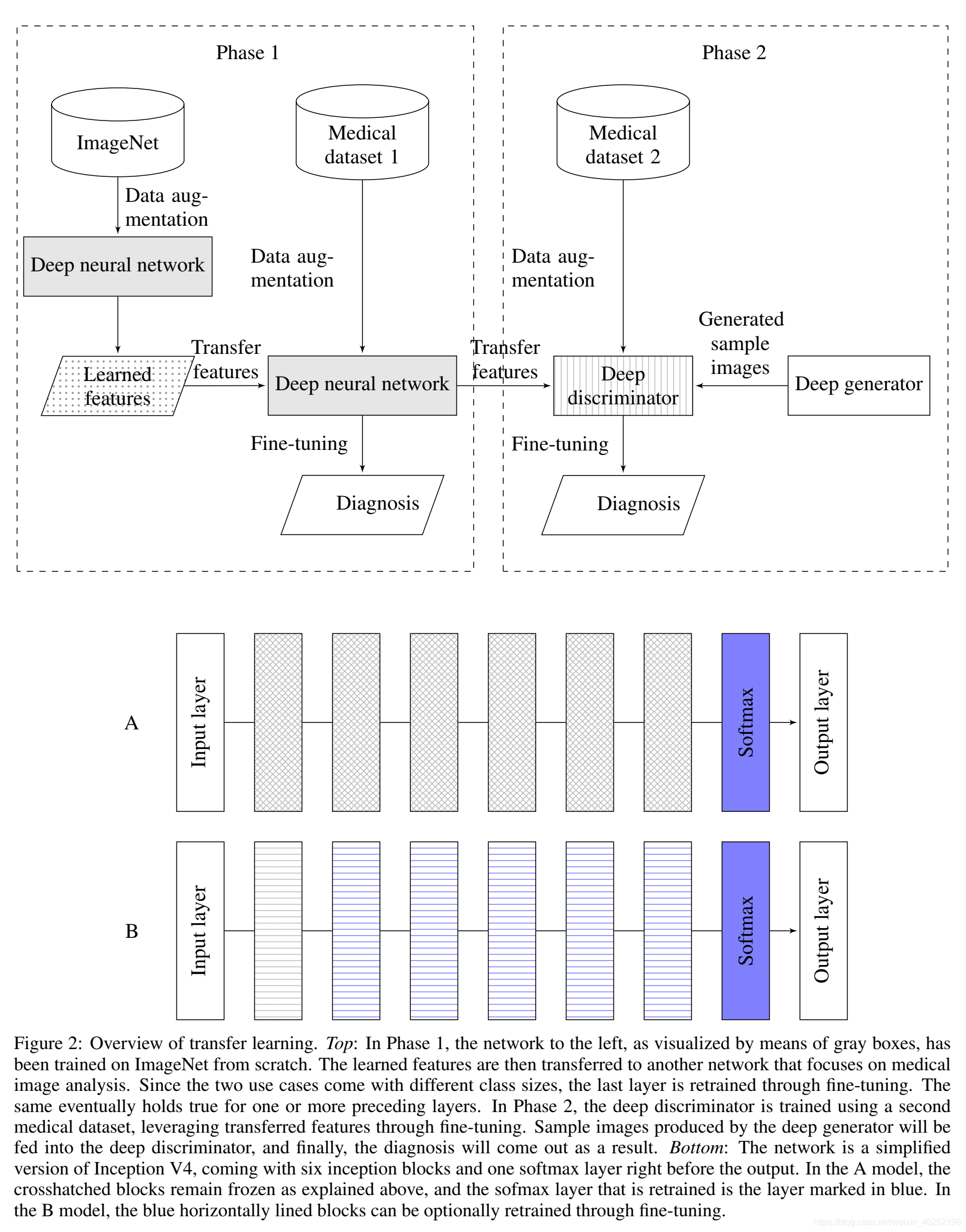
Figure 2: Overview of transfer learning. Top: In Phase 1, the network to the left, as visualized by means of gray boxes, has been trained on ImageNet from scratch. The learned features are then transferred to another network that focuses on medical image analysis. Since the two use cases come with different class sizes, the last layer is retrained through fine-tuning. The same eventually holds true for one or more preceding layers. In Phase 2, the deep discriminator is trained using a second medical dataset, leveraging transferred features through fine-tuning. Sample images produced by the deep generator will be fed into the deep discriminator, and finally, the diagnosis will come out as a result. Bottom: The network is a simplified version of Inception V4, coming with six inception blocks and one softmax layer right before the output. In the A model, the crosshatched blocks remain frozen as explained above, and the sofmax layer that is retrained is the layer marked in blue. In the B model, the blue horizontally lined blocks can be optionally retrained through fine-tuning.
图2:迁移学习概述。Top:在第1阶段,通过灰色方框可视化的左侧网络已经从零开始在ImageNet上进行训练。然后将学习到的特征转移到另一个专注于医学图像分析的网络中。由于这两个用例具有不同的类大小,所以最后一层是通过微调重新训练的。对于前面的一个或多个层也是如此。在第二阶段,使用第二个医疗数据集对深度鉴别器进行训练,通过微调利用传输的特征。将深度发生器产生的样本图像输入到深度鉴别器中,最终得到诊断结果。底部:网络是Inception V4的简化版本,在输出之前有六个Inception块和一个softmax层。在A模型中,如上所述,交叉标记的块保持冻结状态,重新训练的sofmax层是用蓝色标记的层。在B模型中,可以通过微调选择性地重新训练水平方向上的蓝色块。
4.2 Evaluation
Our research will primarily focus on assessing the effectiveness of the novel predictive models developed. In practice, the effectiveness of deep learning-based imageclassificationisdeterminedbycalculatingmetrics like accuracy, recall, precision, and F-measure. When it comes to medical imaging analysis, we need toconsidertwoadditionalmetrics, namelyspecificity and ROC curve. Thus, as shown in Figure 3, we will make use of the following six metrics in our doctoral research:
• Accuracy-Thisisoneofthemostimportantmetrics to evaluate the effectiveness of a predictive model. Itreferstotheclosenessbetweenthecomputed outcomes and the diagnosed labels.
• Recall - This metric, which is also known as sensitivity, measures the proportion of positives that are correctly identified as such.
• Precision - This metric indicates how closely the computed outcomes are to the diagnosed labels, regardless of the accuracy.
• F-measure- This metric is the harmonic mean of recall and precision. When equally weighted, we refer to this metric as F1. Depending on the purpose of a particular research effort, we can place more weight on recall (F2) or precision (F0.5).
• Specificity - This metric measures the proportion of negatives that are correctly identified as such. Together with recall, it is considered to be one of the most important metrics in the area of medical image analysis (Pewsner et al., 2004; Weinstein et al., 2005).
• ROC Curve - This metric represents the relation between the true positive fraction and the false
positive fraction (Hajian-Tilaki, 2013). The accuracy, the recall, the precision, and the F1 score will help in preventing our models from suffering from the accuracy paradox,where asthere call,the specificity, and the ROC curve will help in demonstrating the validity of our models.
我们的研究将主要集中在评估新开发的预测模型的有效性。在实践中,基于深度学习的图像分类的有效性是通过计算精度、回忆、精度和F-measure来确定的。当涉及到医学影像学分析时,我们需要考虑两个额外的指标,即特异性和ROC曲线。因此,如图3所示,我们将在我们的医学研究中使用以下6个指标:它指的是评估结果和诊断标签之间的对比。
- 召回——这个指标,也被称为敏感度,衡量的是被正确识别为阳性的比例。精度-这个指标表示计算结果与诊断标签的密切程度,而不考虑准确性。
- F值——这个度量是召回率和精确度的调和平均值。当等权重时,我们称这个度量为F1。根据特定研究的目的,我们可以更重视召回率(F2)或精确度(F0.5)。
- 特异性——这个指标衡量的是被正确识别为阴性的比例。与召回一起,它被认为是医疗领域图像分析最重要的指标之一(Pewsner et al., 2004;温斯坦等人,2005)
- ROC曲线-该指标表示真正分数与假分数之间的关系正分数(Hajian-Tilaki, 2013)。准确性、召回率、精确性和F1分数将有助于防止我们的模型遭受准确性悖论,而特异性和ROC曲线将有助于证明我们的模型的有效性。
5 EXPECTED OUTCOME
In our doctoral research, we will develop new endto-end learning tools for the construction of novel predictive models that target medical diagnosis (see Phase2inFigure2). The novel predictive models are intended to be optimal in terms of (1) reliability, (2) transferability, and (3) scalability.
在我们的研究中,我们将开发新的端到端的学习工具,用于构建针对医学诊断的新型预测模型(见Phase2inFigure2)。新的预测模型在可靠性、可移植性和可扩展性方面都是最优的。
到目前为止,我们已经使用6.1.1节中讨论的乳房x线照相术数据集执行了以下步骤。数据集的预处理。2. 应用不同类型的深度学习技术,无论是从零开始,还是利用培训前和转移学习。3.使用几个指标,即准确性、敏感性和特异性,来评估不同技术的有效性。在下一节中,我们将总结我们的初步结果。
6 STAGE OF THE RESEARCH
Thus far, we have performed the steps below, using the mammography dataset discussed in Section 6.1: 1. Preprocessing of the dataset. 2. Application of different types of deep learning techniques, either from scratch or by making use of pre-training and transfer learning. 3. Evaluation of the effectiveness of the different techniques using several metrics, namely accuracy, sensitivity, and specificity. In the following section, we summarize our preliminary results.
到目前为止,我们已经使用6.1:1节中讨论的乳房x线照相术数据集执行了以下步骤。数据集的预处理。2. 应用不同类型的深度学习技术,无论是从零开始,还是利用培训前和转移学习。3.使用几个指标,即准确性、敏感性和特异性,来评估不同技术的有效性。在下一节中,我们将总结我们的初步结果。
6.1 Use Case: Breast Cancer
We have chosen mammography-based diagnosis of breast cancer as our first use case, relying on the publicly available Digital Database for Screening Mammography (DDSM) (Bowyer et al., 1996) (Heath et al., 1998). Breast cancer is the most commonly diagnosed cancer among women. According to the U.S.
我们选择了基于乳房x线照相术的乳腺癌诊断作为我们的第一个用例,依赖于公开可用的数字乳房x线照相术数据库(DDSM) (Bowyer et al., 1996) (Heath et al., 1998)。乳腺癌是女性最常见的癌症。据美国媒体报道。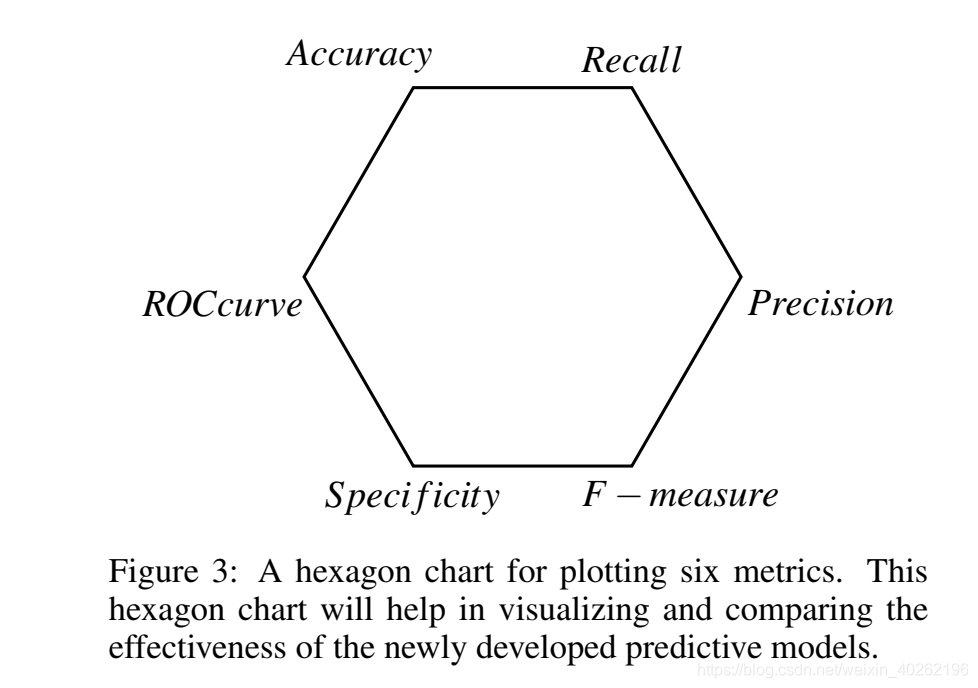
Figure 3: A hexagon chart for plotting six metrics. This hexagon chart will help in visualizing and comparing the effectiveness of the newly developed predictive models.
图3:用于绘制六个度量的六边形图。这个六边形图将有助于可视化和比较新开发的预测模型的有效性。
Breast Cancer Statistics published in2016(BREASTCANCER.ORG, 2016), about 12% of women in the U.S. will develop invasive breast cancer over the course of their lifetime. Moreover, one out of thousand men are also at risk of developing breast cancer. A timely diagnosis of breast cancer can help in improvingthequalityoflifeofapatient. However,making a timely diagnosis is not easy, given that earlystage lesions are difficult to detect in mammography images. Moreover, human errors can lead to a faulty diagnosis as well (Ertosun and Rubin, 2015). The 10,412 images in the DDSM dataset were originally formatted as Lossless JPEG (LJPEG). We converted these images to the Portable Network Graphics(PNG)format by means of a utility available on (Sharma, 2015). The images in the DDSM dataset can also be categorized into two types, depending on the way acquisition was done: Cranial-Caudal (CC) view images and MedioLateral-Oblique (MLO) view images. Each type of image comes with a left- and right-side version per patient, thus resulting in a total of four images per patient.
2016年乳腺癌统计数据(乳腺癌)大约12%的美国女性会在她们的一生中患上侵袭性乳腺癌。此外,千分之一的男性也有患乳腺癌的风险。及时诊断乳腺癌有助于提高病人的生活质量。然而,由于早期病变很难在乳房x线照相术中检测到,及时诊断并不容易。此外,人为错误也可能导致错误的诊断(Ertosun和Rubin, 2015)。DDSM数据集中的10,412张图像最初被格式化为无损JPEG (LJPEG)。我们通过在(Sharma, 2015)上提供的实用工具将这些图像转换为可移植网络图形(PNG)格式。根据获取方式的不同,DDSM数据集中的图像也可以分为两类:头尾侧视图图像(CC)和中侧斜视图图像(MLO)。每种类型的图像每个病人都有一个左侧和右侧的版本,因此每个病人总共有四个图像。

1An image with a positive label indicates that a patient definitely has one or more lesions that can be either benign ormalignant(goldstandardinthiscase). Ontheotherhand, an image with a negative label means that the image under consideration does not have any lesions.
注释1带有阳性标记的图像表明,患者肯定有一个或多个病变,这些病变可以是良性的,也可以是恶性的。另一方面,带有负面标签的图像意味着所考虑的图像没有任何损害。
6.2 Experiments
We performed a first experiment using the following steps:
- As illustrated by the leftmost image in Figure 4, many mammogram images from the dataset used contain a white border, black stains, text, and/or noise. In addition, the size and the orientation of the images may vary. Thus, to only feed regionsof-interest to the network used, we preprocessed the images, removing white borders, text, and noise, followed by a resize operation.
- As shown in Figure 4, a deep convolutional networkistrainedbymakinguseofthepreprocessed images. In this experiment, the network architecture used was InceptionV4. Tomeasurethetransferability of each model, (1) we trained models from scratch and (2) we used a model pre-trained on ImageNet. Data augmentation is used during the training of each model. The data augmentation methods used in this experiment are vertical flipping,horizontalflipping,enhancementofcontrast, change in saturation, and random cropping.
- We conducted a preliminary evaluation. The results obtained are discussed in the next section.
我们使用以下步骤进行了第一个实验:
- 如图4中最左边的图像所示,来自所用数据集的许多乳房x线照片包含白色边框、黑色斑点、文本和/或噪声。此外,图像的大小和方向可能会有所不同。因此,为了只向所使用的网络提供感兴趣的区域,我们对图像进行预处理,删除白色边框、文本和噪声,然后进行调整大小操作。
- 如图4所示,深度卷积网络通过使用预处理图像进行过滤。在这个实验中,使用的网络架构是InceptionV4。为了方便每个模型的可移植性,(1)我们从零开始训练模型,(2)我们使用在ImageNet上预先训练的模型。在每个模型的训练过程中都会用到数据扩充。本实验使用的数据增强方法有垂直翻转、水平翻转、增强对比度、饱和度变化和随机剪切。
3.我们进行了初步评估。所得结果将在下一节讨论。
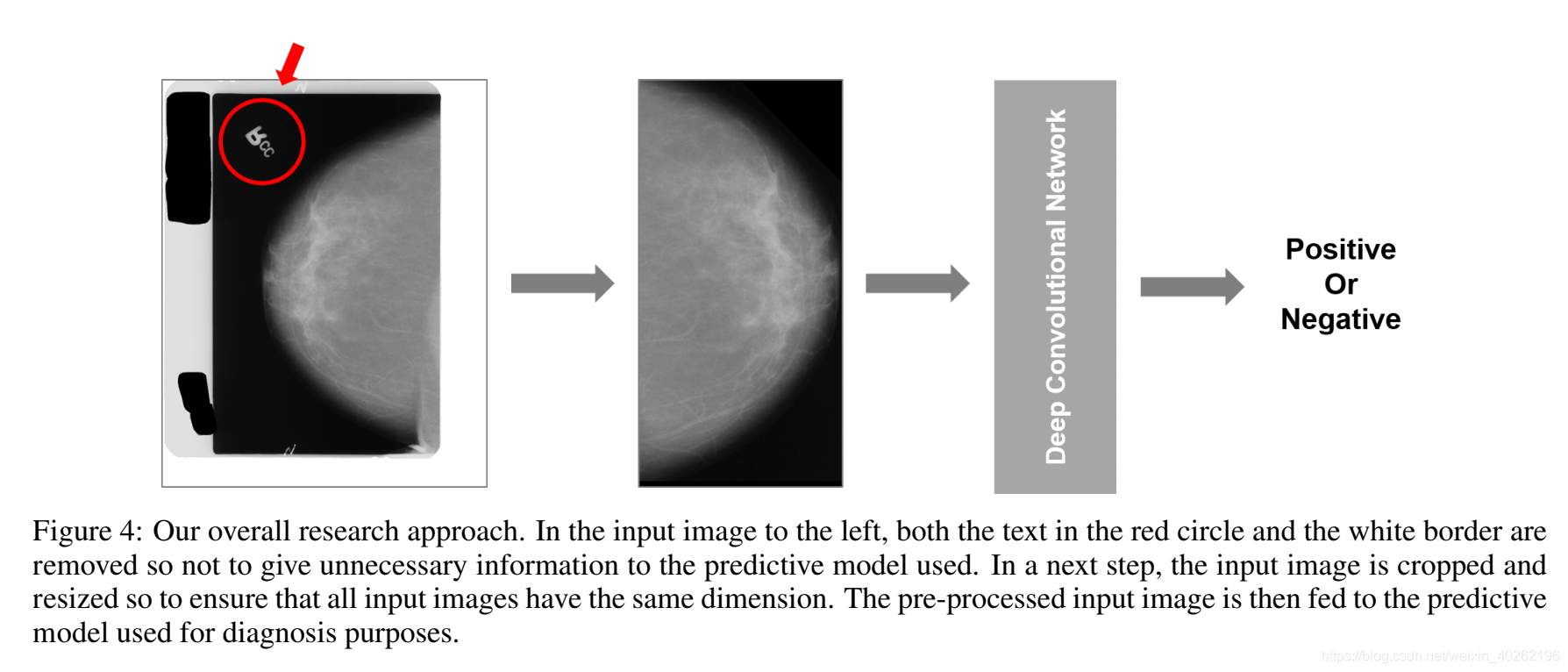
Figure 4 Our overall research approach. In the input image to the left, both the text in the red circle and the white border are removed so not to give unnecessary information to the predictive model used. In a next step, the input image is cropped and resized so to ensure that all input images have the same dimension. The pre-processed input image is then fed to the predictive model used for diagnosis
purposes.
图4 我们的整体研究方法。在左边的输入图像中,红色圆圈中的文本和白色边框都被删除了,以免为所使用的预测模型提供不必要的信息。下一步,裁剪并调整输入图像的大小,以确保所有输入图像具有相同的尺寸。预处理后的输入图像被输入到用于诊断目的的预测模型。
6.3 Results
Compared to the 95.2% of accuracy achieved by InceptionV4on the task of image recognition,the accuracy results shown in Table 2 are significantly lower. Furthermore, and as expected, the experiments that have been performed thus far suffered from overfitting during both vanilla training and transfer learning, and where the latter was done by retraining the last softmax layer. Nevertheless, the use of transfer learning resulted in an accuracy and sensitivity that is slightly higher than the accuracy and sensitivity of vanilla training. Besides, the efficiency of transfer learning was significantly higher than the efficiency of vanilla training: two to three times, depending on the number of layers retrained.
与inceptionv4在图像识别任务中95.2%的准确率相比,表2所示的准确率结果明显较低。此外,正如预期的那样,到目前为止所进行的实验在普通训练和转移学习中都存在过拟合问题,而转移学习是通过对最后一个softmax层进行再训练来实现的。然而,使用转移学习的准确性和敏感性略高于普通训练的准确性和敏感性。此外,转移学习的效率明显高于普通训练的效率:根据重新训练的层数,是普通训练的2到3倍。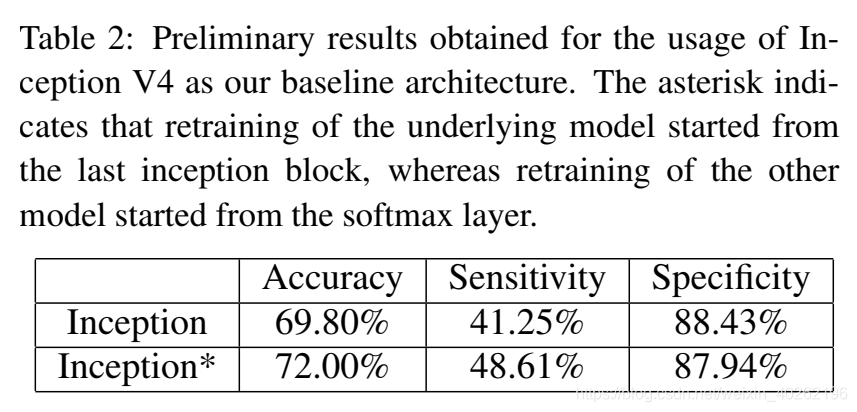
Table 2: Preliminary results obtained for the usage of Inception V4 as our baseline architecture. The asterisk indicates that retraining of the underlying model started from the last inception block, whereas retraining of the other model started from the softmax layer.
表2:使用Inception V4作为基线架构的初步结果。星号表示底层模型的再培训是从最后一个inception块开始的,而另一个模型的再培训是从softmax层开始的。
Figure 4: Our overall research approach. In the input image to the left, both the text in the red circle and the white border are removed so not to give unnecessary information to the predictive model used. In a next step, the input image is cropped and resized so to ensure that all inputi mages have the same dimension. Thepre-processed input image is then fed to the predictive model used for diagnosis purposes.
图4:我们的整体研究方法。在左边的输入图像中,红色圆圈中的文本和白色边框都被删除了,以免为所使用的预测模型提供不必要的信息。下一步,对输入图像进行裁剪和调整大小,以确保所有输入图像具有相同的尺寸。预处理后的输入图像被输入到用于诊断的预测模型中。
At the time of writing, further research using the DDSM dataset is focusing on layer-wise fine-tuning and on applying various combinations of different data augmentation methods.
在撰写本文时,使用DDSM数据集的进一步研究重点是分层微调和应用不同数据增强方法的各种组合。
7. 学习要点
7.1 Fine-tuning
在实践中,由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做特征提取器。
7.1.1 常见的两类迁移学习
以下是常见的两类迁移学习场景:
-
卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。这样提取的特征叫做CNN codes。得到这样的特征后,可以使用线性分类器(Liner SVM、Softmax等)来分类图像。
-
Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常常只需要Fine-tuning训练后面的层。
7.1.2 预训练模型
在ImageNet上训练一个网络,即使使用多GPU也要花费很长时间。因此人们通常共享他们预训练好的网络,这样有利于其他人再去使用。例如,Caffe有预训练好的网络地址Model Zoo。
7.1.3 何时以及如何Fine-tune
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:新数据集的大小、以及新数据和原数据集的相似程度。有一点一定记住:网络前几层学到的是通用特征,后面几层学到的是与类别相关的特征。这里有使用的四个场景:
-
新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
-
新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
-
新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
-
新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
7.1.4 Fine-tune步骤
-
获取已有网络的结构(prototxt)和网络参数(caffemodel),可以从网上下载经典的网络模型与网络结构
-
准备好自己的数据集,一般情况下转换成为lmdb格式。
-
关于均值的计算,可以直接用caffe中的 make_imagenet_mean.sh文件进行计算,有的网络结构种不含有这个参数。
-
根据的自己的需要将最后的全连接的层该为自己所需要的输出,比如是10分类,最后的output就是10,同时改变最后一层的名字,只要不与原来的相同即可。
-
最后是使用caffe的工具将fine-tuning的网络跑起来进行训练。
下面是对微调过程中出现的情况的举例说明
-
用lenet模型时,图片通道数不一样,lenet使用一通道,我们的图片是rgb三通道。这个就需要改变这个第一层卷积的名字,与原始的conv1要不一样。
-
在进行微调时,当输入图片大小不一样时,全连接的第一层名字没有进行修改,进入全连接层的参数不一样,需要重新命名,需要修改第一层全连接的名字。
7.1.4 实践建议
-
预训练模型的限制。使用预训练模型,受限于其网络架构。例如,你不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小图像;卷积层和池化层对输入数据大小没有要求(只要步长stride fit),其输出大小和属于大小相关;全连接层对输入大小没有要求,输出大小固定。
-
学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。
参考:Fine-tuning
7.2 Inception V4
Going deeper with convolutions
Inception-v4, Inception-ResNet andthe Impact of Residual Connections on Learning

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)