【Mo 人工智能技术博客】激活函数(一)浅谈激活函数以及其发展
【专栏2】激活函数(一)浅谈激活函数以及其发展激活函数是神经网络的相当重要的一部分,在神经网络的发展史上,各种激活函数也是一个研究的方向。我们在学习中,往往没有思考过——为什么用这个函数以及它们是从何而来?浅谈激活函数以及其发展
激活函数是神经网络的相当重要的一部分,在神经网络的发展史上,各种激活函数也是一个研究的方向。我们在学习中,往往没有思考过——为什么用这个函数以及它们是从何而来?
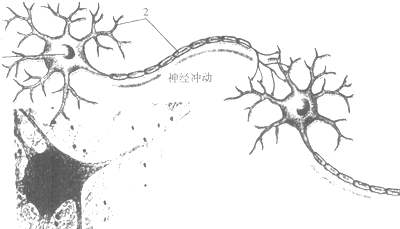
生物神经网络曾给予了人工神经网络相当多的启发。如上图,来自树突信号不断累积,如若信号强度超过一个特定阈值,则向轴突继续传递信号。如若未超过,则该信号被神经元“杀死”,无法继续传播。
在人工神经网络之中,激活函数有着异曲同工之妙。试想,当我们学习了一些新的东西之后,一些神经元会产生不同的输出信号,这使得神经元得以连接。
sigmoid函数也许是大家初学神经网络时第一个接触到的激活函数,我们知道它有很多良好的特性,诸如能将连续的实值变换为0到1的输出、求导简单,那么这个函数是怎么得到的呢?本文从最大熵原理提供一个角度。
1 sigmoid函数与softmax函数
1.1 最大熵原理与模型
最大熵原理是概率模型学习的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型中,熵最大的模型是合适的模型。
假设离散随机变量 X X X的概率分布是 P ( X ) P(X) P(X),则其熵是
H ( P ) = − ∑ x P ( x ) log P ( x ) H(P)=-\sum_{x}P(x)\log P(x) H(P)=−∑xP(x)logP(x)
熵满足下列不等式:
0 ⩽ H ( P ) ⩽ log ∣ X ∣ 0\leqslant H(P)\leqslant \log |X| 0⩽H(P)⩽log∣X∣
式中, ∣ X ∣ |X| ∣X∣是 X X X的取值个数,当且仅当 X X X的分布是均匀分布时右边的等号成立。这就是说,当 X X X服从均匀分布时,熵最大。
直观而言,此原理认为要选择的概率模型首先必须满足已有的条件,在无更多信息的条件下没其他不确定的部分都是等可能的。
假设分类模型是一个条件概率分布 P ( Y ∣ X ) P(Y\mid X) P(Y∣X),给定一个训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},可以确定 P ( X , Y ) P(X, Y) P(X,Y)的经验分布和边缘分布 P ( X ) P(X) P(X)的经验分布,分别以 P ~ ( X , Y ) \tilde{P}(X,Y) P~(X,Y)和 P ~ ( X ) \tilde{P}(X) P~(X)表示。
用特征函数(feature function) f ( x , y ) f(x,y) f(x,y)描述输入 x x x和$y
$之间的某一个事实,定义为:
f ( x , y ) = { 1 , x 与 y 满足某一事实 0 , 否则 f(x, y)=\left\{\begin{array}{ll} 1, & x \text { 与 } y \text { 满足某一事实 } \\ 0, & \text { 否则 } \end{array}\right. f(x,y)={1,0,x 与 y 满足某一事实 否则
由上述信息,可以假设 f ( x , y ) f(x,y) f(x,y)关于经验分布 P ~ ( X , Y ) \tilde{P}(X,Y) P~(X,Y)的期望值和关于模型 P ( Y ∣ X ) P(Y\mid X) P(Y∣X)与经验分布 P ~ ( X ) \tilde{P}(X) P~(X)的期望值相等,即:
∑ x , y P ~ ( x , y ) f i ( x , y ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) \sum{x, y} \tilde{P}(x, y) f{i}(x, y)=\sum{x, y} \tilde{P}(x) P(y \mid x) f{i}(x, y) ∑x,yP~(x,y)fi(x,y)=∑x,yP~(x)P(y∣x)fi(x,y)
结合条件,该问题等价于约束最优化问题:
min P ∈ C − H ( P ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) s.t. E P ( f i ) = E P ~ ( f i ) , i = 1 , 2 , ⋯ , n ∑ y P ( y ∣ x ) = 1 \begin{aligned} &\min _{P \in \mathbf{C}} - H(P)=\sum_{x, y} \tilde{P}(x) P(y \mid x) \log P(y \mid x)\\ \text { s.t. } &\quad E_{P}\left(f_{i}\right)=E_{\tilde{P}}\left(f_{i}\right), \quad i=1,2, \cdots, n\\ &\sum_{y} P(y \mid x)=1 \end{aligned} s.t. P∈Cmin−H(P)=x,y∑P~(x)P(y∣x)logP(y∣x)EP(fi)=EP~(fi),i=1,2,⋯,ny∑P(y∣x)=1
由拉格朗日乘子法,问题转换为求如下式子的最小值
KaTeX parse error: {equation} can be used only in display mode.
此时,我们对 L L L求 P ( Y ∣ X ) P(Y|X) P(Y∣X)的导数:
∂ L ∂ P ( y ∣ x ) = ∑ x , y P ~ ( x ) ( log P ( y ∣ x ) + 1 ) − ∑ x , y w 0 + ∑ i w i ( x ) P ~ ( x ) f i ( x , y ) = ∑ x , y P ~ ( x ) ( ( log P ( y ∣ x ) + 1 ) − w 0 + ∑ i w i ( x ) f i ( x , y ) ) \begin{aligned} \frac{\partial{L}}{\partial P(y \mid x)} &=\sum_{x,y}\tilde{P}(x)(\log P(y \mid x)+1)-\sum_{x,y}w_{0}+\sum_{i} w_{i}(x) \tilde{P}(x) f_{i}(x, y) \\ &=\sum_{x,y}\tilde{P}(x)\left((\log P(y \mid x)+1)-w_{0}+\sum_{i} w_{i}(x) f_{i}(x, y)\right) \end{aligned} ∂P(y∣x)∂L=x,y∑P~(x)(logP(y∣x)+1)−x,y∑w0+i∑wi(x)P~(x)fi(x,y)=x,y∑P~(x)((logP(y∣x)+1)−w0+i∑wi(x)fi(x,y))
令其导数值为0,在 P ~ ( X ) > 0 \tilde{P}(X) > 0 P~(X)>0的情况下,解得:
P ( y ∣ x ) = exp ( ∑ i = 1 n w i f i ( x , y ) + w 0 − 1 ) P(y\mid x)= \exp \left( \sum_{i=1}^{n} w_if_i(x,y)+w_0-1 \right) P(y∣x)=exp(∑i=1nwifi(x,y)+w0−1)
由于 ∑ y P ( y ∣ x ) = 1 \sum_{y}P(y\mid x)=1 ∑yP(y∣x)=1,得:
∑ y P ( y ∣ x ) = ∑ y exp ( ∑ i = 1 n w i f i ( x , y ) + w 0 − 1 ) = ∑ y exp ( ∑ i = 1 n w i f i ( x , y ) ) exp ( 1 − w 0 ) = 1 \begin{aligned} \sum_{y}P(y\mid x) &= \sum_{y}\exp \left( \sum_{i=1}^{n} w_if_i(x,y)+w_0-1 \right) \\ &=\frac{\sum_{y}\exp \left( \sum_{i=1}^{n} w_if_i(x,y) \right)}{\exp(1-w_0)} = 1 \end{aligned} y∑P(y∣x)=y∑exp(i=1∑nwifi(x,y)+w0−1)=exp(1−w0)∑yexp(∑i=1nwifi(x,y))=1
由上面两式可得:
P ( y ∣ x ) = e − ∑ i w i f i ( x , y ) ∑ y e − ∑ i w i f i ( x , y ) P(y \mid x)=\frac{e^{-\sum_{i} w_{i} f_{i}(x, y)}}{\sum_{y} e^{-\sum_{i} w_{i} f_{i}(x, y)}} P(y∣x)=∑ye−∑iwifi(x,y)e−∑iwifi(x,y)
细心的同学不难发现,这和softmax函数十分相近,定义 f i ( x , y ) = x f_i(x,y)=x fi(x,y)=x,即可得到softmax函数:
P ( y ∣ x ) = e − ∑ i w i x ∑ y e − ∑ i w i x P(y \mid x)=\frac{e^{-\sum_{i} w_{i} x}}{\sum_{y} e^{-\sum_{i} w_{i} x}} P(y∣x)=∑ye−∑iwixe−∑iwix
那么sigmoid函数呢?其实该函数就是softmax函数的二分类特例:
P ( y = 1 ∣ x ) = 1 1 + e ∑ i w i x P(y=1 \mid x)=\frac{1}{1+e^{\sum_{i} w_{i} x}} P(y=1∣x)=1+e∑iwix1
说完了推导,就来谈谈这两函数的特点。sigmoid函数的优点前文已提到,但sigmoid在反向传播时容易出现“梯度消失”的现象。
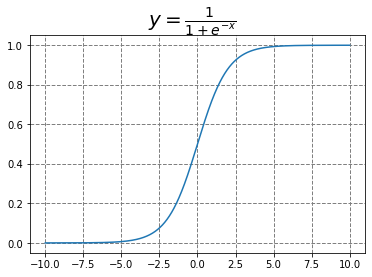
可以看出,当输入值很大或很小时,其导数接近于0,它会导致梯度过小无法训练。
2 ReLU函数族的崛起
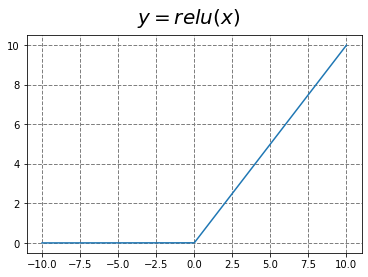
如图所示,ReLU函数很好避免的梯度消失的问题,与Sigmoid/tanh函数相比,ReLU激活函数的优点是:
- 使用梯度下降(GD)法时,收敛速度更快 。
- 相比ReLU只需要一个门限值,即可以得到激活值,计算速度更快 。
缺点是: ReLU的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。
为了解决ReLU函数这个缺点,又出现了不少基于ReLU函数的发展,比如Leaky ReLU(带泄漏单元的ReLU)、 RReLU(随机ReLU)等等,也许你有一天也能发现效果更好的ReLU函数呢!
引用
[1] [李航. 统计学习方法[M]. 清华大学出版社, 2012.]
欢迎关注我们的微信公众号:MomodelAI
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)