【多模态】一次多模态大模型表格识别解析探索小实践记录
训练数据质量大于一切,含大量数据的超长文本表格目前还不能准确识别,因为笔者训练的是。作为文档智能的重要组成部分,面临着复杂结构和多样化格式的挑战。前期文章也介绍了传统视觉的方法进行表格结构识别的方法,国庆期间,笔者利用一个较长的时间段,训练了一个。模型,效果还不错,特此记录一下多模态的效果。下面的一些case来源于网络的表格截图。关于表格识别在这里就不做过多的介绍了。模型参数量目前较大,推理速度比
·
表格识别作为文档智能的重要组成部分,面临着复杂结构和多样化格式的挑战。
《【文档智能 & RAG】RAG增强之路:增强PDF解析并结构化技术路线方案及思路》,
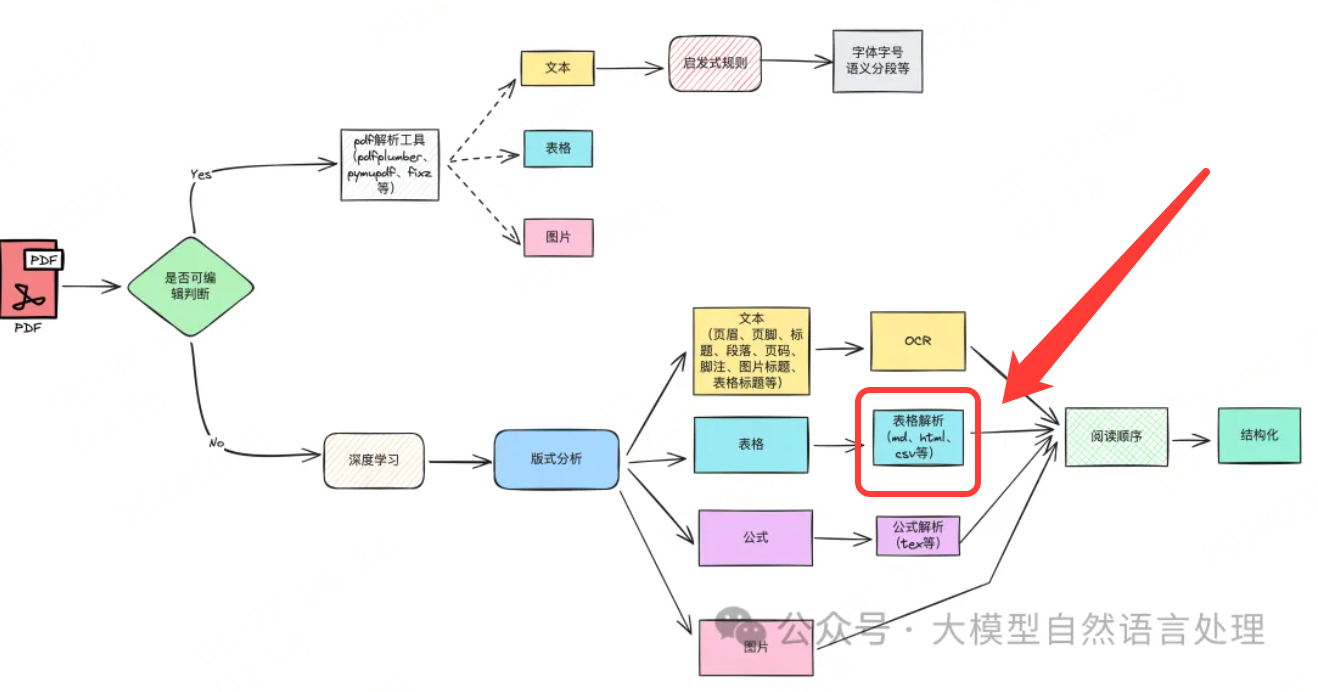
前期文章也介绍了传统视觉的方法进行表格结构识别的方法,【文档智能】轻量级级表格识别算法模型-SLANet
关于表格识别在这里就不做过多的介绍了。
国庆期间,笔者利用一个较长的时间段,训练了一个多模态的表格识别模型,效果还不错,特此记录一下多模态的效果。
- 训练资源:H100*8
- 训练数据:200w table image - table html对(html的表示表格的优势,可以准确表示一些复杂表格,如合并单元格等,这点是mardown格式无法做到的。)
- 模型参数量:7B
- 自建测评数据TEDS:0.97~0.98
小总结:
-
训练数据质量大于一切,含大量数据的超长文本表格目前还不能准确识别,因为笔者训练的是
max-length=8192。 -
模型参数量目前较大,推理速度比较慢。
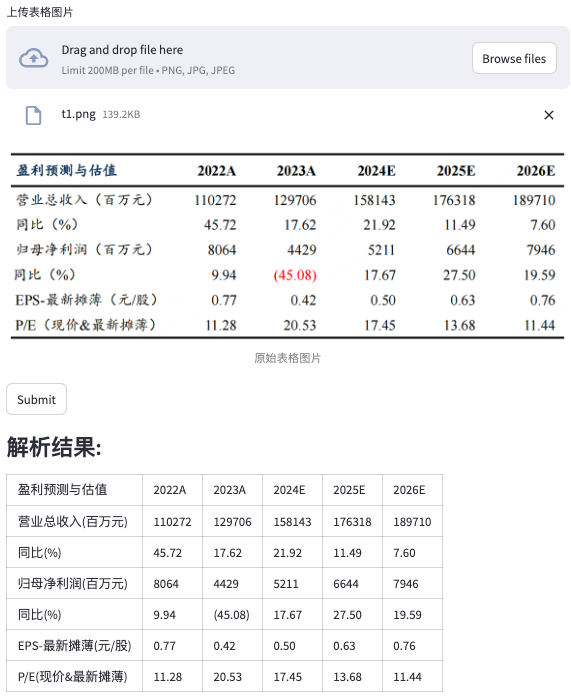
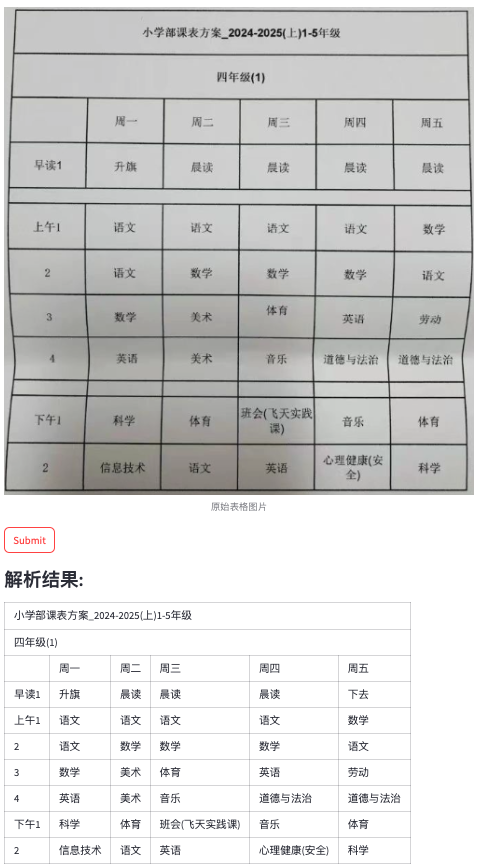
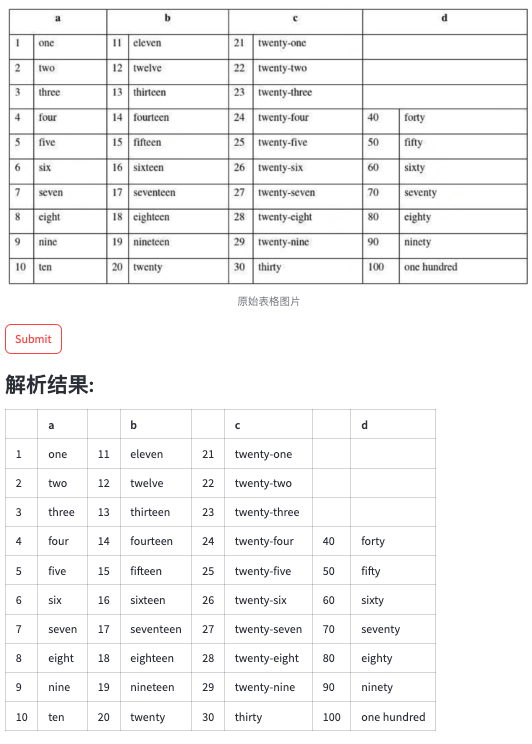
效果记录:
下面的一些case来源于网络的表格截图。
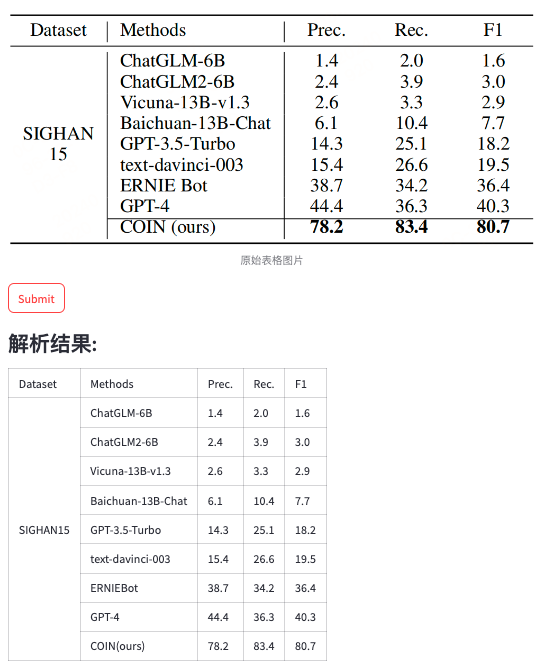
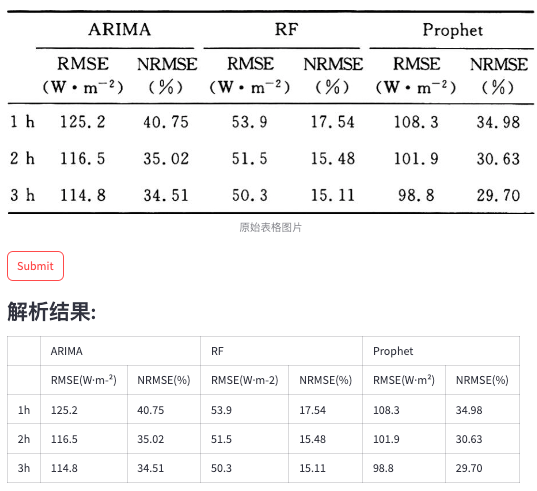
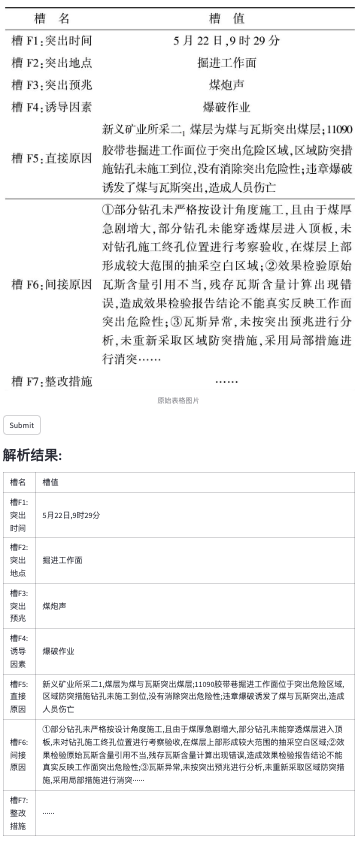


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)