《机器学习》读书笔记:总结“第3章线性模型”中的概念
总结“第3章线性模型”中的概念
💠线性模型(linear model)
线性模型(linear model) 试图学得一个通过属性的线性组合来进行预测的函数,即:
f(x)=w1x1+w2x2+...+wdxd+b f(\bold{x})=w_1x_1+w_2x_2+...+w_dx_d+b f(x)=w1x1+w2x2+...+wdxd+b
向量形式写为:
f(x)=wTx+b f(\bold{x})=\bold{w}^T\bold{x}+b f(x)=wTx+b
w\bold{w}w 和 bbb 学得后,模型就得以确定。
线性模型简单。但许多更为强大的 非线性模型(nolinear model) 是在线性模型上引入层级结构或高维映射而得。
此外,因为w\bold{w}w比较直观,所以线性模型拥有很好的可解释性/可理解性。
💠属性值的 序(order) 关系
对于离散的属性:
- 如果存在 “序(order)” 关系,则可将离散的值转化为连续的值。例如“高”和“矮”可转换为 1.0 和 0.0。
- 如果不存在 “序(order)” 关系,则通常转换为k维向量。例如“西瓜”、“南瓜”、“黄瓜”可转换为(0,0,1)、(0,1,0)、(1,0,0)。
💠线性回归(linear regression)
给定数据集D={(x1,y1),(x2,y2),...,(xm,ym)}D=\{(\bold{x}_1,y_1),(\bold{x}_2,y_2),...,(\bold{x}_m,y_m)\}D={(x1,y1),(x2,y2),...,(xm,ym)},其中xi=(xi1;xi2;...;xid)\bold{x}_i=(x_{i1};x_{i2};...;x_{id})xi=(xi1;xi2;...;xid),yi∈Ry_i\in\mathbb{R}yi∈R。
“线性回归(linear regression)” 试图学得:
f(xi)=wTxi+bf(\bold{x}_i)=\bold{w}^T\bold{x}_i+bf(xi)=wTxi+b 使得 f(xi)≃yif(\bold{x}_i)\simeq y_if(xi)≃yi
如果xi\bold{x}_ixi中有多个属性,那么就称为“多元线性回归(multivariate linear regression)”
为便于观察,我们把线性回归模型简写为:
y=wTx+b y=\bold{w}^T\bold{x}+b y=wTx+b
💠对数线性回归(log-linear regression)
假设示例所对应的输出标记是在指数尺度上变化,即:
lny=wTx+b \ln y=\bold{w}^T\bold{x}+b lny=wTx+b
就是 对数线性回归(log-linear regression),实际上是试图让 ewTx+be^{\bold{w}^T\bold{x}+b}ewTx+b 逼近 yyy 。
💠广义线性模型(generalized linear model)
考虑单调可微函数 g(⋅)g(\cdot)g(⋅),令
y=g−1(wTx+b) y = g^{-1}(\bold{w}^T\bold{x}+b) y=g−1(wTx+b)
这样得到的模型称为 广义线性模型(generalized linear model)。其中函数g(⋅)g(\cdot)g(⋅)称为“联系函数(link function)”。
显然,对数线性回归是 g(⋅)=ln(⋅)g(\cdot)=\ln (\cdot)g(⋅)=ln(⋅) 时的特例。
💠对数几率回归(logistic regression)
若要做分类任务,该怎么办?根据广义线性模型:需要找一个单调可微函数将标记与预测值联系起来。
考虑二分类任务,其输出标记 y∈{0,1}y\in\{0,1\}y∈{0,1} 而线性回归模型产生的预测值 z=wTx+bz=\bold{w}^T\bold{x}+bz=wTx+b。于是需要将zzz转换为0/1。此时最理想的函数是 “单位阶跃函数”
y={0,z<00.5,z=01,z>0 y= \begin{cases} 0, & z<0 \\ 0.5, & z=0 \\ 1, & z>0 \end{cases} y=⎩
⎨
⎧0,0.5,1,z<0z=0z>0
但是,单位阶跃函数是不连续的(所以不“可微”),因此不能作为联系函数。
而 “对数几率函数(logistic function)” 正是这样一个常用的替代函数:
y=11+e−z y=\frac{1}{1+e^{-z}} y=1+e−z1
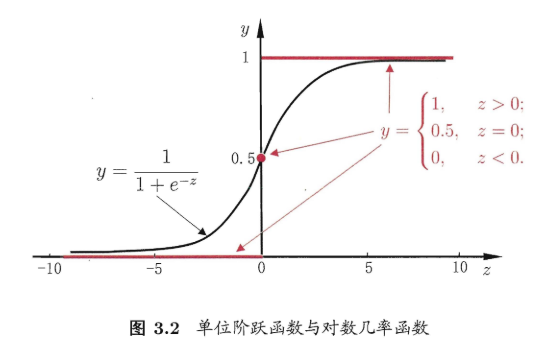
需要注意,他的名字是“回归”,但实际却是一种“分类”。
💠线性判别分析(LDA)
线性判别分析 Linear Discriminant Analysis,简称LDA。(亦称为Fisher判别分析)
LDA的思想:
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离。这样,在对新样本进行分类的时候,就可以通过投影到这条直线上来判定类别。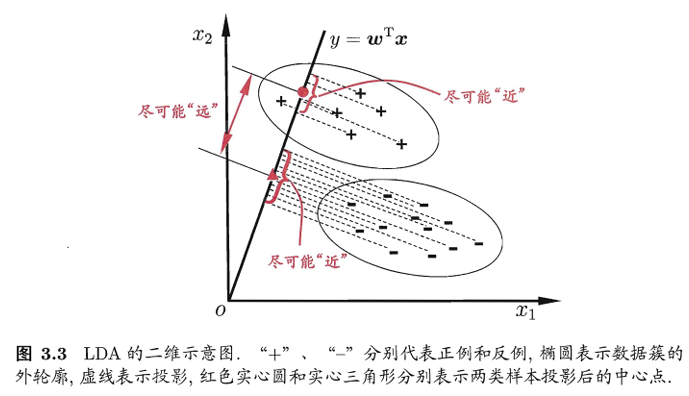
💠多分类学习
考虑NNN个类别 C1,C2,...,CNC_1,C_2,...,C_NC1,C2,...,CN。多分类学习任务是 “拆解法”,即拆分成若干个二分类任务。最经典的拆分策略有三种:
💠一对一(One vs One,简称OvO)
OvO:将NNN个类别两两配对,训练得到N(N−1)2\frac{N(N-1)}{2}2N(N−1)个分类器。
最终预测结果由投票产生。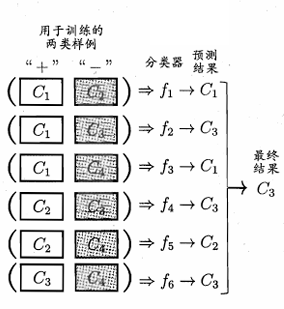
💠一对其余(One vs Rest,简称OvR)
OvR:每次将一个类的样例作为正例,其余作为反例,训练得到NNN个分类器。
预测时,若仅有一个分类器fif_ifi预测为正例,其余为反例,则CiC_iCi就是最终分类结果。(若有多个分类器预测为正类,则选择置信度最大的)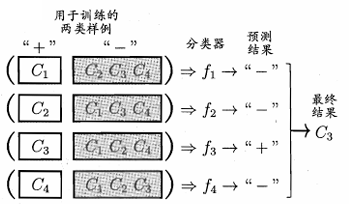
OvO 与 OvR 比较:
- OvO存储开销和测试时间比OvR更大
- OvO的训练开销更小
- 预测性能差不多
💠多对多(Many vs Many,简称MvM)
MvM:每次将若干个类作为正类,若干个其他类作为反类。
显然OvO和OvR都是MvM的特例。
MvM 的正、反类构造必须有特殊的设计,不能随意选取。
一种最常用的MvM技术是"纠错输出码" (Error Correcting Output Codes,简称 ECOC)。
💠纠错输出码(ECOC)
ECOC分为两步:
- 编码时:对NNN个类别做MMM次划分, 每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集。这样一共产生MMM个训练集,可训练出MMM个分类器(f1,f2,...,fmf_1,f_2,...,f_mf1,f2,...,fm)
- 解码时(预测时)::M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中 “距离最小的”(相当于最相似的)类别作为最终预测结果。
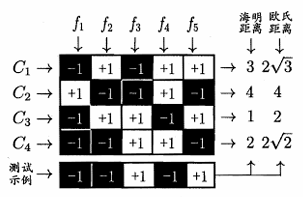
上图里C3C_3C3的距离最小(相当于测试样本的表现与C3C_3C3最接近)所以最终预测结果为C3C_3C3
💠二元码 和 三元码
上图是二元码,即每个类别分别指定为“正类”和“反类”。
还有三元码,即除了“正类”、“反类”之外,还有“停用类”,即表示fif_ifi不使用该类样本。
💠类别不平衡问题(class-imbalance)
类别不平衡(class-imbalance)指:不同类别的训练样例数目差别很大的情况,比如正例数目远小于反例。这会对学习过程造成困扰。
基本策略就是 再缩放(rescaling)。
现有技术大体有三种做法:
💠欠采样(undersampling)
去除一些反例使得正反例数目接近。
但是若随机丢弃反例可能会丢失信息。所以可以将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。(EasyEnsemble [Liu et al., 2009] )
💠过采样(oversamplling)
增加一些正例。
但是不能简单重复采样,否则会造成严重的“过拟合”。为此可以对正例进行插值来产生额外的正例(SMOTE [Chawla et al., 2002])
💠阈值移动(oversamplling)
直接基于原始训练集进行学习。但是决策过程时移动阈值。
即原先是:
若y1−y>1则预测为正例 若\frac{y}{1-y}>1则 预测为正例 若1−yy>1则预测为正例
移动阈值后是:
若y1−y>m+m−则预测为正例 若\frac{y}{1-y}>\frac{m^+}{m^-}则 预测为正例 若1−yy>m−m+则预测为正例
(其中m+m^+m+为正例数目,m−m^-m−为反例数目)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)