机器学习实战——K-近邻算法
K-近邻算法(K-Nearest Neighbor),顾名思义,即选取最接近的数据进行分类的一种算法,它采用测量不同特征值之间的距离方法来进行分类。工作原理:存在一个样本数据集(训练样本集),并且样本集中的每一个数据都存在标签,即我们知道样本集中每一项数据与所属分类的对应关系,在输入没有标签的新数据时,将新数据的每个特征与样本集中数据对应的特征进行比较,最后根据算法提取样本集中最相似数据(最近邻)
[原发布时间:2021-09-30 20:54:56]
K-近邻算法
1. 概述
K-近邻算法(K-Nearest Neighbor),顾名思义,即选取最接近的数据进行分类的一种算法,它采用测量不同特征值之间的距离方法来进行分类。
工作原理:存在一个样本数据集(训练样本集),并且样本集中的每一个数据都存在标签,即我们知道样本集中每一项数据与所属分类的对应关系,在输入没有标签的新数据时,将新数据的每个特征与样本集中数据对应的特征进行比较,最后根据算法提取样本集中最相似数据(最近邻)的分类标签。
2. 算法分析
例如我们有如下关于水果的数据和相关标签(分类):
| 水果种类 | 形状大小 | 颜色 |
|---|---|---|
| 芒果 | 1 | 3 |
| 苹果 | 2 | 4 |
| 西瓜 | 4 | 2 |
| 哈密瓜 | 6 | 3 |
问题:如果有一种水果,知道它的形状大小(3)和颜色(7),那怎样对其进行分类呢?
首先将如上数据使用Matplotlib画出二维扩散图: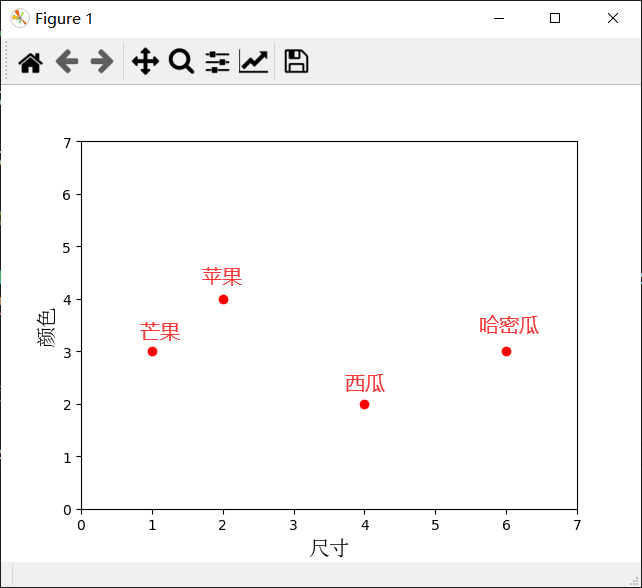
随后将未知水果的形状大小和颜色的数据也放到二维扩散图中: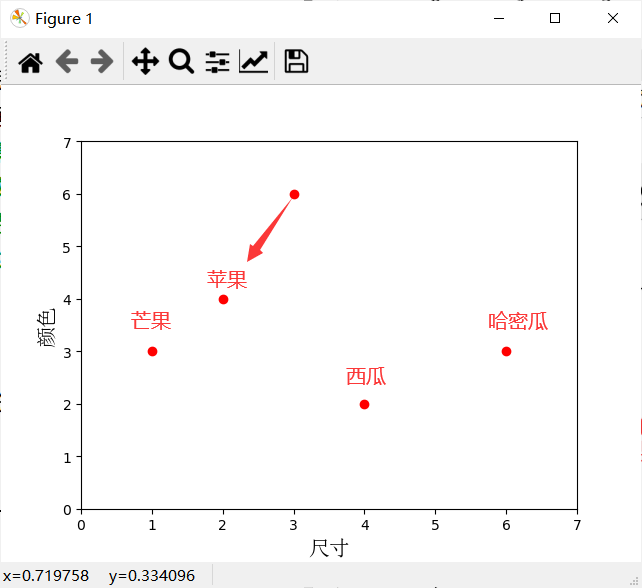
根据上图,根据距离可直观判断该未知类名的水果离苹果最为接近,因此可将该水果近似归类为苹果。
如上的归类过程便是K-近邻算法的大致工作原理,在实际计算两个向量点xA和xB的距离时使用欧式距离公式进行计算: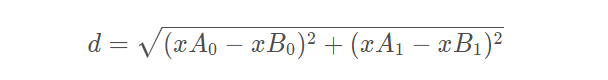
计算流程如下: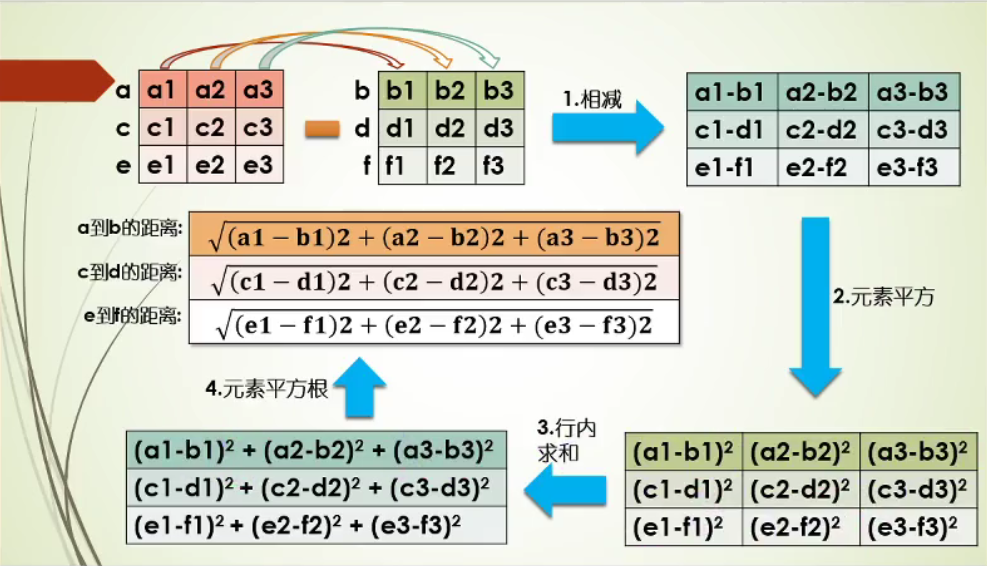
3. 代码实现
from numpy import *
import operator
#-------------------------------------------#
# 创建(训练)数据集
#------------------------------------------#
def createDataSet():
group = array([[1, 3], [2, 4], [4, 2],[6, 3]])
labels = ['芒果','苹果', '西瓜', '哈密瓜']
return group, labels
#------------------------------------------#
# 分类器
# 输出:待分类数据的类别
#------------------------------------------#
def classify(inX, dataSet, labels, k):
#------------------------------------------#
# 获取训练样本的行数(样本数),若获取列数,
# 则为shape[1],shape(数组)属性中包含了行数和列数
# -----------------------------------------#
dataSetSize = dataSet.shape[0]
#----------------------------------------------------------------#
# numpy.tile() 函数用于扩展数组,这里表示 inX 被重复(扩展)了 dataSetSize
# 行和 1 列,并进行矩阵的减法运算
# --------------------------------------------------------------#
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
#特征差值的平方(结果仍为矩阵)
sqDiddMat = diffMat**2
#矩阵每行行内求和,变为多行一列
sqDistances = sqDiddMat.sum(axis=1)
#矩阵求平方根,得到输入向量与每个训练样本中点的欧式距离
distances = sqDistances**0.5
#将距离结果按照从小到大排序返回索引值(下标)
sorteDistIndicies = distances.argsort()
#----------------------------------------#
# 用字典做类别计数器,key:类别,value:距离,
# {key: value} 键值对的数量取前 k 个
#----------------------------------------#
classcount={}
#----------------------------------------#
# 遍历前k个样本
# ---------------------------------------#
for i in range(k):
# 获取距离最小的前k个样本点对应的 label 值
voteIlabel = labels[sorteDistIndicies[i]]
#-----------------------------------------------#
# 为该类别的计数器加 1,指定的 key 不在字典中时返回 0
# ----------------------------------------------#
classcount[voteIlabel] = classcount.get(voteIlabel,0)+1
#--------------------------------------------------------------------------------------------------#
# 根据计数的数量进行降序排序
# list = sorted(iterable, key=None, reverse=False)。key 参数可以自定义排序规则(即选择第几维的数据进行排列)。
# operator.itemgetter(1): 表示选择 "value" 字段进行排序
# operator.itemgetter(0): 表示选择 "key" 字段进行排序
# sorted(字典) 默认选择 "key" 排序,但是返回的结果会变成只有 "key" 值的列表。items() 方法把字典中每对 key 和
# value 组成一个元组,并把这些元组放在列表中返回。
# sorteClassCount: dict_items([('苹果', 1), ('芒果', 1), ('哈密瓜', 1)])
#--------------------------------------------------------------------------------------------------#
sorteClassCount = sorted(classcount.items(), key=operator.itemgetter(0), reverse=True)
print(sorteClassCount)
return sorteClassCount[0][0]
if __name__ == "__main__":
group,labels = createDataSet()
result = classify([3, 7], group, labels, 3)
print(result)
输出结果:
苹果
其中calssify()函数的四个参数分别为:用于分类的输入向量inX,训练样本集dataSet,标签向量labels,选择最邻近邻居的数量k(确定k个与当前点距离最近的点,并将出现频率最高的类作为当前点的预测分类)。
4. 总结
本例中的训练数据取值相对简单且未经过对应的数据处理,一般来说,实际中的KNN算法使用的训练集都是标准数据的导入和分类,这能大大提升算法识别的准确率。本次的算法学习由于刚接触python编程,因此对很多相关语法还不够了解导致出错,希望通过后面的不断学习来完善不足之处。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)