NLP自然语言处理之Word2Vec(二)CBOW 加层次的网络结构
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言前言一、CBOW 加层次的网络结构二、优化目标与解问题前言本文主要记录了Word2Vec中CBOW加层次的网络结构的学习笔记,如有错误还请不吝赐教!本文参考:北流浪子大佬的文章提示:以下是本篇文章正文内容,下面案例可供参考前言Word2vec总共有两种类型,每种类型有两个策略,总共 4 种。这里先说最常用的一种,CBOW加
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本文主要记录了Word2Vec中CBOW加层次的网络结构的学习笔记,如有错误还请不吝赐教!
本文参考:北流浪子大佬的文章
提示:以下是本篇文章正文内容,下面案例可供参考
前言
Word2vec总共有两种类型,每种类型有两个策略,总共 4 种。这里先说最常用的一种,CBOW加层次化网络结构。
一、CBOW 加层次的网络结构
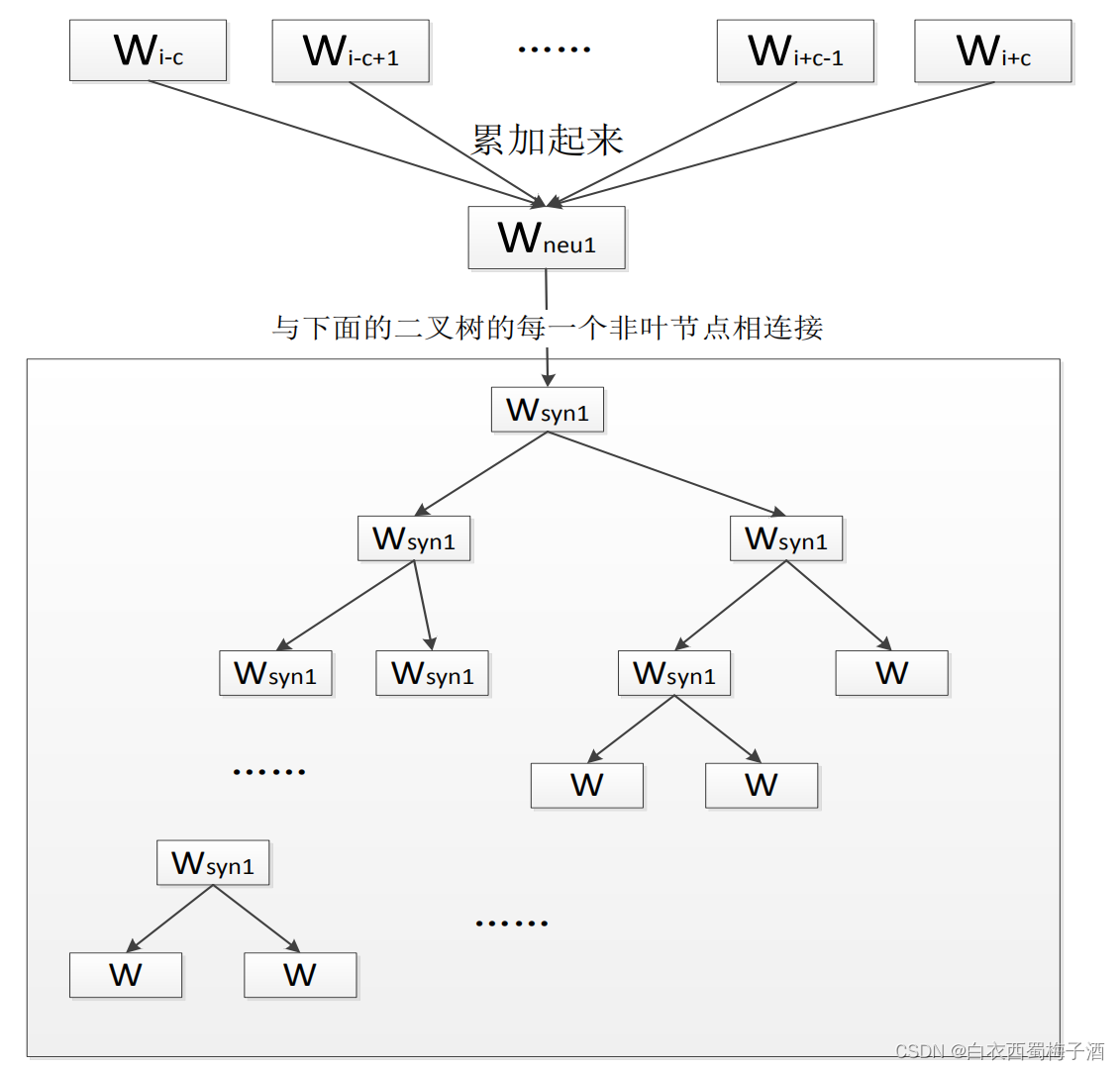
其中第一层,也就是最上面的那一层可以称为输入层。输入的是若干个词的词向量(词向量的意思就是把一个词表示成一个向量的形式表达,后面会介绍)。中间那个层可以称为隐层,是输入的若干个词向量的累加和,注意是向量的累加和,结果是一个向量。
第三层是方框里面的那个二叉树,可以称之为输出层,第三层的这个二叉树是一个霍夫曼树,每个非叶节点也是一个向量,但是这个向量不代表某个词,代表某一类别的词;每个叶子节点代表一个词向量。
需要注意的是:输入的几个词向量其实跟这个霍夫曼树中的某几个叶子节点是一样的,当然输入的那几个词跟它们最终输出的到的那个词未必是同一个词,而且基本不会是同一个词,只是这几个词跟输出的那个词往往有语义上的关系。
还有要注意的是,这个霍夫曼树的所有叶子节点就代表了语料库里面的所有词,而且是每个叶子节点对应一个词,不重复。
这个网络结构的功能是为了完成一个的事情——判断一句话是否是自然语言。怎么判断呢?使用的是概率,就是计算一下这句话的“一列词的组合”的概率的连乘(联合概率)是多少,如果比较低,那么就可以认为不是一句自然语言,如果概率高,就是一句正常的话。这个其实也是语言模型的目标。前面说的“一列词的组合”其实包括了一个词跟它的上下文的联合起来的概率,一种普通的情况就是每一个词跟它前面所有的词的组合的概率的连乘,这个后面介绍。
对于上面的那个网络结构来说,网络训练完成后,假如给定一句话 s,这句话由词w1,w2,w3,„,wT 组成,就可以利用计算这句话是自然语言的概率了,计算的公式是下面的公式: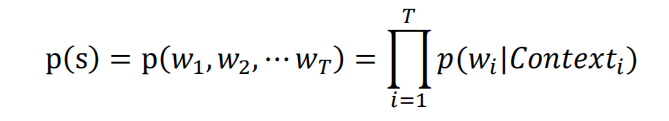
其中Contexti 为该词的上下文,也就是这个词的前面和后面各若干个词。
𝑝(𝑤𝑖|𝐶𝑜𝑛𝑡𝑒𝑥𝑡𝑖)代表的意义是前后的 c 个词分别是那几个的情况下,出现该词的概率。
举个例子就是:“大家 喜欢 吃 好吃 的 苹果”这句话总共 6 个词,假设对“吃”这个词来说 c 随机抽到 2,则“吃”这个词的 context 是“大家”、“喜欢”、“好吃”和“的”,总共四个词,这四个词的顺序可以乱,这是 word2vec 的一个特点。
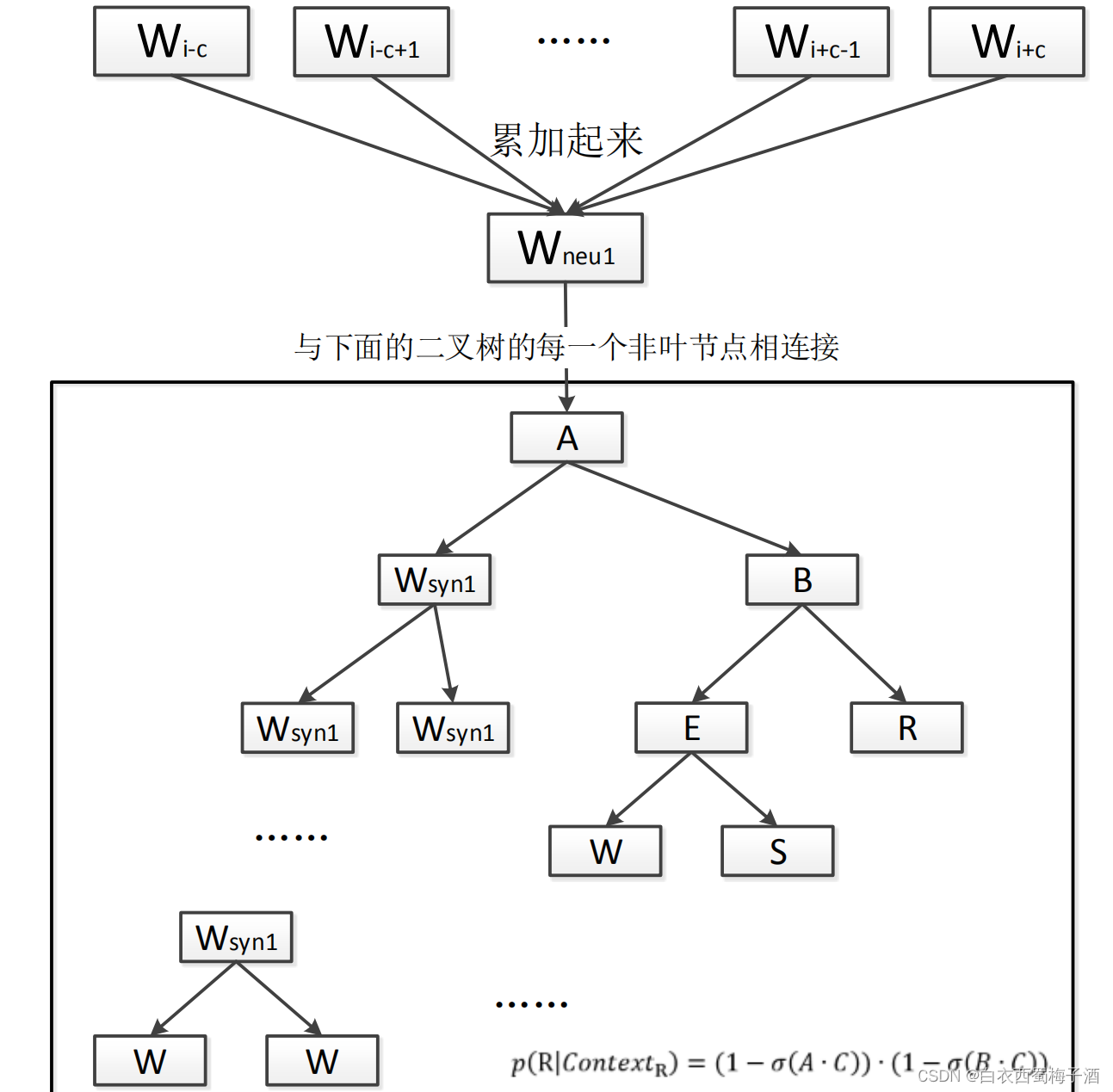
计算𝑝(𝑤𝑖|𝐶𝑜𝑛𝑡𝑒𝑥𝑡𝑖)的时候都要用到上面的那个网络,具体计算的方法用例子说明,假设就是计算“吃”这个词的在“大家”、“喜欢”、“好吃”和“的”这四个词作为上下文的条件概率,又假设“吃”这个词在霍夫曼树中是的最右边那一个叶子节点(在下面的图中的节 点 R),那么从根节点到到达它就有两个非叶节点,根节点对应的词向量命名为 A,根节点的右孩子节点对应的词向量命名为 B,另外再假设“大家”、“喜欢”、“好吃”和“的”这四个词的词向量的和为 C,则
𝑝 (吃|𝐶𝑜𝑛𝑡𝑒𝑥𝑡吃) = (1 − 𝜎(𝐴 ∙ 𝐶)) ∙ (1 − 𝜎(𝐵 ∙ 𝐶))
同理:
如果“吃”是节点S,那么
𝑝 (吃|𝐶𝑜𝑛𝑡𝑒𝑥𝑡吃) = (1 − 𝜎(𝐴 ∙ 𝐶)) ∙ 𝜎(𝐵 ∙ 𝐶) ∙ (1 − 𝜎(𝐸 ∙ 𝐶))
类似的上述的损失函数可以使用最大似然估计的方式解决。
二、Skip-Gram(跳元模型)与Negative Sampling(负采样)
跳元模型与cbow区别在于,他是使用中心词来预测n个上下文,我们一般会考虑一个窗体大小的上下文,即中心词左边n个+中心词右边n个。
对应的层次softmax类似于之前所说的。这里重点讲一下Negative Sampling。
负采样,我们直观理解就是对于每个给定的center,我们从所有的词库中随机挑选k个词作为他的负样本的上下文。
具体挑选的概率可以参考论文中的方式。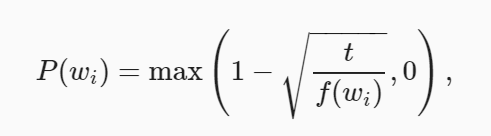
其中fw为词频,t为超参数,一般为10^-4。
通过极大似然的方式可以对Negative Sampling进行估计: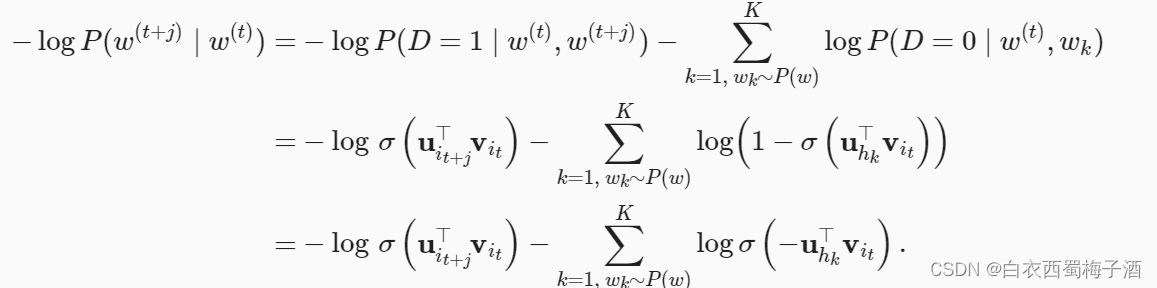
三、代码与实现
数据可见 提取码:1ikn
3.1 层次Softmax+Skip-Gram
Huffman 树:
from typing import List,Dict
import heapq
class HuffmanNode:
""" HuffmanNode """
def __init__(self,word_id,frequency:int):
self.word_id = word_id # 叶子结点存词对应的id, 中间节点存中间节点id
self.frequency = frequency # 存单词频次
self.left_child = None
self.right_child = None
self.father = None
self.Huffman_code = [] # 霍夫曼码(左1右0)
self.path = [] # 根到叶子节点的中间节点id
def __lt__(self, other):
return self.frequency < other.frequency
def __gt__(self, other):
return self.frequency > other.frequency
def __le__(self, other):
return self.frequency <=other.frequency
def __ge__(self, other):
return self.frequency >=other.frequency
class HuffmanTree:
""" Huffman Tree """
def __init__(self,wordid_frequency_dict:Dict):
"""
initialization
:param wordid_frequency_dict: the dict of the word_id and the word frequency
"""
self.word_count=len(wordid_frequency_dict)
self.wordid_code=dict()
self.wordid_path=dict()
self.root=None
# 未合并节点 list
unmerge_node_list=[HuffmanNode(wordid,frequency) for wordid ,frequency in wordid_frequency_dict.items()]
unmerge_node_list=sorted(unmerge_node_list,key=lambda x:x.frequency)
# storage the temp Node and the leaf Node
self.huffman=[HuffmanNode(wordid,frequency) for wordid, frequency in wordid_frequency_dict.items()]
# build the Huffman Tree
self._build_tree(unmerge_node_list)
# generate the code and the path
self.generate_huffman_code_and_path()
def _merge_node(self,node1:HuffmanNode,node2:HuffmanNode):
""" merge the node """
sum_frequency=node1.frequency+node2.frequency
mid_node_id=len(self.huffman)
father_node=HuffmanNode(mid_node_id,sum_frequency)
if node1.frequency >= node2.frequency:
father_node.left_child=node1
father_node.right_child=node2
else:
father_node.left_child=node2
father_node.right_child=node1
self.huffman.append(father_node)
return father_node
def _build_tree(self,node_list:List):
""" build the Huffman Tree """
while len(node_list)>1:
node1 = heapq.heappop(node_list)
node2 = heapq.heappop(node_list)
father_node=self._merge_node(node1,node2)
heapq.heappush(node_list,father_node)
self.root = node_list[0]
def generate_huffman_code_and_path(self):
stack = [self.root]
while len(stack) > 0:
node = stack.pop()
# 顺着左子树走
while node.left_child or node.right_child:
code = node.Huffman_code
path = node.path
node.left_child.Huffman_code = code + [1]
node.right_child.Huffman_code = code + [0]
node.left_child.path = path + [node.word_id]
node.right_child.path = path + [node.word_id]
# 把没走过的右子树加入栈
stack.append(node.right_child)
node = node.left_child
word_id = node.word_id
word_code = node.Huffman_code
word_path = node.path
self.huffman[word_id].Huffman_code = word_code
self.huffman[word_id].path = word_path
# 把节点计算得到的霍夫曼码、路径 写入词典的数值中
self.wordid_code[word_id] = word_code
self.wordid_path[word_id] = word_path
# 获取所有词的正向节点id和负向节点id数组
def get_all_pos_and_neg_path(self) -> object:
positive = [] # 所有词的正向路径数组
negative = [] # 所有词的负向路径数组
for word_id in range(self.word_count):
pos_id = [] # 存放一个词 路径中的正向节点id
neg_id = [] # 存放一个词 路径中的负向节点id
for i, code in enumerate(self.huffman[word_id].Huffman_code):
if code == 1:
pos_id.append(self.huffman[word_id].path[i])
else:
neg_id.append(self.huffman[word_id].path[i])
positive.append(pos_id)
negative.append(neg_id)
return positive, negative
def test():
word_frequency = {0: 4, 1: 6, 2: 3, 3: 2, 4: 2}
print(word_frequency)
tree = HuffmanTree(word_frequency)
print(tree.wordid_code)
print(tree.wordid_path)
for i in range(len(word_frequency)):
print(tree.huffman[i].path)
print(tree.get_all_pos_and_neg_path())
if __name__ == '__main__':
test()
Skip-Gram 模型:
import torch
import torch.nn as nn
import random
import math
import collections
import os
from typing import Dict
import torch.nn.functional as F
from Huffman import HuffmanTree
from torch.utils.data import Dataset,DataLoader
class SkipGramHierarchicalSoftmax(nn.Module):
def __init__(self,vocab_size:int,embed_size:int):
super(SkipGramHierarchicalSoftmax,self).__init__()
self.vocab_size=vocab_size
self.embed_size=embed_size
self.word_embedding=nn.Embedding(2*self.vocab_size-1,self.embed_size)
self.context_embedding=nn.Embedding(2*self.vocab_size-1,self.embed_size)
def forward(self,pos_target,pos_path,neg_target,neg_path):
pos_target_embedding = torch.sum(self.word_embedding(pos_target), dim=1, keepdim=True)
pos_path_embedding = self.context_embedding(pos_path)
pos_score = torch.bmm(pos_target_embedding, pos_path_embedding.transpose(2, 1)).squeeze()
neg_target_embedding = torch.sum(self.word_embedding(neg_target), dim=1, keepdim=True)
neg_path_embedding = self.context_embedding(neg_path)
neg_score = torch.bmm(neg_target_embedding, neg_path_embedding.transpose(2, 1)).squeeze()
pos_sigmoid_score = torch.lt(torch.sigmoid(pos_score), 0.5) # 判断正向路径是否正确
neg_sigmoid_score = torch.gt(torch.sigmoid(neg_score), 0.5) # 判断负向路径是否正确
sigmoid_score = torch.cat((pos_sigmoid_score, neg_sigmoid_score))
sigmoid_score = torch.sum(sigmoid_score, dim=0).item() / sigmoid_score.size(0)
return sigmoid_score
def loss(self,pos_target,pos_path,neg_target,neg_path):
pos_target_embedding = torch.sum(self.word_embedding(pos_target), dim=1, keepdim=True)
pos_path_embedding = self.context_embedding(pos_path)
pos_score = torch.bmm(pos_target_embedding, pos_path_embedding.transpose(2, 1)).squeeze()
neg_target_embedding = torch.sum(self.word_embedding(neg_target), dim=1, keepdim=True)
neg_path_embedding = self.context_embedding(neg_path)
neg_score = torch.bmm(neg_target_embedding, neg_path_embedding.transpose(2, 1)).squeeze()
pos_score = torch.sum(F.logsigmoid(-1 * pos_score))
neg_score = torch.sum(F.logsigmoid(neg_score))
loss = -1 * (pos_score + neg_score)
return loss
class Vocab:
def __init__(self,tokens=None,min_freq:int=10,reserved_tokens=None):
if tokens is None:
tokens=[]
if reserved_tokens is None:
reserved_tokens=[]
counter=count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def __len__(self):
return len(self.idx_to_token)
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # Index for the unknown token
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens):
""" count token frequencies"""
if len(tokens)==0 or isinstance(tokens[0],list):
tokens=[token for line in tokens for token in line]
return collections.Counter(tokens)
def read_ptb():
"""将PTB数据集加载到文本行的列表中"""
data_dir ="../../data/ptb"
# Readthetrainingset.
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')]
def subsample(sentences,vocab):
""" 下采样高频词 """
sentences=[[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
counter=count_corpus(sentences)
num_tokens=sum(counter.values())
def keep(token):
return random.uniform(0,1)<math.sqrt(1e-4/counter[token]*num_tokens)
return [[token for token in line if keep(token)] for line in sentences],counter
def get_centers_and_contexts(corpus,max_window_size):
"""return the center word and the context word for skip-gram"""
centers,contexts=[],[]
for line in corpus:
if len(line)<max_window_size:
continue
window_width = int(max_window_size // 2)
temp_centers=line[window_width:len(line)-window_width]
centers+=temp_centers
for i in range(len(temp_centers)):
index=i+window_width
indices=list(range(index-window_width,index+1+window_width))
# remove the index of the center word
indices.remove(index)
contexts.append([line[idx] for idx in indices])
return centers,contexts
class PTBDataset(Dataset):
def __init__(self,pos_target,neg_target,pos_path,neg_path):
self.pos_target=pos_target
self.neg_target=neg_target
self.pos_path=pos_path
self.neg_path=neg_path
def __getitem__(self, index):
return self.pos_target[index],self.neg_target[index],self.pos_path[index],self.neg_path[index]
def __len__(self):
return len(self.pos_target)
def shuffle(self):
indices=[i for i in range(len(self.pos_path))]
random.shuffle(indices)
self.shuffled_pos_target=[self.pos_target[i] for i in indices]
self.shuffled_neg_target=[self.neg_target[i] for i in indices]
self.shuffled_pos_path=[self.pos_path[i] for i in indices]
self.shuffled_neg_path=[self.neg_path[i] for i in indices]
# todo 批量填充,loss设置mask加权求和
def getBatch(self,num:int):
num_batch=len(self)//num+1
batch=[]
for i in range(num_batch):
batch.append([self.shuffled_pos_target[i*num:min(len(self.shuffled_pos_path),i*num+num)],
self.shuffled_neg_target[i * num:min(len(self.shuffled_pos_path), i * num + num)],
self.shuffled_pos_path[i * num:min(len(self.shuffled_pos_path), i * num + num)],
self.shuffled_neg_path[i * num:min(len(self.shuffled_pos_path), i * num + num)]
])
return batch
def collate_fn(batch):
pos_target=[i[0] for i in batch]
neg_target=[i[1] for i in batch]
pos_path=[i[2] for i in batch]
neg_path=[i[3] for i in batch]
return torch.as_tensor(pos_target),torch.as_tensor(neg_target),torch.as_tensor(pos_path),torch.as_tensor(neg_path)
def load_data_ptb(batch_size:int=128,max_window_size:int=5):
sentences = read_ptb()
vocab = Vocab(sentences, min_freq=10)
# 下采样高频词汇
subsampled, counter = subsample(sentences, vocab)
corpus = [vocab[line] for line in subsampled]
freq_dict = {}
for token, freq in vocab.token_freqs:
freq_dict[vocab[token]] = freq
freq_dict=dict(sorted(freq_dict.items(),key=lambda x:x[0]))
huffman=init_huffman(freq_dict)
positive,negative=huffman.get_all_pos_and_neg_path()
# 获得中心词汇以及对应的上下文词汇
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
pos_target=[]
neg_target=[]
pos_path=[]
neg_path=[]
for i in range(len(all_contexts)):
center=all_centers[i]
contexts=all_contexts[i]
temp_pos_target=[]
temp_pos_path=[]
temp_neg_target=[]
temp_neg_path=[]
for context in contexts:
positive_i=positive[context]
negative_i=negative[context]
temp_pos_target.extend(len(positive_i)*[center])
temp_pos_path.extend(positive_i)
temp_neg_target.extend(len(negative_i)*[center])
temp_neg_path.extend(negative_i)
pos_target.append(temp_pos_target)
neg_target.append(temp_neg_target)
pos_path.append(temp_pos_path)
neg_path.append(temp_neg_path)
dataset=PTBDataset(pos_target, neg_target,pos_path,neg_path)
return dataset,vocab,huffman
def init_huffman(wordid_frequency:Dict):
""" 初始化对应的huffman树 """
huffman=HuffmanTree(wordid_frequency)
return huffman
def train(epoches:int=10,lr:float=1e-3,embed_size:int=100,batch_size=1):
dataset,vocab,huffman=load_data_ptb()
dataset.shuffle()
batch=dataset.getBatch(batch_size)
vocab_size=len(huffman.huffman)
model=SkipGramHierarchicalSoftmax(vocab_size,embed_size)
optimizer=torch.optim.Adam(model.parameters(),lr=lr)
for epoch in range(epoches):
for data in batch:
optimizer.zero_grad()
pos_target,neg_target,pos_path,neg_path=data
pos_target=torch.as_tensor(pos_target)
neg_target=torch.as_tensor(neg_target)
pos_path=torch.as_tensor(pos_path)
neg_path=torch.as_tensor(neg_path)
loss=model.loss(pos_target,pos_path,neg_target,neg_path)
loss.backward()
optimizer.step()
break
if __name__=="__main__":
train()
3.2 Cbow+Negative Sampling
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
import collections
from d2l import torch as d2l
import os
import random
import math
import torch.nn.functional as F
class Vocab:
def __init__(self,tokens=None,min_freq:int=10,reserved_tokens=None):
if tokens is None:
tokens=[]
if reserved_tokens is None:
reserved_tokens=[]
counter=count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def __len__(self):
return len(self.idx_to_token)
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # Index for the unknown token
return 0
@property
def token_freqs(self): # Index for the unknown token
return self._token_freqs
def count_corpus(tokens):
""" count token frequencies"""
if len(tokens)==0 or isinstance(tokens[0],list):
tokens=[token for line in tokens for token in line]
return collections.Counter(tokens)
def read_ptb():
"""将PTB数据集加载到文本行的列表中"""
data_dir = d2l.download_extract('ptb')
# Readthetrainingset.
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')]
def subsample(sentences,vocab):
""" 下采样高频词 """
sentences=[[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
counter=count_corpus(sentences)
num_tokens=sum(counter.values())
def keep(token):
return random.uniform(0,1)<math.sqrt(1e-4/counter[token]*num_tokens)
return [[token for token in line if keep(token)] for line in sentences],counter
def get_centers_and_contexts(corpus,max_window_size):
"""return the center word and the context word for skip-gram"""
centers, contexts = [], []
for line in corpus:
if len(line) < max_window_size:
continue
window_width=int(max_window_size//2)
temp_centers=line[window_width:len(line)-window_width]
for i in temp_centers:
centers.append([i])
for i in range(len(temp_centers)):
index=i+window_width
indices = list(range(index-window_width, index +window_width+1))
# remove the index of the center word
indices.remove(index)
contexts.append([line[idx] for idx in indices])
return centers, contexts
class RandomGenerator:
"""根据n个采样权重在{1,...,n}中随机抽取"""
def __init__(self,sampling_weights):
self.population=list(range(1,len(sampling_weights)+1))
self.sampling_weights=sampling_weights
self.candidates=[]
self.i=0
def draw(self):
if self.i==len(self.candidates):
# 缓存k个随机采样结果
self.candidates=random.choices(self.population,self.sampling_weights,k=10000)
self.i=0
self.i+=1
return self.candidates[self.i-1]
def get_negatives(all_centers,vocab,counter,K):
"""返回负采样中的噪声词"""
# 设置采样概率: 根据word2vec论文中的建议,将噪声词 w 的采样概率 P(w) 设置为其在字典中的相对频率,其幂为0.75
sampling_weights = [counter[vocab.to_tokens(i)] ** 0.75
for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for centers in all_centers:
negatives = []
while len(negatives) < K:
neg = generator.draw()
# 噪声不能是中心词
if neg not in centers:
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
def collate_fn(data):
max_len = max(len(c) + len(n) for c, _, n in data)
centers_negatives, contexts, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(center) + len(negative)
for i in range(6):
contexts.append(context)
labels += [[1] * len(center) + [0] * (max_len - len(center))]
center+=negative
centers_negatives.append(center)
return (torch.tensor(centers_negatives).view(-1,1).contiguous(), torch.tensor(
contexts), torch.tensor(masks), torch.tensor(labels).view(-1).contiguous())
def load_data_ptb(batch_size,max_window_size:int,num_noise_words:int):
sentences = read_ptb()
vocab = Vocab(sentences, min_freq=10)
# 下采样高频词汇
subsampled, counter = subsample(sentences, vocab)
#
corpus = [vocab[line] for line in subsampled]
# 获得中心词汇以及对应的上下文词汇
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
all_negatives = get_negatives(
all_centers, vocab, counter, num_noise_words)
dataset=PTBDataset(all_centers, all_contexts, all_negatives)
data_loader=DataLoader(dataset,batch_size,shuffle=True,collate_fn=collate_fn)
return data_loader,vocab
class PTBDataset(Dataset):
def __init__(self,centers,contexts,negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
def cbow(centers,contexts,embed_v,embed_u,linear,embed_size):
v = embed_v(contexts)
u = embed_u(centers)
v=v.view(contexts.shape[0],-1).contiguous()
v=linear(v)
v=v.unsqueeze(dim=-1)
pred = torch.bmm(v.permute(0,2,1), u.permute(0, 2, 1))
return pred
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target):
out = F.binary_cross_entropy_with_logits(
inputs, target, reduction="none")
return out.mean(dim=-1)
def train(net,data_loader,lr,num_epochs,embed_size:int=30):
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = SigmoidBCELoss()
for epoch in range(num_epochs):
for i, batch in enumerate(data_loader):
optimizer.zero_grad()
center, context_negative, mask, label = batch
pred = cbow(center, context_negative, net[0], net[1],net[2],embed_size)
l = (loss(pred.reshape(label.shape).float(), label.float()))
l.sum().backward()
optimizer.step()
print('[epoch %d] train_loss: %.3f' %
(epoch + 1, l.mean()))
if __name__=="__main__":
data_loader, vocab = load_data_ptb(128, 5, 5)
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Linear(4 * embed_size, embed_size),
)
train(net,data_loader,1e-3,100,embed_size)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)