深度学习入坑笔记之一---房价预测
12221
深度学习入坑笔记之一----房价预测
实战房价预测问题
本文数据来自tensorflow教程官网。
房价预测问题属于监督学习的一种。所谓监督学习,是指给定一组输入x和输出y的训练集,学习y和x之间的函数关系。通常情况下,输出y很难自动收集,需要由人来提供“监督”,因此成为监督学习,不过该术语也适用于训练集目标可以被自动收集的情况。
目录
数据的录入
搭建模型
训练模型
预测房价
数据的录入
房价预测的深度学习,首先要有原始的数据及对应的标签,这是模型学习的基础。通过让计算机不断匹配原始数据与相应标签,得到一组合适的数学模型,再利用学习好的数学模型,根据新的数据去进行预测接下来的房价走势。这就是本章节的主要内容。
数据输入
根据tensorflow的官方教程,数据输入方式大体可以分为以下几种:
(1)预加载数据:此方式适用于数据量较小时使用,直接在程序中定义常量或者变量保持数据;
(2)数据供给feeding:通过给run()函数输入feed_dict参数的方式将数据传输到占位符placeholder中,再启动运算;
(3)从文件读取数据:该方法读取数据代表Tensorflow图的开始,让一个输入路线从文件读取开始。常用的读取格式有TFRecord和CSV两种,本章采用读取CSV文件。
(4)网上直接下载数据,本章内容涉及数据即直接从网上下载得到。
首先加载数据库
import warnings
warnings.filterwarnings('ignore') #忽略运行过程中的警告命令
#加载数据库
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
1.14.0下载数据波士顿房价数据信息
boston_housing = keras.datasets.boston_housing
(train_data, train_labels, test_data, test_labels) = boston_housing.load_data()
#波士顿房价数据下载,包含了训练数据、训练标签、测试数据、测试标签
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/boston_housing.npz
57344/57026 [==============================] - 0s 0us/step
到这一步为止,训练所需数据即下载完毕。
接下来检查以下下载的数据内容:
print("Training set: {}".format(train_data.shape)) # 404 examples, 13 features
print("Testing set: {}".format(test_data.shape)) # 102 examples, 13 features
Training set: (404, 13)
Testing set: (102, 13)数据总共包含506个样本,其中训练样本为404个,测试样本为102个。这些样本包含13个特征属性,这里不一一罗列。
数据标签
标签及房价,在数据集中代表已有数据对应的房价,在未来的模型中及代表预测的房价,即回归问题的目标。
print(train_labels[0:10]) # Display first 10 entries
[32. 27.5 32. 23.1 50. 20.6 22.6 36.2 21.8 19.5]
数据标准化
打开数据集可以发现,房屋的特征参数在数值上差距巨大,且单位标准不一,这会影响到模型计算结果,因此在建立模型之前需要将量纲统一为1,即数据归一化处理。
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / std
print(train_data[0]) # First training sample, normalized归一化的计算公式即:特征值减去平均值的差除以标准偏差
模型的搭建
def build_model(): #建立模型,给模型添加层,本示例全部采用全连接层,并结合relu激活函数
model = keras.Sequential([
keras.layers.Dense(64, activation=tf.nn.relu,
input_shape=(train_data.shape[1],)),
keras.layers.Dense(64, activation=tf.nn.relu),
keras.layers.Dense(1)
])
optimizer = tf.train.RMSPropOptimizer(0.001) #采用RMSProp算法,学习率为0.001
#采用均方误差作为损失函数
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])
return model
model = build_model()
model.summary() #输出网络结构_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 896
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 5,121
Trainable params: 5,121
Non-trainable params: 0
_________________________________________________________________训练模型
我们把模型训练次数设定为500,并且每完成一次训练,打印一个“.”,训练过程如下:
# Display training progress by printing a single dot for each completed epoch.
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 500
# Store training stats
history = model.fit(train_data, train_labels, epochs=EPOCHS,
validation_split=0.2, verbose=0,
callbacks=[PrintDot()])训练过程的数据都保存在了history里面,现在通过matplotlib将图像表示出来,比较一下训练结果和测试结果的不同:
import matplotlib.pyplot as plt
def plot_history(history):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [1000$]')
plt.plot(history.epoch, np.array(history.history['mean_absolute_error']),
label='Train Loss')
plt.plot(history.epoch, np.array(history.history['val_mean_absolute_error']),
label = 'Val loss')
plt.legend()
plt.ylim([0,5])
plot_history(history)
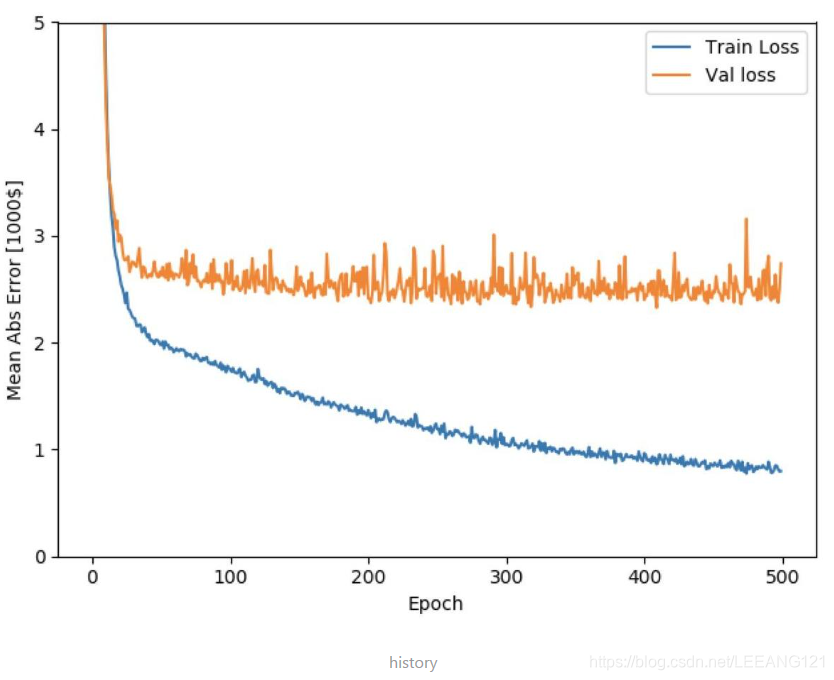
[loss, mae] = model.evaluate(test_data, test_labels, verbose=0)
print("Testing set Mean Abs Error: ${:7.2f}".format(mae * 1000))Testing set Mean Abs Error: $2679.54误差为2600附近,相较于房价而言,这个误差是偏大的。
房价预测
test_predictions = model.predict(test_data).flatten()
print(test_predictions)[ 7.832362 18.450851 22.45164 34.88103 27.348196 22.26736
26.963049 21.669811 19.895964 22.601202 19.965273 17.110151
16.567072 44.0524 21.04799 21.103464 26.45786 18.709482
20.825438 27.020702 11.160862 13.017411 22.807884 16.611425
21.076998 26.213572 32.766167 32.652153 11.298579 20.164223
19.82201 14.905633 34.83156 24.764723 19.957857 8.5664625
16.906912 17.79298 18.071428 26.850712 32.625023 29.406805
14.310859 44.013615 31.179125 28.41265 28.72704 19.22457
23.301258 23.555346 37.15091 19.271719 10.640091 14.898285
36.21053 29.63736 12.255004 50.43345 37.141464 26.562092
25.075682 15.84047 15.081948 20.062723 25.168509 21.119642
14.220254 22.637339 12.629622 7.517413 25.981508 30.909727
26.12176 12.866787 25.869745 18.303373 19.470121 24.58047
36.444992 10.777396 22.28932 37.976543 16.47492 14.191712
18.707952 19.026419 21.038057 20.713434 21.794077 32.14987
22.412184 20.55821 27.877415 44.4067 38.00193 21.748753
35.57821 45.50506 26.612532 48.747063 34.60436 20.451048 ]想要获得较好的预测数据,我们需要更大的数据集进行训练。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)