机器学习——Kaggle——Intro to Machine Learning
文章目录how Models WorkintroductionImproving the Decision TreeBasic Data ExplorationUsing Pandas to Get Familiar with Your DataInterpreting Data DescriptionYour First Machine Learning ModelSelcting Data f
·
文章目录
how Models Work
introduction
- 我们先对机器学习进行一个通俗全面的了解,主要是学习模型是怎么工作并且是如何使用。如果你有基础,可能会觉得很基础,不过没事,我们很快就教你怎么构建有效的模型
- 这个课程通过读下面这个故事让你能够创建模型
- 你的表兄弟通过房产投资赚了上千万美元,他打算邀请你成为商业伙伴,因为你对数据科学的兴趣。他打算提供钱,然后你提供模型,来预测不同的房子值多少钱
- 你问你的表弟他过去是怎么估计房屋价值的,他说就是直觉。但是更过的问题表明,他能够看出他过去所看到的每一个房子的价格特征,然后使用这些价格特征对他正在考虑的新房子做出合理预测
- 机器学习是以同样的方式进行工作的,我们先将决策树作为我们第一个要学习的模型。还有很多更加魔幻的模型能够给出更好的预测,但是那,决策树更加便于理解,而且他们还是数据科学中一些性能很棒的模型的基础
- 首先开始了解最简单的决策树
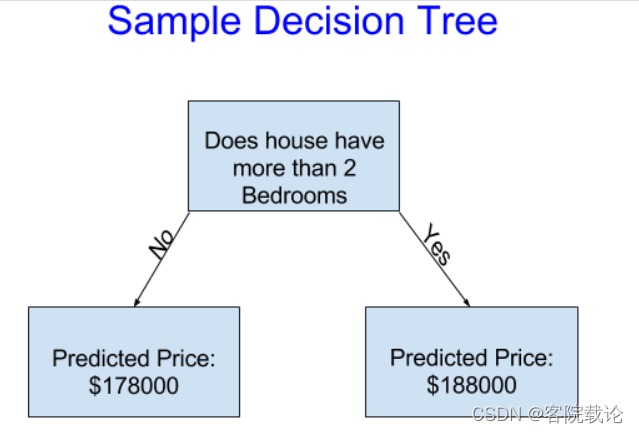
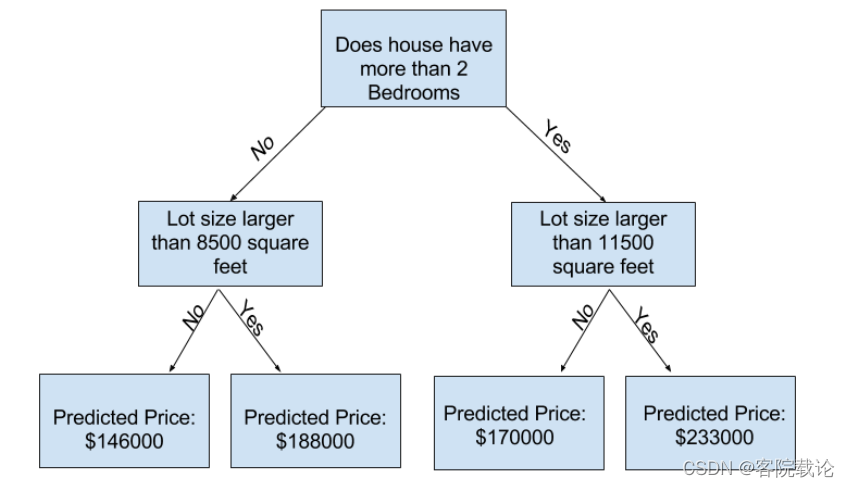
- 这个模型很简单,单单根据卧室的数量将房间划分为两个类别,每一个类别对应不同的价格。其中卧室的数量就是我们从数据中提取到的特征
- 我们使用数据去找到将房子划分成两部分的标注你,然后再据此决定新的数据的分组。从数据中获取分类的特征,我们称之为fitting或者training,用到的数据称之为训练数据
- 模型具体是如何进行调整的很复杂,暂且先不说。但是一旦模型已经调整过了,就可以将之用在新的数据上进行分类了。
Improving the Decision Tree
- 下面两个决策树,那个更可能是由实际的房产数据你和出来的
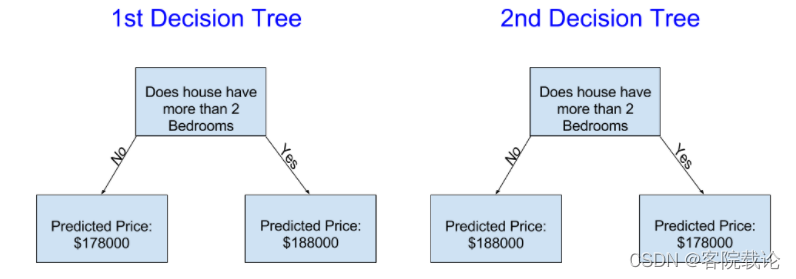
- 很明显是左边的决策树更加贴切,因为一般来说卧室越多,卖的越贵,但是有一个地方不是很好,没有考虑到别的影响当家的因素,比如说地段,房间的面积大小等因素。你可以使用一个有更多分叉树来抓住更多的信息。一个考虑到房屋面积的决策树和下面这个就是十分相似
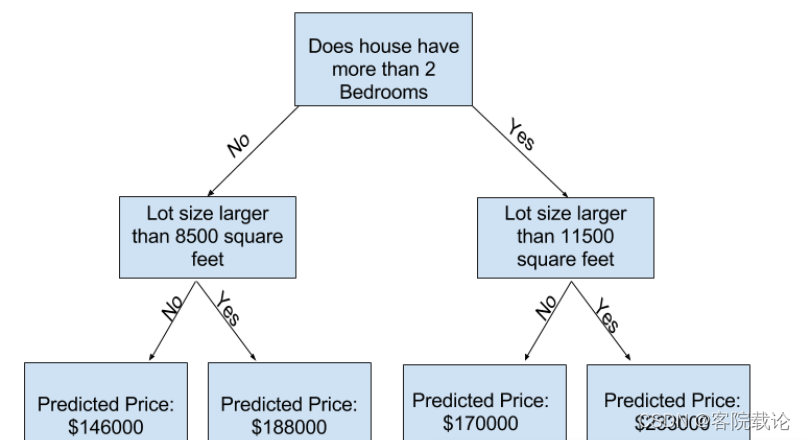
Basic Data Exploration
Using Pandas to Get Familiar with Your Data
- 机器学习工程中的第一步一般都是熟悉数据。一般都会用Pandas库进行熟悉,这是数据科学家探索和分析数据的基础工具,一般都吧pands简称为pd
- Pandas库中最重要的部分是DataFrame。一个DataFrame所包含的数据类型,你可以认为是一个表格。和excel中表格很像,也和SQL中的数据库很像
- Pandas关于这个数据类型有很多比较有效的方法
- 例如,我们看看关于Melbourne和澳大利亚的房价数据。在任何一个房价洼地的数据集,他的处理方式基本上都是相同的
- Melbourne样例的数据文件的文件路径是
../input/melbourne-housing-snapshot/melb_data.csv - 我么使用如下的命令加载和探索数据集
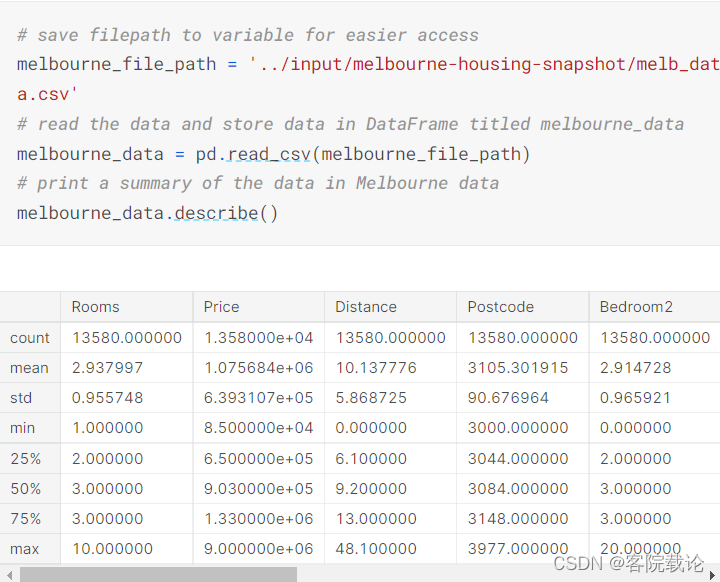
Interpreting Data Description
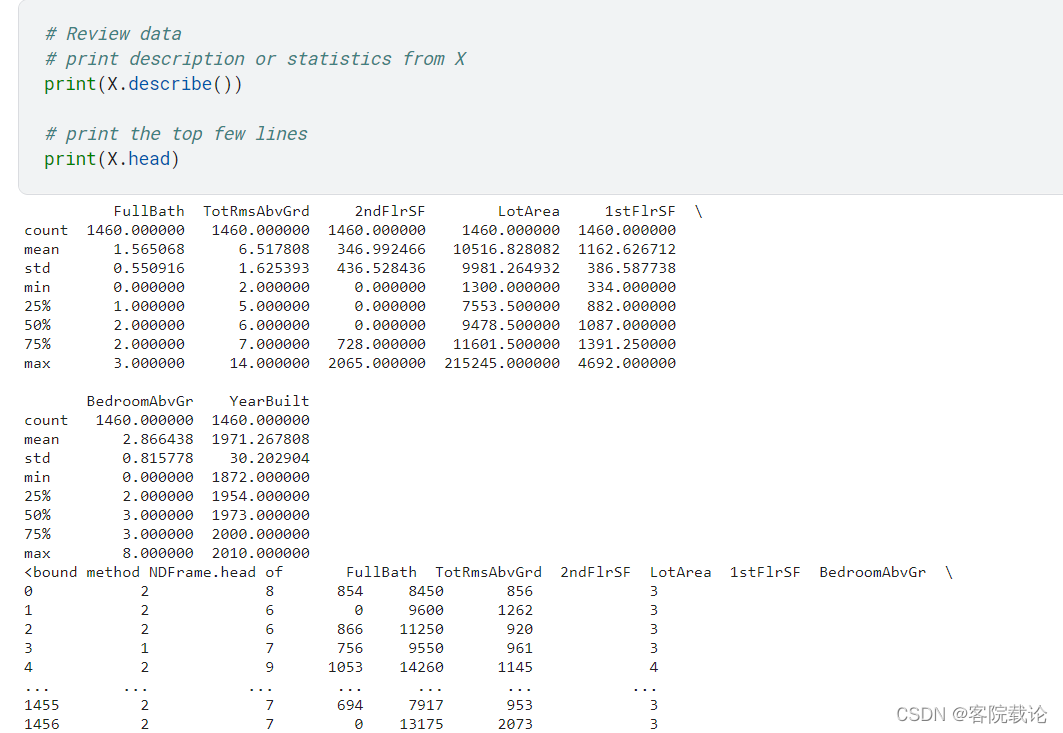
- 上述图片展示了你原始数据集中的8个数据
- 第一个数字count,展示了有多少行有非缺失值
- 因为很多原因缺失了一些数字,比如说,当调查只有一间卧室的房间时,我们第二间卧室的大小没有被收集。让我们回到数据缺失的问题上
- 第二个数据是平均值mean
- 第三个数据std,是标准差,用于衡量数值的离散分布程度
- 往下五个依次是min,25%,75%和最大值max。想象一下,将数据从低到高进行排序。最小的值就是min,遍历整个list的四分之一,对应的就是25%的值,后续几个数字也是这样定义的。
Your First Machine Learning Model
Selcting Data for Modeling
- 这个数据集有太多的变量,以至于都没有办法很清晰地打印出来。那么你如何将这些数量惊人的数据转变成你所能够理解的事务?
- 首先我们凭借我们的直觉选择一些变量,在之后课程中,将会交给你一个写分析技术,去自动按照权重排序变量
- 为了选择变量/列,我们需要的看到数据集中所有的列,这就可以使用column函数,直接显示出DataFame的具体数值
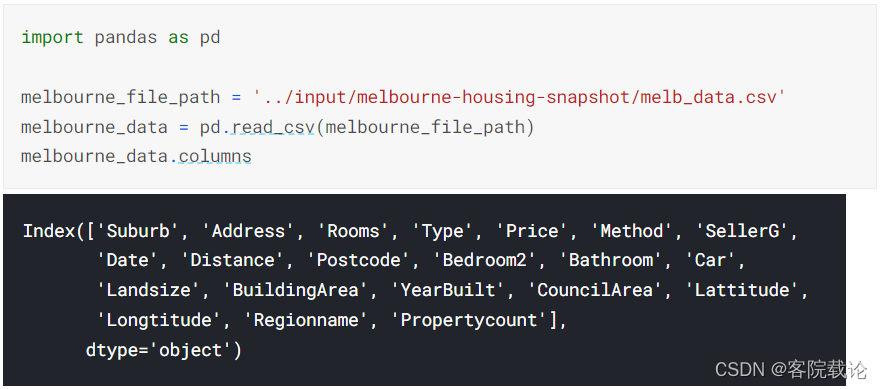
- 下面我们将集中提取数据集中的两部分
- 选出预测目标列
- 选出特征列
Selecting The Prediction Target
- 你可以使用点标记找出某一列变量,找出来的标记被保存在Series中。
- 一般使用该方法选择出数据集中的预测目标列。在如下的样例中,我们使用将预测目标列成为y,也就是数据集中的房价

Choosing “Features”
-
被输入模型中的列被统称为“Features”,在我们的样例中,这些可以被用来决定最终的房价。有时,你将使用所有的列,当然不算预测目标列。但更多的时候,你会排除一些别的特征
-
对于现在而言,我们将会建造一个模型,该模型仅仅使用一部分特征。之后,我们将会展示如何迭代和比较使用不同特征的模型
-
现在通过在方括号中加上对应的列名,来选择几个特征。方括号中的每一项都应该是字符串。样例如下

-
按照约定,一般是将特征命名为X

Building Your Model
- 你将使用scikit-learn库去创建你的模型。当你编码的时候,这库你可以写成sklearn。对于创建针对存储在DataFrame中的数据,sklearn一般是最流行的库
- 建造和使用模型的步骤如下
- Define:最终会是什么类型的模型?决策树?又或者是的一些别的类型的模型?
- Fit:从所给的数据中获取特征,这是模型的核心
- Predict:对数据进行预测
- Evaluate:决定预测结果有多准确
- 下面是一个使用sklearn定义决策树的样例,同时传入特征和目标变量
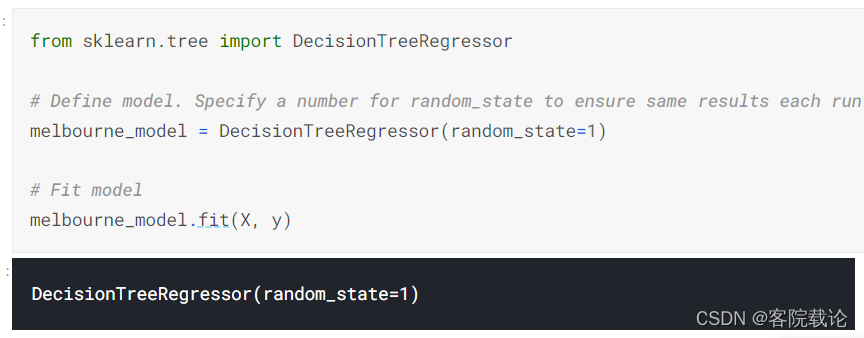
- 很多机器学习模型在模型训练的时候可以允许一些变量。指定random_state的数字,确保你在每一次运行的时候都可以得到同样的结果。这被认为是一种很好的实践。你使用任何数字,模型的质量并不会有意义地取决于你所选择的值
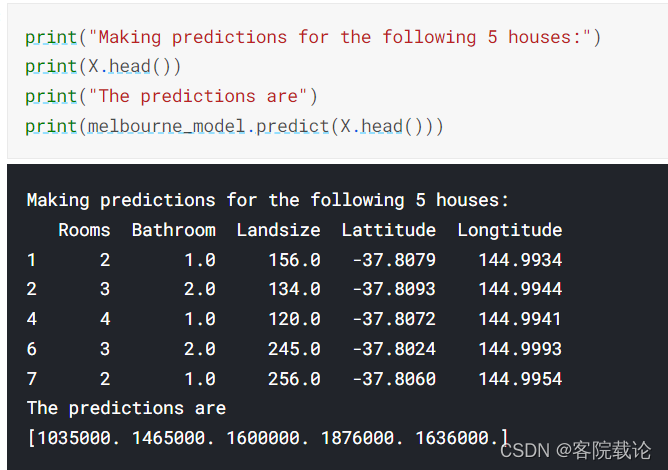
- 我们现在已经Fit了模型,可以开始做预测了
- 在练习中,你将对于市场上的新房子做出一些预测,而不是已经给出房价的房子
Exercise:Your First Machine Learning Model
- 到目前为止,你已经加载了数据并且已经使用如下的代码浏览了一下。
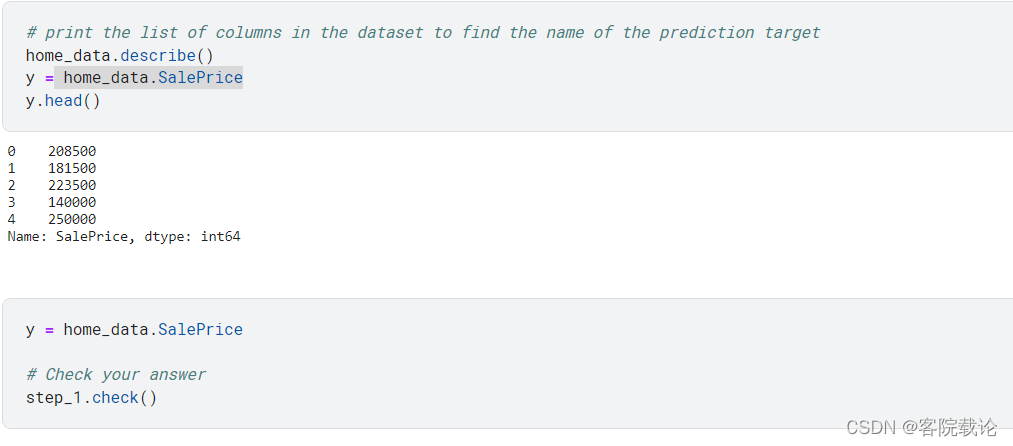
Step1:Specify Prediction Target
- 选出目标变量,也就是房子的具体的售价。将之保存为一个新的变量。同时还要打印出所有你需要的列
Step2:Create X
- 下一步,你要创建包含预测特征的DataFrame,并命名为X
- 因为你仅仅只想从原来的数据中获取某些列,所以,你首先要创建一个list,同时其中要包含你所需要的列的名称
- 你将仅仅使用在列表中的如下的几个名称:LotArea、 YearBuilt 、1stFlrSF 、2ndFlrSF 、FullBath 、BedroomAbvGr、 TotRmsAbvGrd
- 你创建了features之后的list之后,使用这个list去创建一个DataFrame,你将用这个去调整fit你的模型
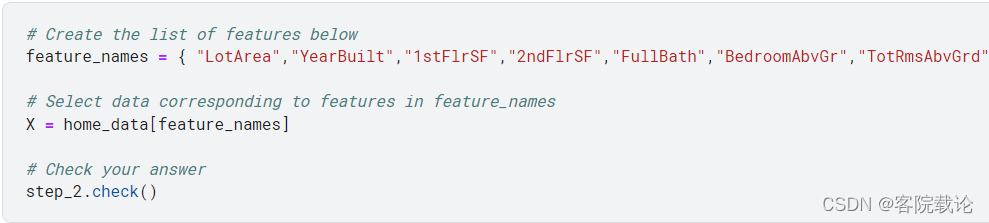
- 注意,这里不同使用名称的单个字符,点获取数据的方式
Review Data
- 在创建一个模型之前,我们简单看一下X,去看看他是不是正确
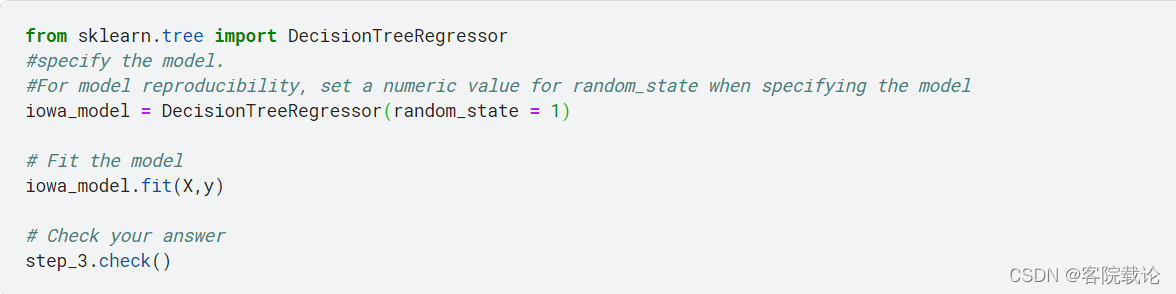
Step 3:Specify and Fit Model
-
创建一个DecisionTreeRegressor,保存为iowa_model,确保你已经导入了sklearn的相关包。然后开始调调整fit模型,使用你已经创建的X和y
-
注意,如果要确保出现的结果一致,必须指定对应random_state,指定随机数生成的方式等
Step 4:Make Predictions
- 使用模型对训练集进行验证,并将结果保存为y
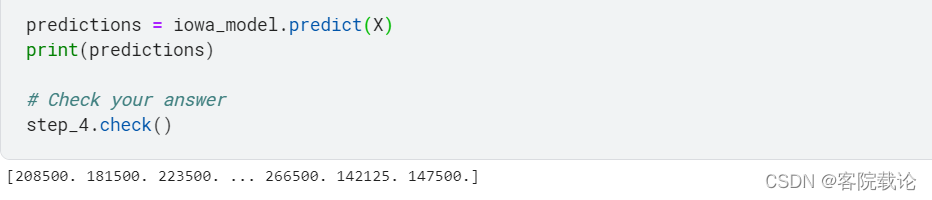
Model Validation
- 你已经创建了你的模型,但是性能怎么样?
- 在这部分,你将学会使用模型验证去衡量模型的效果。测量模型的质量是优化模型的关键
What is Model Validation
- 你想评价你的每一个模型,在大部分的应用中,与模型质量相关的参数就是预测准确度。换句话说,就是模型的预测结果和实际发生的很像
- 当测量预测准确度时,很多人都会犯错。他们一般都是使用去预测训练集中的数据,并将预测结果和训练集的标记相比较。过一会你就能看到这个方法的问题,顺便学一下怎么解决这个问题,但是首先让我们想想,我们该怎么做
- 首先需要将模型质量理解为一种可以理解的方法。如果你比较一下1万套房子的预测价值和实际的房屋价值,你可能会发现好的预测和坏的预测的混合。浏览一份包含1万个预测值和实际值的列表将是毫无意义的。我们需要把它总结为一个单一的度量标准。
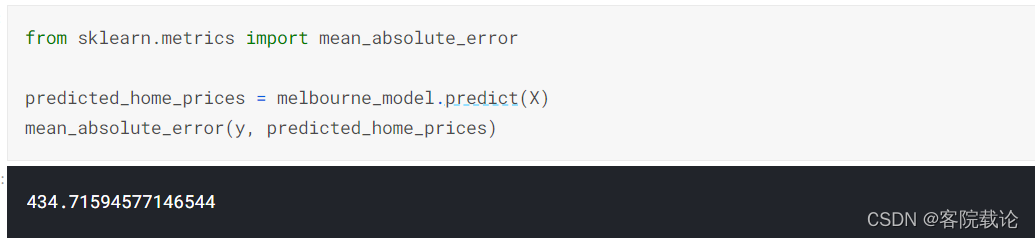
- 有许多指标可以总结模型质量,但我们将从一个名为平均绝对误差 Mean Absolute Error (也称为MAE)的指标开始。让我们从最后一个词,错误开始来分解这个度量。
- 每一个房子的预测误差

- 所以,如果一个房子花了150000,但是你花了100000,误差就是50000
- 如果使用了平均绝对误差,我们会提出每一个误差,并将之转为绝对值。然后我们对这些值取平均。这就时模型质量的衡量方式,直白的说,就是平均而言,我们的预测偏离了X
- 为了计算MAE(平均绝对误差),我们首先需要一个模型,这里我们用下面这个现成的模型
- 有了一个模型,就可以开始计算平均绝对误差
The Problem with “In-Sample” Scores
- 我们刚刚使用的计算方式被称为“样例内”的分数。对于一个样例而言,我们既用它训练模型,有用它来评测模型,这就是有问题的原因
- 设想一下啊,在一个真实的比较大房地产交易市场中,们的颜色和房价是不相关的
- 然而,在你创建模型的样例中,所有有绿门的房间就很贵。模型工作就是找到能够预测房价特征,所以他就会专注与这个特征,所以会将所有有绿色的门的房子预测为高价
- 因为这个特征就是是根据训练集得出来的,所以在训练集中会有很高的准确度
- 但是当模型处理新得数据时,而新的数据又不包括这个特征,那么这个模型在实际使用中会变得很不准确
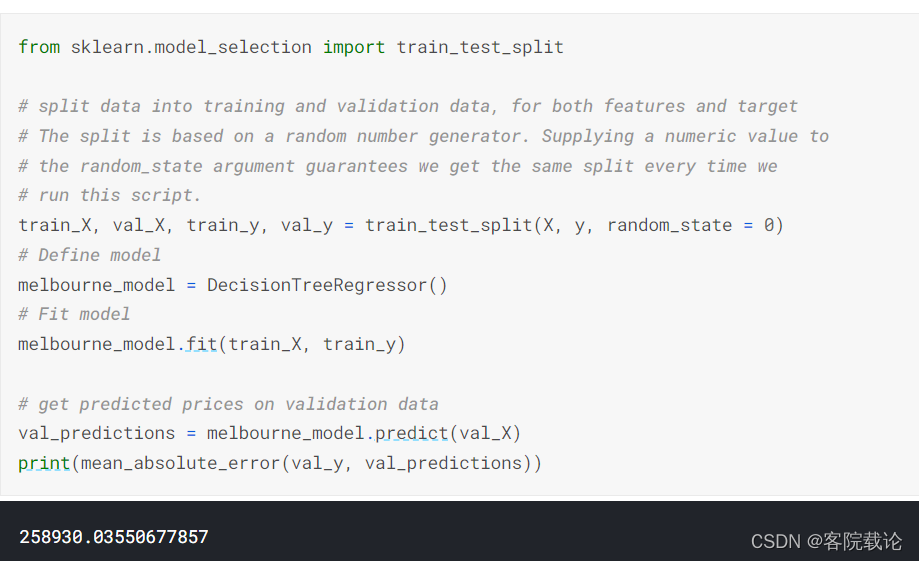
- 因为模型的实际运行效果是来自于对新数据的预测,所以我们衡量模型的性能的时候,就不能够使用创建模型的时候使用的数据。最直接的方式就是在训练模型的时候,就排除一些数据,然后使用这部分数据去测量模型的准确度。这部分的数据被称为验证集
- 编码如下
Underfitting and Overfitting
- 在这一节的末尾,你将理解过拟合和欠拟合的概念,你能够将这些方法应用到你的模型中,使其更加准确
Experimenting With Different Models
- 已经有一个稳定的方法去衡量模型的精确度,然后你就可以尝试不同的模型,看看哪个模型有最好的精确度。但是你有可以选择那些模型那?
- 你可以参考scikit-learn的文档,其中关于决策树的部分就有很多的选项。最终的选项决定了决策树的深度,想想在之前的部分我就提过树的深度能够直观地表现他有多少分叉。下图是一个比较浅的决策树
- 在实际操作中,一般从顶端到叶子节点都有十个节点。因为树越深,数据集就会被分配到更详细的叶子节点。如果树只有一个叶子节点,将会将数据分为两个组。如果每一个组在被划分,我们会得到四组房子。在划分一组会得到8组,如果我们持续在每一层增加更多的节点,那么我们能得到翻倍的房屋组。如果有10层,那就有1024个房屋组
- 当我们将房子按照越来越多的节点进行分割,那么没有给叶子的房子数量会越来越少。所包含房子越少的节点将会做出更加准确的预测,但是也可能会对新数据做出不准确的预测。
- 这种现象就是过拟合,指得是模型集合完全拟合了训练数据,但是对于验证集表现就很差。反过来,如果我们是我们的树更浅,他并不会将房子划分到很经确的组
- 极端的情况就是,我们仅仅把房子划分到2到4组,每一组都会有大量的房子。将会导致预测结果偏离大部分的房子,甚至是在训练集上。当一个模型不能很好地获取数据重要的差别和特征,他可能就不能很好地拟合数据,这就是欠拟合。
- 因为我们很在意新数据集上的准确性,这是从验证机上估计得来的。我们想找到一个在过拟合和欠拟合之间一个比较合适的点。如下图,我们想找到红线的最低点
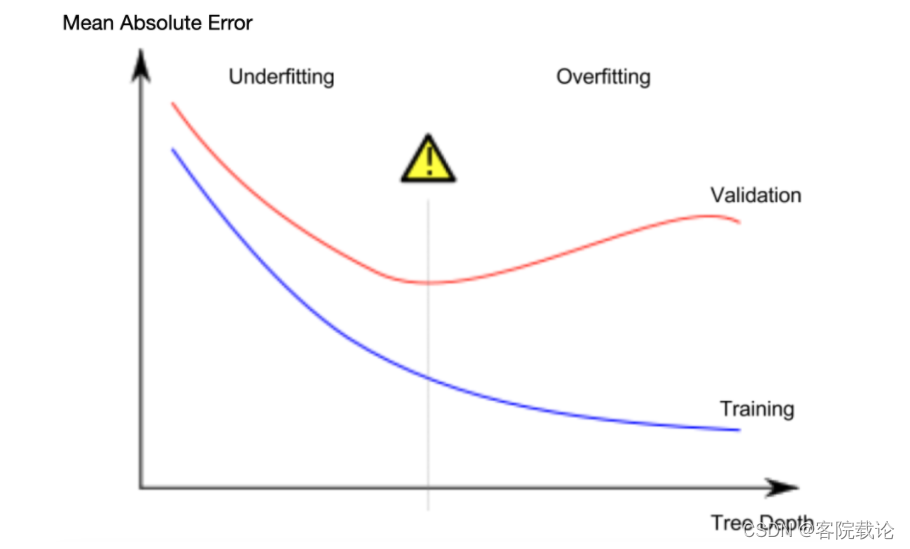
Example
- 有很多方式来控制树的深度,甚至有的时候,树并不是完全的,不同的路线会有不同的深度。如果我们让树有更多的节点,就越可能导致过拟合。
- 我么可以使用相关的功能函数,来帮助我么比较max_leaf_nodes不同的树所对应的MAE
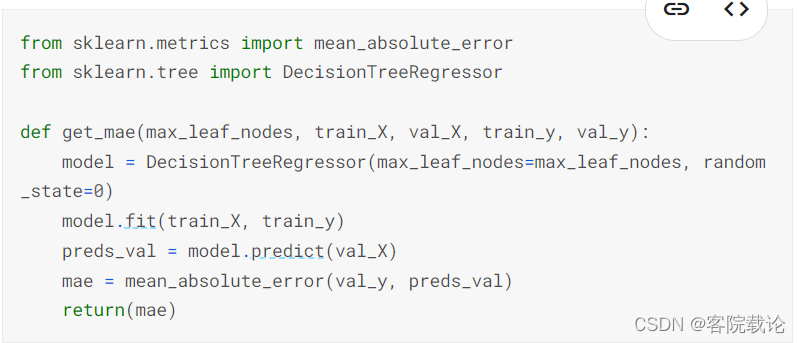
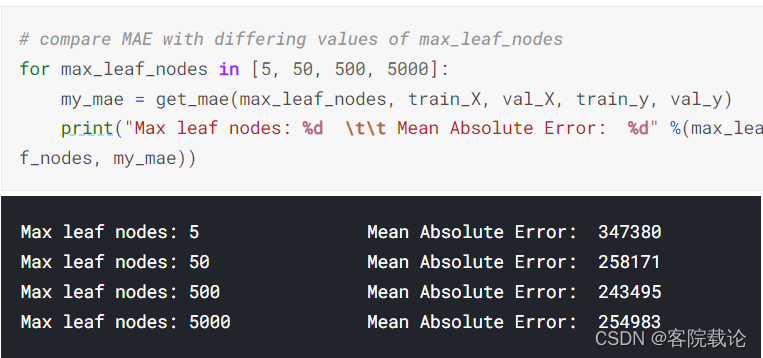
- 测试结果如下
Conclusion
- 过拟合,是因为抓去了虚假的特征,当我们输入新得数据时,这些特征并没有重新出现,导致精确度很低
- 欠拟合,因为没有抓到相关的特征,也会导致精确度很低
Exercise:Underfitting and Overfitting
- 定义get_mae函数
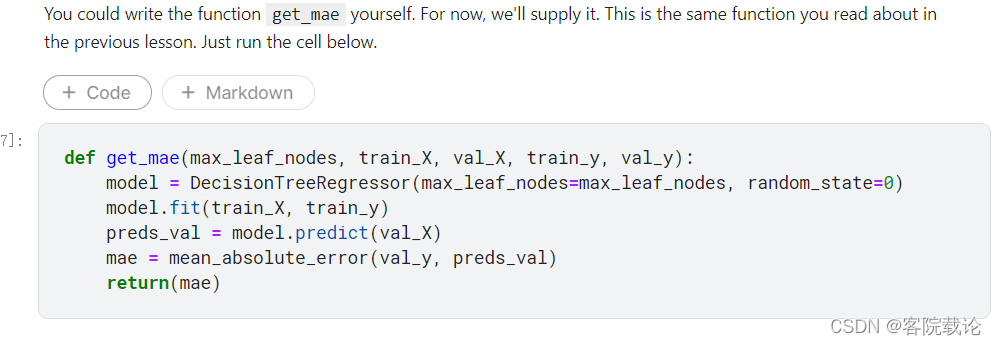
- 遍历所有的可能的组合,获取最终的最优值
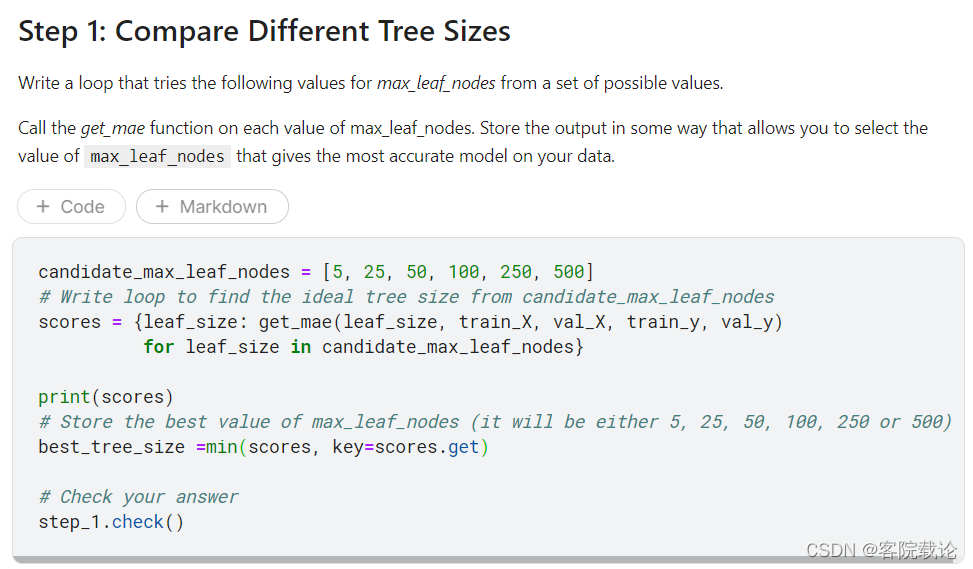
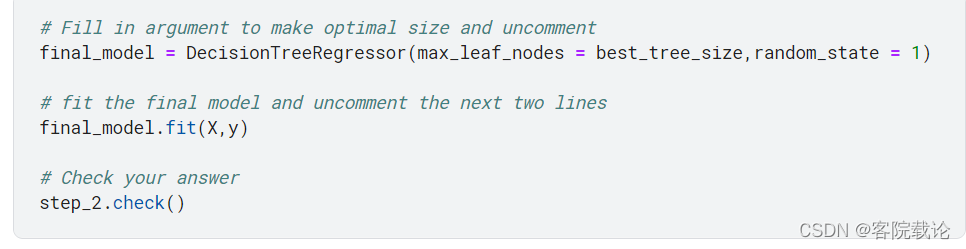
- 选择最优的参数进行值训练
Random Forests
Introduction
- 决策树给你留下一个艰难的决定,有很多叶子节点的深层树将会过拟合,因为每一个预测都是来自于历史数据,并且仅仅是针对几种房子的特殊情况。但是一个只有几个叶子节点的浅层树的效果就很差,因为他没能够抓住原始数据的特征
- 在今天,绝大多数比较完全的模型都会面对过拟合和欠拟合的困境。但是很多模型有很不错的想法,能够不带来欠拟合或者过拟合而带来更好的效果,随机森林就是其中一个
- 随机森林使用很多树,并且是通过平均每一个组成树的预测结果来做出最终的预测。比起单独的一颗决策树,随机森林能够产生更好的预测精度。如果你持续建模,你能够学习更多有更好效果的模型,但是无论是那种,设定一个正确的参数十分重要
Example
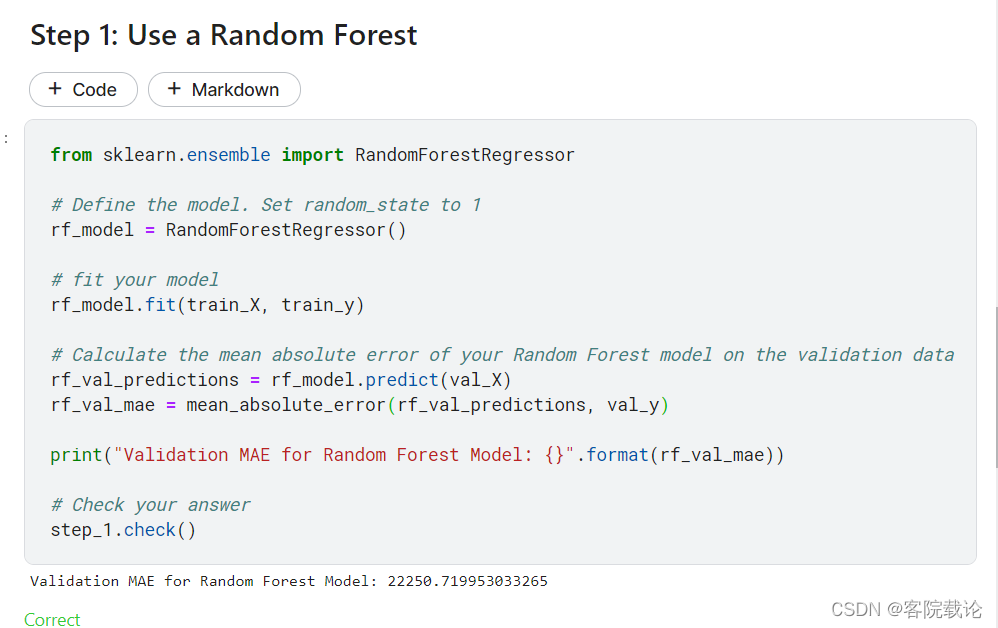
- 在将数据集划分为测试集和训练集之后,我们创建一个随机森林模型,这过程和我们创建决策树的过程十分相似,不过我们这次是使用RandomForestRegressor函数
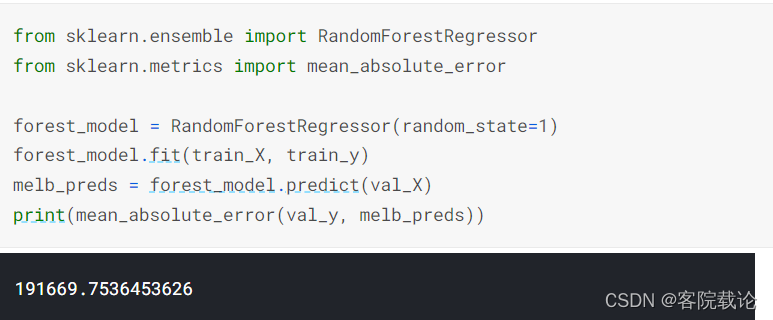
Conclusion
- 可能这个结果还有很多调优的空间,但是这对于最佳决策树的250000而言已经是一个很大的进步了。而且就像你设置修改决策树的参数获取最有效果一样,随机森林还有很多参数修改也可以实现调优。但是随机森林最大的特征就是即使没有任何优化,也可以正常工作。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)