大模型应用:文档系统开发
大模型应用:文档系统开发
最近在帮助别人维护安卓项目,多年没涉及安卓的知识,到处都是坑,还好有大模型老师进行解答。不然太难了😂
想着之前做过关于大模型技术的项目,这个项目是来自于朋友的推荐~~~承蒙朋友的引荐,得以担此项目,实乃荣幸之至🌻。
终于把大模型技术,运用于实际的业务中,让大模型的技术更进一步落地到应用中。
初版成果展示如下:虽然界面观感尚有提升空间,但客户对此并不特别在意,他们更关注的是应用的准确性与实际效果。🌻
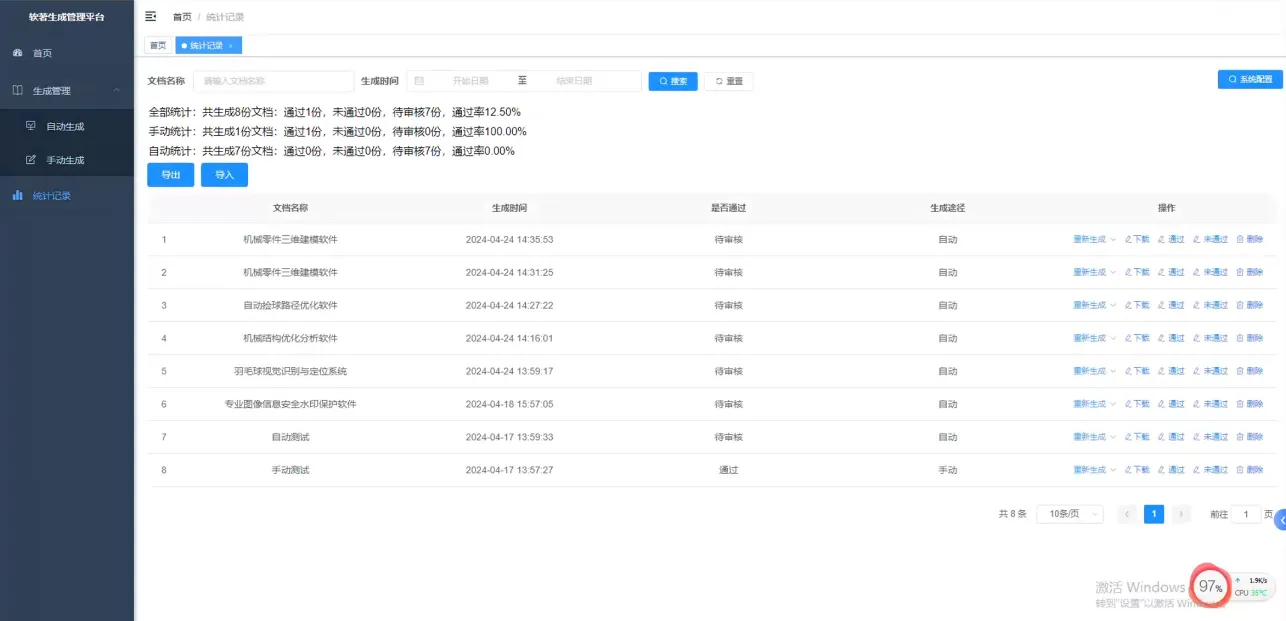
一、业务需求
客户这几年积累了很多年的Word 文档,但是每次写一篇新文档下来,都需要花1天的时间,效率很低。于是找到我,希望怎么才能给他进行高效提速。以下一些问题:
- 内容重复:
由于使用相同的行业术语和内容,用户可能发现自己在不断地复制和粘贴以前的文档,这样做既浪费时间又容易出现错误。
- 格式困扰
用户可能发现每次都需要重新设置字体、标题样式、页眉页脚等格式,这不仅耗时还容易导致不一致的外观。
- 费时费精力
因为都是一些固定的排版的文档,每一次写新的文档,都会不断的去查找之前的资料,进行编写。非常的费时间和精力~~~😔
设想一下,如果存在一个平台系统,它能够对之前所有的Word文档进行知识提取,并且进行标签化的分类存储。这样一来,在撰写新文档时,就能够依据主题以及自己设定的标题,系统地自动挑选出所需的知识素材和图片。这样的系统无疑将大幅提升工作效率,使得文档撰写更加精准、高效。~~~~最终形成一个完整的💐。
二、技术实现
为了保证重复率,我们打算利用大模型技术进行文本生成。
但是会有一个难点,就是大模型的生成不是很精准,往往会出现幻觉等问题。
最后与队友思考再三,决定利用大模型的能力去改写知识文本,确保文本的语义正确的前提下,对本文进行丰富。
那么怎么去设计这个架构呢🤔。
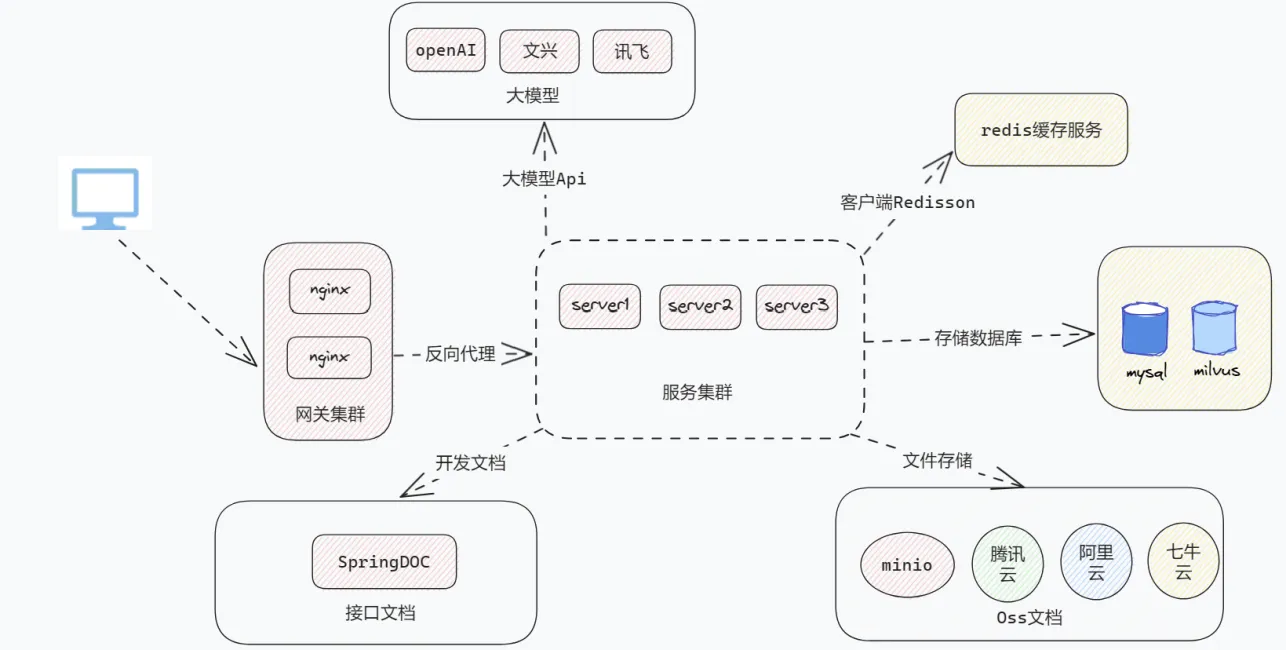
(1)首先得把所有历史知识放入知识库,如果利用向量库做成知识库的话,那么这需要很大的内存资源,考虑到客户的成本,因此放弃向量库。最后做成简版的mysql去存储知识文档。
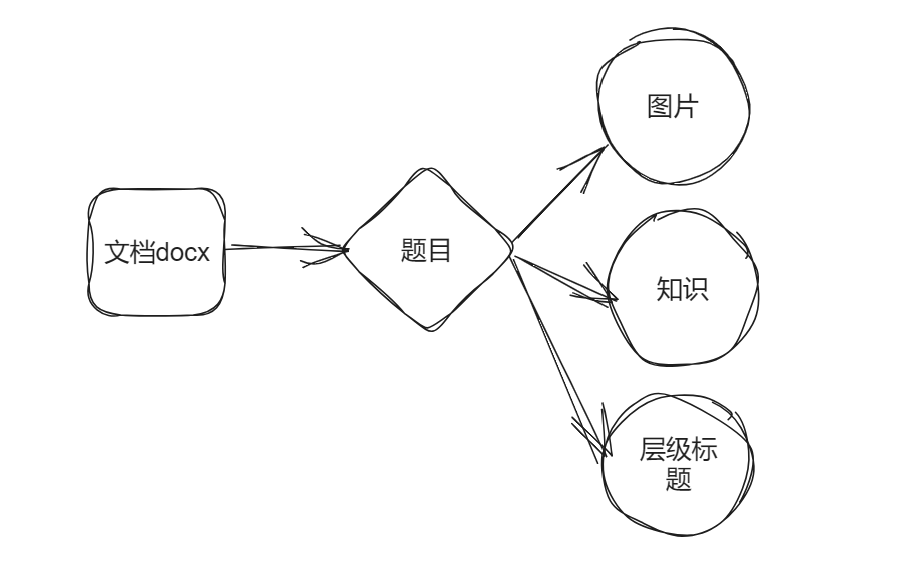
把每个文档分成三块进行提取存入mysql数据库。
第一快:层级标题。第二块:图片。第三块:知识
比如:一篇文档。题目是一个字段,每个层级标题是一个字段,对应的知识也设计了一个字段。
(2)当用户想生成新的文档,只需要对主题进行搜索。通过关键词模糊查询到相似的匹配到对应的文档,选择文档之后,就可以把所有文档的层级标题进行提取,然后根据需求进行筛选,确定一个标题之后,相应的知识和图片也会随着填充。
(3) 最终,会根据用户的选择将知识发送给大模型进行改写润色,待大模型完成工作后,再将其返回给用户。
平台核心工作流程如此,其中值得说明的就是对大模型的提示词编写以及对大模型的选定。推理能力强的大模型配上结构化提示词,那效果杠杠的。紧接后续的都是对生成文档转换成pdf文档等常规操作。
三、项目扩展
在这个项目中,有以下几个难点:
- 文档解析
用户的历史文档格式千差万别,所以对不同格式的文本解析尤为困难。
- 大模型应用
因为是知识库类型的项目,考虑大模型RAG。由于成本高,放弃。采用把知识结构化,利用sql进行搜索,精准度下降。
- 文档下载
需要把用户选择配置好的新文档,进行生成docx格式和pdf格式,并且以zip压缩包的形式进行下载。
当然,在完成这个项目之后,我也把相同的理论基础,带到了自己的大模型知识库管理平台。
(1)知识库,采用的是RAG向量库进行检索知识,在准确度方面得到了很大的提升。
(2)风格迁移,因为大模型生成的文句比较AI化,所以采用了微调大模型,获取到了合适的语句风格。
(3)搜索,采用了大模型搜索技术,随时可以根据用户的关键词进行搜索,获取精准的互联网回答。
四、总结
更多详情,小伙伴们关注公众号。
我发现很多小伙伴对大模型感到失望,因为虽然有很多可用的工具,但它们往往无法提供真正符合需求的答案。
主要原因是在于这些大模型大多数是通用型的,没有接入特定的知识库,未经针对性微调,也没有充分利用它们的功能,因此产生的结果常常不专业。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)