图解大模型分布式训练:数据并行
在DP中,每个GPU上都拷贝一份完整的模型,每个GPU上处理batch的一部分数据,所有GPU算出来的梯度传到master进行累加后,再传回各GPU用于更新参数DDP通过定义网络环拓扑的方式,将通讯压力均衡地分到每个GPU上,使得跨机器的数据并行(DDP)得以高效实现DP和DDP的总通讯量相同,但因负载不均的原因,DP需要耗费更多的时间搬运数据最后请大家记住Ring-AllReduce的方法,因为
随着大模型参数量的爆炸性增长,其所需内存也呈爆炸性增长,最现实的问题就是单块显卡装不下模型,所以我们需要进行分布式训练。
演进路线
- 数据并行Data Parallelism:一台机器可以装下模型,所以将同一个模型同时部署在多台机器,用多份数据分开训练
- 管线并行Pipeline Parallelism:一台机器装不下模型,但模型的一层或多层一台设备装得下,所以同一个模型按层拆开训练
- 张量并行Tensor Parallelism:模型的一层都装不下了,所以同一个模型层内拆分开训练
本文我们主要介绍数据并行,管线并行与张量并行以及Megatron和ZeRO会陆续介绍。
Data Parallelism
- DP(Data Parallelism):最早的数据并行模式,一般采用参数服务器(Parameters Server)这一编程框架,有master节点,实际中多用于单机多卡
- DDP(Distributed Data Parallelism):分布式数据并行,采用Ring AllReduce的通讯方式,无master节点,实际中多用于多机场景
其中Ring All-reduce在Pytorch里的实现就是DistributedDataParallel。
Parameter Server
在PS架构中,包含parameter server和worker两个角色。parameter server中储存模型参数,被视为master节点,worker将充当计算节点负责模型训练。
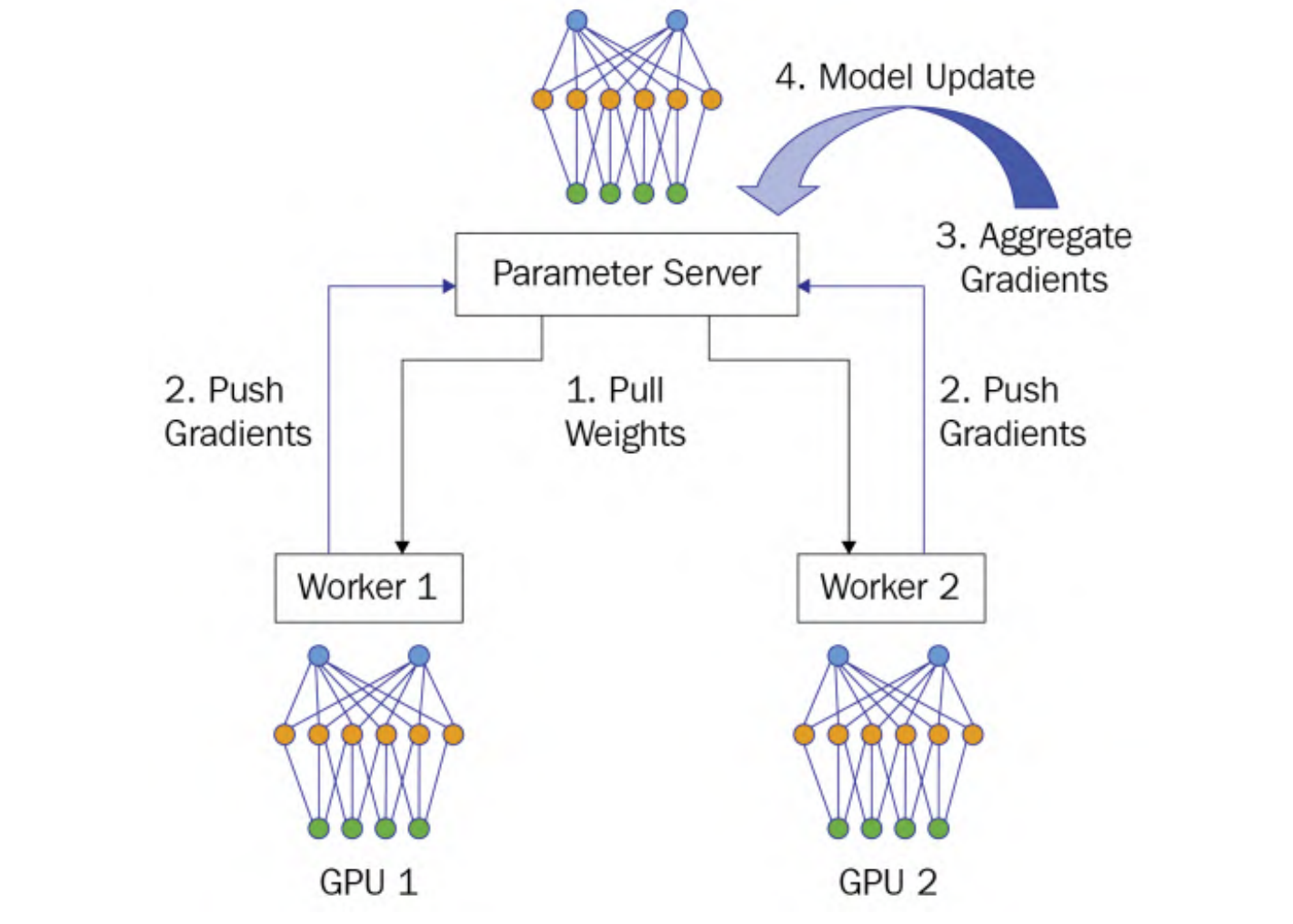
整个系统的工作流程分为4个阶段:
- Pull Weights: 所有worker从参数服务器获取权重参数
- Push Gradients: 每一个worker使用本地的训练数据训练本地模型,计算本地梯度,之后将梯度上传参数服务器
- Aggregate Gradients:收集到所有计算节点发送的梯度后,对梯度进行求和
- Model Update:计算出累加梯度,参数服务器使用这个累加梯度来更新位于集中服务器上的模型参数
可见,上述的Pull Weights和Push Gradients涉及到通信。首先对于Pull Weights来说,master同时向worker发送权重,这是一对多的通信模式,称为fan-out。假设每个节点(master和worker)的通信带宽都为1。假设在这个数据并行训练作业中有N个工作节点,由于集中式参数服务器需要同时将模型参数发送给N个工作节点,因此每个工作节点的发送带宽仅为1/N。另一方面,每个工作节点的接收带宽为1,远大于参数服务器的发送带宽1/N。因此,在拉取权重阶段,参数服务器端存在通信瓶颈。与此对应,对于Push Gradients来说,所有的worker并发地发送梯度给master服务器,称为fan-in,参数服务器同样存在通信瓶颈。基于上述讨论,通信瓶颈总是发生在参数服务器端,所以可通过负载均衡解决这个问题。
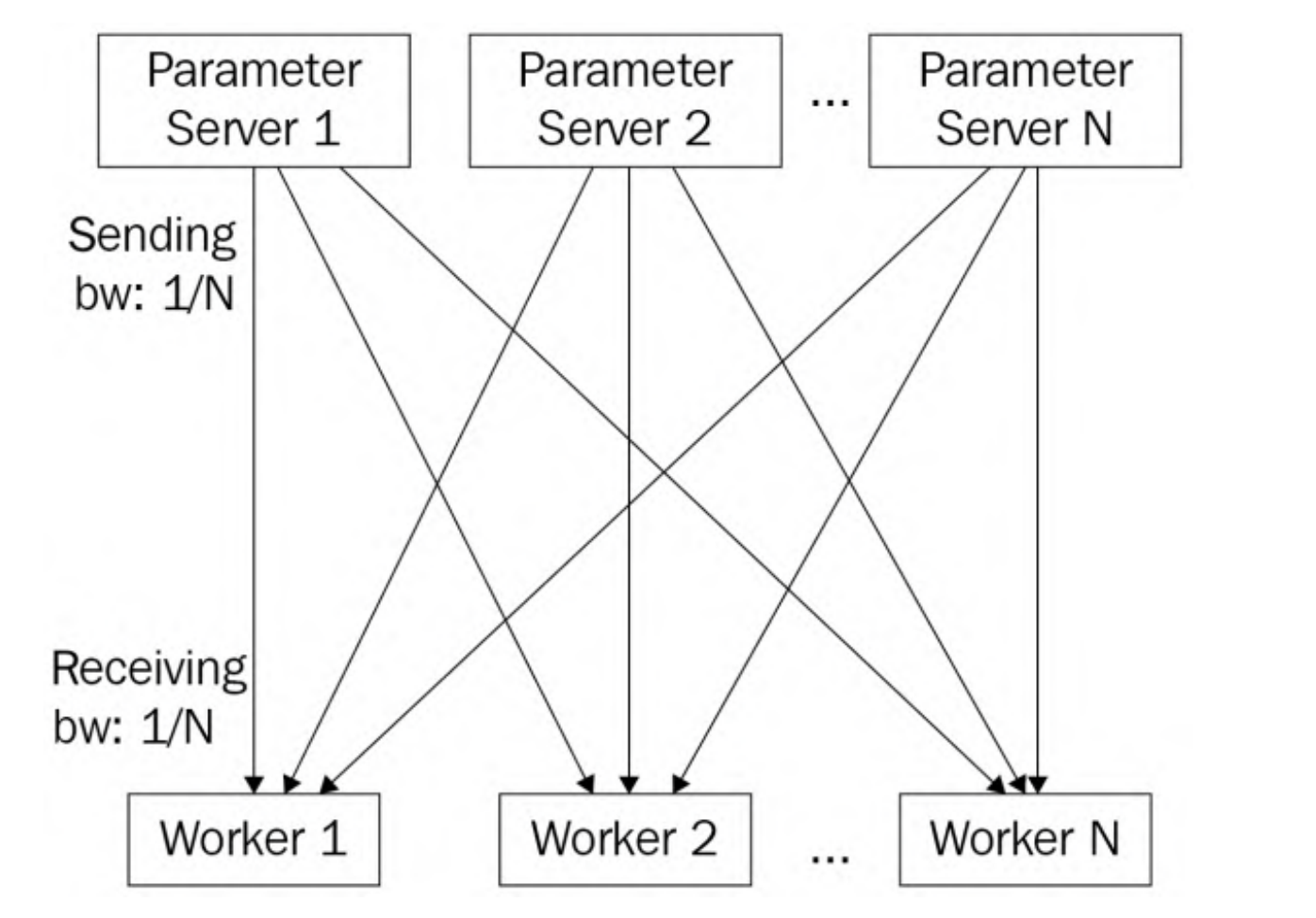
具体做法是将模型划分为N个参数服务器,每个参数服务器负责更新1/N的模型参数。实际上是将模型参数分片(sharded model)并存储在多个参数服务器上,可以缓解参数服务器一侧的网络通信瓶颈问题,使得参数服务器之间的通信负载减少,提高整体的通信效率。
Ring-Allreduce
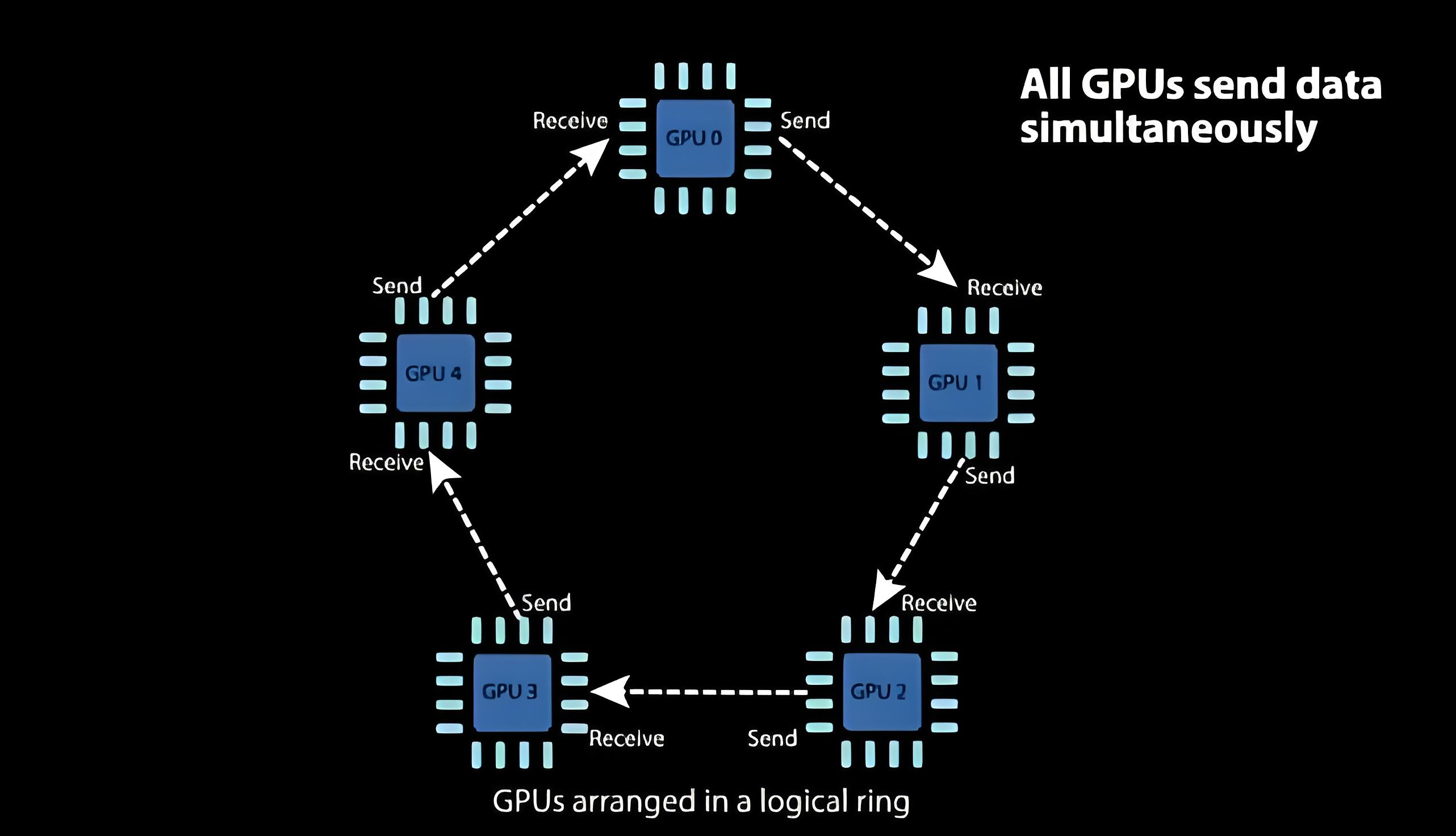
受通讯负载不均的影响,PS一般用于单机多卡场景。因此,DDP(Distributed Data Parallelism)作为一种更通用的解决方案出现了。在Ring-All reduce架构中,各个设备都是worker,并且形成一个环,没有中心节点来聚合所有worker计算的梯度。
首先对术语做一个解释(在阅读后续文章时会遇到):
- Broadcast:是将同一数据广播分发到所有的进程(所有进程共享相同的数据)
- Scatter:是将不同的数据分发到不同的进程中(不同进程所获取的数据是不同的)
- Reduce:将不同进程中数据经过某个映射函数映射后将结果存放在一个进程中
- All Reduce:是在Reduce的基础上,将最后结果也分发给其它进程
- Gather:是将不同进程中的数据合并在一起
下面来看Ring-AllReduce过程。设有4块GPU,将每个GPU存储的数据顺序切分为4块,然后把4块GPU首尾相连构成一个逻辑环。Ring All-reduce分两大步骤实现,分别是Reduce-Scatter和All-Gather。
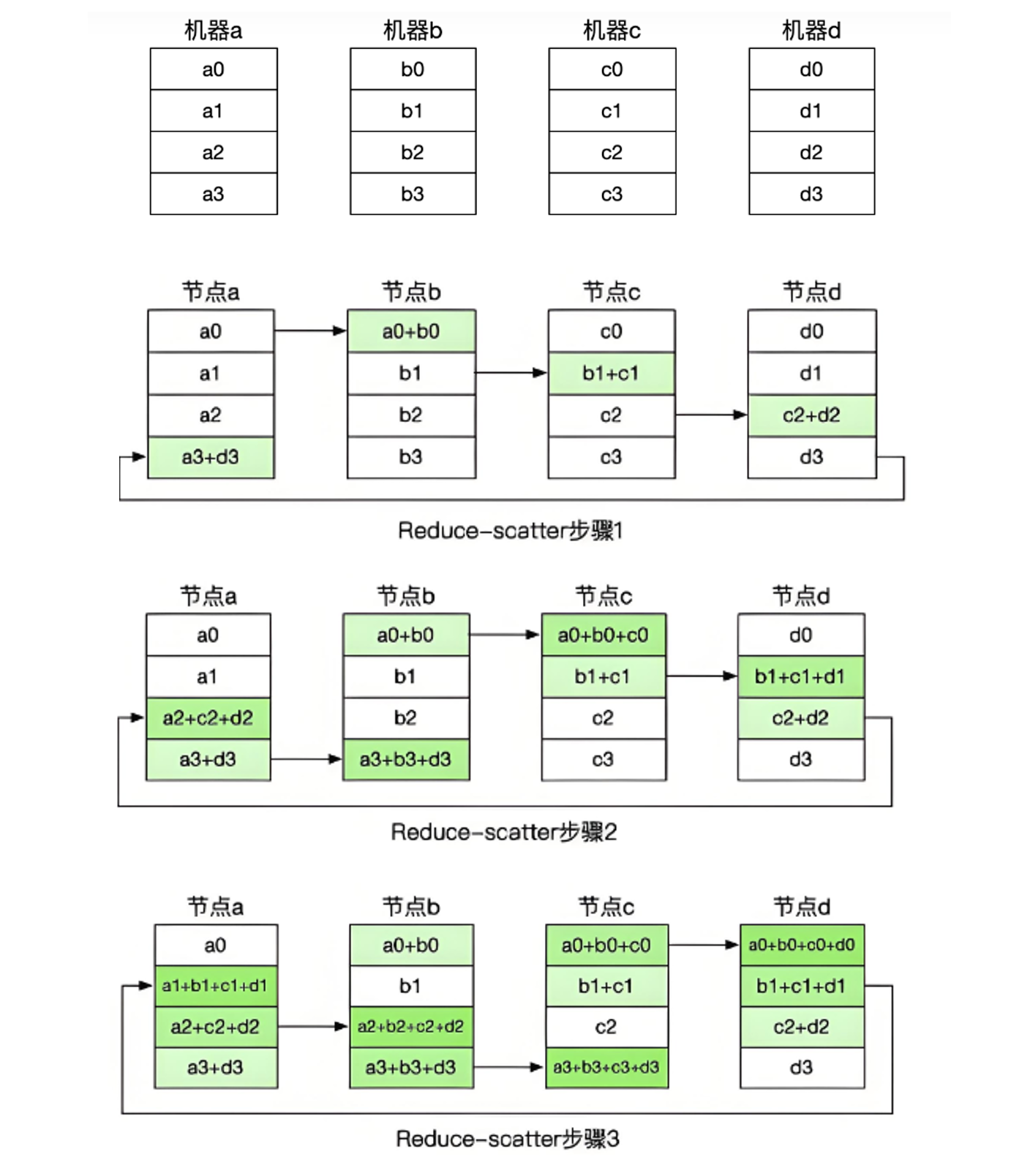
Reduce-Scatter过程使得每个GPU只和其相邻的两块GPU通讯,每次发送对应位置数据所计算的梯度进行累,每一次累加更新都形成一个拓扑环,因此被称为Ring。一次累加完毕后,箭头指向位置的数据块被更新,被更新的数据块将成为下一次更新的起点,继续做累加操作。3次更新之后,每块GPU上都有一块数据拥有了对应位置完整聚合的梯度。
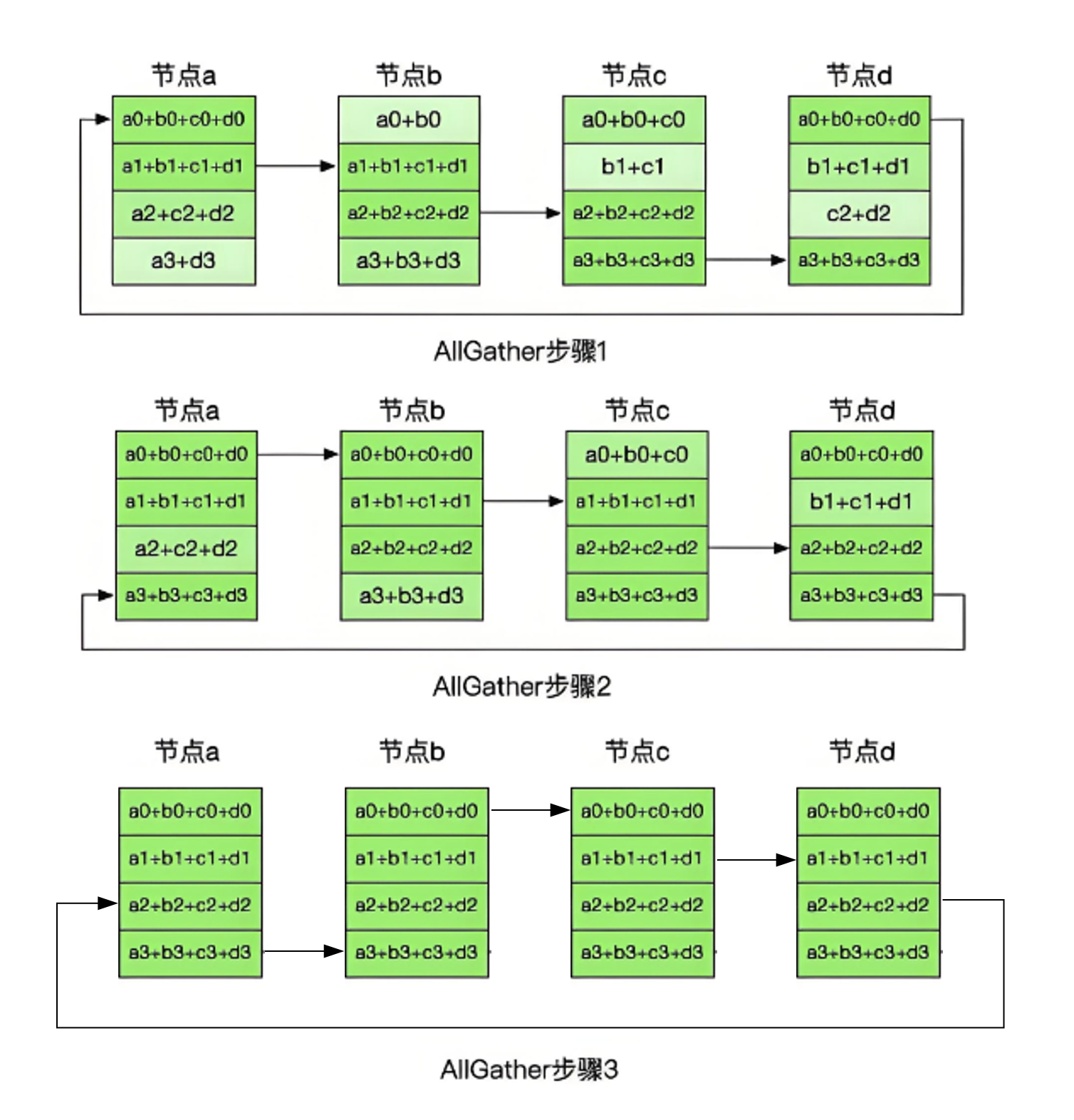
此时,Reduce-Scatter阶段结束,进入All-Gather阶段,目标是把完整数据块Broadcast到其余GPU对应的位置上。如名字里Gather所述的一样,这操作里依然按照“相邻GPU对应位置进行通讯”的原则,但对应位置数据不再做相加,而是直接替换。以此类推,同样经过3轮迭代后,使得每块GPU上都汇总到了完整数据所训练得到的梯度值以供更新,这时每个机器上的模型都进行同等程度都更新。
DP与DDP与通讯量相同,但搬运相同数据量的时间却不一定相同。DDP把通讯量均衡负载到了每一时刻的每个Worker上,而DP仅让master做勤劳的搬运工,当有越来越多的GPU时,DP的通讯时间是会增加的遇到瓶颈的。
总结
- 在DP中,每个GPU上都拷贝一份完整的模型,每个GPU上处理batch的一部分数据,所有GPU算出来的梯度传到master进行累加后,再传回各GPU用于更新参数
- DDP通过定义网络环拓扑的方式,将通讯压力均衡地分到每个GPU上,使得跨机器的数据并行(DDP)得以高效实现
- DP和DDP的总通讯量相同,但因负载不均的原因,DP需要耗费更多的时间搬运数据
最后请大家记住Ring-AllReduce的方法,因为在之后的ZeRO、Megatron-LM中,它将频繁地出现,是分布式训练系统中重要的算子。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)