大模型之SAM-Adapter系列《SAM Fails to Segment Anything?-SAM-Adapter:Adapting SAM in Underperformed Scenes》
*大型模型(也称为基础模型)的出现为 AI 研究带来了重大进步。Segment Anything (SAM) 就是这样一种模型,它是为图像分割任务而设计的。然而,与其他基础模型一样,我们的实验结果表明,SAM 在某些分割任务中可能会失败或表现不佳,例如阴影检测和伪装物体检测(隐藏物体检测)。这项研究首先为将大型预训练图像分割模型 SAM 应用于这些下游任务铺平了道路,即使在 SAM 表现不佳的情况
paper:https://tianrun-chen.github.io/SAM-Adaptor/
code: http://tianrun-chen.github.io/SAM-Adaptor/
**
Abstract
**
大型模型(也称为基础模型)的出现为 AI 研究带来了重大进步。Segment Anything (SAM) 就是这样一种模型,它是为图像分割任务而设计的。然而,与其他基础模型一样,我们的实验结果表明,SAM 在某些分割任务中可能会失败或表现不佳,例如阴影检测和伪装物体检测(隐藏物体检测)。这项研究首先为将大型预训练图像分割模型 SAM 应用于这些下游任务铺平了道路,即使在 SAM 表现不佳的情况下也是如此。我们提出了 SAM-Adapter,而不是对 SAM 网络进行微调,它通过使用简单而有效的适配器将特定领域的信息或视觉提示整合到分割网络中。通过将特定于任务的知识与大型模型学习到的一般知识相结合,SAM-Adapter 可以显著提升 SAM 在具有挑战性的任务中的表现,这在大量实验中得到了证明。我们甚至可以超越特定于任务的网络模型,并在我们测试的任务中实现最先进的性能:伪装物体检测、阴影检测。我们还测试了息肉分割(医学图像分割),并取得了更好的结果。
我们相信我们的工作为在下游任务中使用 SAM 开辟了机会,并可能应用于各个领域,包括医学图像处理、农业、遥感等。
1.Introduction
随着模型在大规模数据上进行训练,人工智能研究经历了范式转变。 这些模型或称为基础模型,例如 BERT、DALL-E 和 GPT-3,在许多语言或视觉任务中都表现出了良好的效果[1]。最近,在基础模型中,Segment Anything (SAM)[2] 作为在大型视觉语料库上训练的通用图像分割模型,具有独特的地位 [2]。事实证明,SAM 在不同场景中都具有成功的分割能力,这使其成为图像分割和计算机视觉相关领域的突破性进展。 然而,由于计算机视觉涵盖了广泛的问题,SAM 的不完整性显而易见,这与其他基础模型类似,因为训练数据无法涵盖整个语料库,并且工作场景会发生变化 [1]。在本研究中,我们首先在一些具有挑战性的低级结构分割任务中测试了 SAM,包括伪装物体检测(隐蔽场景)和阴影检测,我们发现在这些情况下,加粗样式在一般图像上训练的 SAM 模型无法完美地“分割任何东西”。 因此,一个关键的研究问题是:如何利用大型模型从海量语料库中获得的能力,并利用它们来造福下游任务?在这里,我们介绍了 SAM-Adapter,它是上述研究问题的解决方案。这项开创性的工作是首次尝试将大型预训练图像分割模型 SAM 适应特定的下游任务,并提高性能。正如其名称所示,SAMAdapter 是一种非常简单但有效的适应技术,它利用内部知识和外部控制信号。具体来说,它是一个轻量级模型,可以用相对较少的数据学习对齐,并作为一个额外的网络,从该任务的样本中注入特定于任务的指导信息。使用视觉提示将信息传达给网络 [3, 4],这已被证明能够高效且有效地将冻结的大型基础模型适应许多下游任务,并且只需最少数量的额外可训练参数。 具体来说,我们展示了我们的方法是:
• 可推广:SAM-Adapter 可直接应用于各种任务的定制数据集,在 SAM 的帮助下提升性能。
• 可组合:可轻松组合多个显式条件,通过多条件控制对 SAM 进行微调。
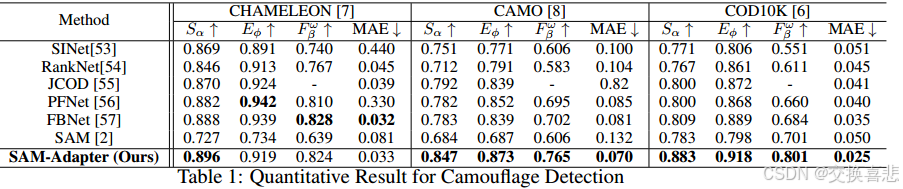
我们对多个任务和数据集进行了广泛的实验,包括用于阴影检测的 ISTD [5] 和用于伪装物体检测任务的 COD10K [6]、CHAMELEON [7]、CAMO [8] 以及用于息肉分割(医学图像分割)任务的 kvasir-SEG [9]。得益于 SAM 和我们的 SAM-Adapter 的功能,我们的方法在两个任务上都实现了最佳 (SOTA) 性能。这项工作的贡献可以总结如下:
• 首先,我们率先分析了 Segment Anything (SAM) 模型作为基础模型的不完备性,并提出了如何利用 SAM 模型服务下游任务的研究问题。
• 其次,我们率先提出了适配方法 SAM-Adapter,使 SAM 适应下游任务并实现性能提升。适配器将特定任务知识与大模型学习到的一般知识相结合。特定任务知识可以灵活设计。
• 第三,尽管 SAM 的主干是一个简单的普通模型,缺乏针对两个特定下游任务量身定制的专门结构,但我们的方法仍然超越了现有方法,并在这些下游任务中取得了最先进的 (SOTA) 性能。
据我们所知,这项工作开创性地展示了 SAM 以惊人的准确度迁移到其他特定数据域的卓越能力。虽然我们只在少数数据集上进行了测试,但我们预计 SAM-Adapter 可以成为医疗和农业等不同领域各种下游分割任务的有效且适应性强的工具。这项研究将开启在不同研究领域和工业应用中使用大型预训练图像模型的新时代。
2.Related Work
- 语义分割:近年来,语义分割取得了重大进步,这主要归功于基于深度学习的方法的显著进步,例如全卷积网络(FCN)、编码器-解码器结构、扩张卷积、金字塔结构、注意模块和变压器。在先前研究的基础上,Segment Anything (SAM) [2] 引入了一个基于大型 ViT 的模型,该模型在大型视觉语料库上进行训练。这项工作旨在利用 SAM 来解决特定的下游图像分割任务。
- 适配器。适配器的概念最早是在 NLP 社区 [31] 中引入的,作为一种工具,它使用紧凑且可扩展的模型为每个下游任务微调大型预训练模型。在 [32] 中,使用在几个特定于任务的参数之间共享的单个 BERT 模型探索了多任务学习。在计算机视觉社区中,[33] 建议以最少的修改对 ViT [34] 进行微调以进行对象检测。最近,ViT-Adapter [35] 利用适配器使普通的 ViT 能够执行各种下游任务。[4] 引入了一种显式视觉提示 (EVP) 技术,该技术可以将显式视觉提示合并到适配器中。但是,之前的研究还没有尝试应用适配器来利用在大型图像语料库上训练的预训练图像分割模型 SAM。 在这里,我们弥补了研究差距。
- 伪装物体检测 (COD) 伪装物体检测或隐藏物体检测是一项具有挑战性但有用的任务,可以识别与周围环境融为一体的物体。 COD 在医学、农业和艺术领域有着广泛的应用。最初,伪装检测研究依赖于纹理、亮度和颜色等低级特征 [36、37、38、39] 来区分前景和背景。值得注意的是,其中一些先验知识对于识别物体至关重要,并用于指导本文中的神经网络。 Le 等人 [8] 首先提出了一个由分类和分割分支组成的端到端网络。基于深度学习的方法的最新进展显示出检测复杂伪装物体的卓越能力 [6、40、41]。在这项工作中,我们利用先进的神经网络主干(基础模型 - SAM)和特定于任务的先验知识的输入来实现最先进的 (SOTA) 性能。
- 阴影检测 当物体表面没有直接暴露在光线下时,就会出现阴影。 它们提供有关光源方向和场景照明的提示,有助于场景理解 [42, 43]。它们还会对计算机视觉任务的性能产生负面影响 [44, 45]。早期方法使用手工制作的启发式线索,如色度、强度和纹理 [46, 43, 47]。深度学习方法利用从数据中学习到的知识,并使用精心设计的神经网络结构来捕获信息(例如学习到的注意力模块)[48, 49, 50]。这项工作利用大型神经网络模型的启发式先验来实现最先进的 (SOTA) 性能。
3.Methods
3.1 Using SAM as the Backbone
如前所述,SAM-Adapter 的目标是利用从 SAM 中学到的知识。因此,我们使用 SAM 作为分割网络的骨干。SAM 的图像编码器是一个 ViT-H/16 模型,具有 14x14 窗口注意力和四个等距全局注意力块。我们保持预训练图像编码器的权重不变。我们还利用 SAM 的掩码解码器,它由一个经过修改的转换器解码器块和一个动态掩码预测头组成。我们使用预训练的 SAM 的权重来初始化我们方法的掩码解码器的权重,并在训练期间调整掩码解码器。我们没有向 SAM 的原始掩码解码器输入任何提示。
3.2 Adapters
接下来,通过适配器学习特定于任务的知识 F i 并将其注入网络。我们采用了提示的概念,利用了基础模型已在大规模数据集上训练的事实。使用适当的提示来引入特定于任务的知识 [4] 可以增强模型在下游任务上的泛化能力,尤其是在注释数据稀缺的情况下。
提出的 SAM-Adapter 的架构如图 1 所示。我们的目标是保持适配器设计的简单和高效。因此,我们选择使用仅由两个 MLP 和两个 MLP 内的激活函数组成的适配器 [4]。具体来说,适配器获取信息 F i 并获得提示 P i :其中 MLPi tune 是用于为每个适配器生成特定于任务的提示的线性层。MLPup 是所有适配器共享的上投影层,用于调整变压器特征的维度。 P i 是指附加到 SAM 模型的每个变压器层的输出提示。 GELU 是 GELU 激活函数[51]。信息 F i 可以选择多种形式。
3.3 Input Task-Specific Information
值得注意的是,信息 F i 可以根据任务的不同而采用各种形式,并且可以灵活设计。例如,它可以以某种形式从任务特定数据集的给定样本中提取出来,例如纹理或频率信息,或者一些手工制作的规则。此外,F i 可以是包含多个指导信息的复合形式: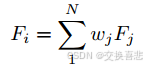
其中 F j 可以是一种特定类型的知识/特征,而 w j 是一个可调节的权重,用于控制组合强度。
4.Experiments
4.2 Implementation Details
实验中选择patch embedding和高频分量high frequency components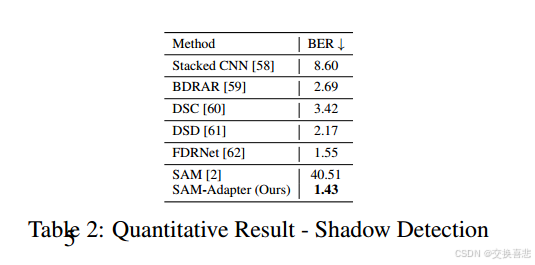




魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)