机器学习笔记-决策树-基本原理
前言
决策树算法是及其学习中最经典、最基础的算法之一。我们需要掌握,以下介绍关于决策树的一些基本原理。
一、决策树原理
问:决策树能干什么?
答:当然是分类!
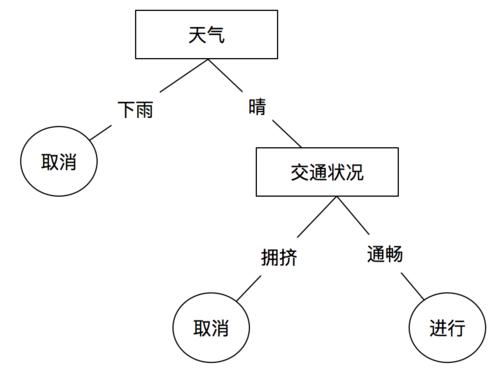
到底明天是不是要去开会??对其进行简单的分支
1.决策树基本概念
先了解树的结构
根节点:第一次划分数据的地方(天气)
叶子节点:数据的最终决策结果(上图的取消、进行)
非叶子节点与分支:中间过程各个节点
2.衡量标准
熵:物体内部的混乱程度,熵值越高,混乱程度越高
举例:你去百货大楼买衣服,发现衣服有Nike、Adidas、A21等等,你买哪款牌子的衣服似乎不确定性就高了,但是你去Nike专卖店,你似乎就只能买Nike。这就是混乱度越低,不确定性就越低。
熵公式:
Gini系数:
3.信息增益
我们划分节点,是希望熵值降低,那么划分的前后节点,之间存在一个信息熵的差异,通过计算前后节点的信息熵,得到的信息增益
4.决策树构造实例
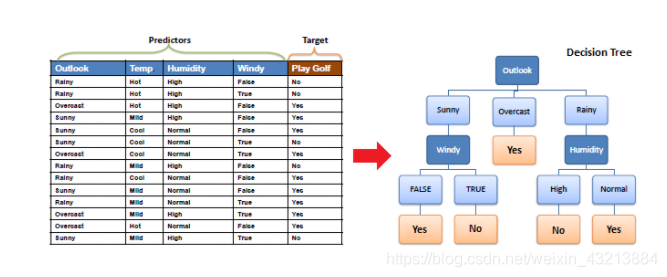
图片来源:https://www.sohu.com/a/229947064_295682
14条关于天气状况,决定是否外出打球?
outlook:取值sunny、rainy、overcast
temperature:取值hot、cool、mild
humidity:取值high、normal
windy:取值True、False
·先将4个特征均按根节点划分。然后计算其熵值。以outlook举例:
首先:9天打球、5天不打球,最初的信息熵为:
紧接着:outlook=sunny 熵值为0.971
outlook=overcast 熵值为0(全都是出去打球)
outlook=rainy 熵值0.971
outlook取值为sunny、overcast、rainy的概率分别为5/14、4/14、5/14,对outlook取加权平均得到outlook的最终熵值
信息增益:0.940-0.693=0.247
重复以上步骤,计算其余三个特征的熵和信息增益,gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048,选信息增益最大的,即是outlook作为根节点。
5.连续值问题
对连续形数据(身高、体重)需要找到最合适的特征以及最合适的特征分点。
确定最合适的特征分点:x = [1,2,3,4,5,6,7,8],首先在1,2之间以1.5作为切分点,计算熵值,接着在2,3以2.5切分,计算熵值,选择信息增益最大的,作为最终的切分点。
6.信息增益率
信息增益率:
ID3基于信息增益构建方法
C4.5信息增益比率,处理特征比较分散的特征,将自身熵值作为分母,信息增益作为分子,信息增益比较大,但是由于自身熵值更大,整体的信息增益率就会变小。
7.回归问题求解
说明白就是,转换衡量标准。分类任务是熵值下降最多,回归只需找出方差最小。取平均值最为预测结果。
二、决策树剪枝策略
为什么要剪枝???
会造成过拟合!
1.剪枝策略
| 预剪枝(Pre-Pruning) | 构造时进行剪枝 | 限制树的复杂程度,停止条件:树的层数、叶子节点个数、信息增益阈值 |
| 后剪枝(Post-Pruning) | 构造完成时 |
C(T)当前熵值, |
2.决策树算法涉及参数
参见Sklearn中文手册
http://www.scikitlearn.com.cn/

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)