机器学习——KNN算法流程详解(以iris为例)
1.数据获取。要进行KNN,我们需要样本的部分属性完整数据以及在各种属性不同值的组合情况下的对应分类结果2.数据清洗。获取数据后使用numpy整理缺失值,可视化查看是否有异常值(比如偏正态分布样本出现的极端值或者空值)3.数据切分。将数据按照一定比例,从特定位置切分成训练集和测试集,必要情况还需要切割分一部分数据作为验证集4.选取k个近邻点。使用某种数据结构或者库函数,获取逻辑距离最近的k个点位5
、
目 录
前情说明
本书基于《特征工程入门与入门与实践》庄家盛 译版P53页K最近邻(KNN)算法进行讲解
问题陈述
Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
sepallength:萼片长度
sepalwidth:萼片宽度
petallength:花瓣长度
petalwidth:花瓣宽度
我们的任务就是:给定一组记录(包含sepallength,sepalwidth,petallength,petalwidth),使用KNN算法给出该组记录的分类 (使用0,1,2表示)
数据说明
本文使用数据源从机器学习库sklearn的datasets包中获取
# 导入iris数据
iris = datasets.load_iris()可支持的数据集如下:
"load_digits",
"load_files",
"load_iris",
"load_breast_cancer",
"load_linnerud",
"load_sample_image",
"load_sample_images",
"load_svmlight_file",
"load_svmlight_files",
"load_wine",
#不知道为什么我的机器学习库只有这些数据集参考链接: sklearn中的datasets数据集 - 知乎 (zhihu.com)
KNN算法流程概述
1.数据获取。要进行KNN,我们需要样本的部分属性完整数据以及在各种属性不同值的组合情况下的对应分类结果
2.数据清洗。获取数据后使用numpy整理缺失值,可视化查看是否有异常值(比如偏正态分布样本出现的极端值或者空值)
3.数据切分。将数据按照一定比例,从特定位置切分成训练集和测试集,必要情况还需要切割分一部分数据作为验证集
4.选取k个近邻点。使用某种数据结构或者库函数,获取逻辑距离最近的k个点位
5.获取结果。对k个点位进行统计,获取票数最多的结果进行分类。但是存在票数一致的情况,可以使用某种排序方式对数据进行排序,隐式的赋予某些特定的数据具有更高的优先级(即返回首位即可)
6.可视化(补充)。虽然使用KNN算法对结果进行展示了,但是整个过程的投票情况不够直观,于是我们接下来将对整体分类和循环内当前投票情况进行展示。
代码实现
from sklearn import datasets
from collections import Counter # 为了做投票计数
from sklearn.model_selection import train_test_split
import random
import numpy as np
###############数据定义区
# 数据集划分随机数种子
randomNums=random.randint(1,9999)
print("随机数{}".format(randomNums))
# 最短投票对象数量
k=3
###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet,DataSet):
# print("打印欧氏距离")
# print(toBeMeasuredDataSet,'\n',DataSet)
# **2的妙用
result=np.sqrt(np.sum((toBeMeasuredDataSet - DataSet)**2 ))
# print("打印欧氏距离",result)
return result
# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X,Y,k,testObject):
# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集
distanceList=[calcDistance(testObject,singleData) for singleData in X ]
# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)
theShortestIndex=np.argsort(distanceList)[:k]
# 获取这k个结果
resultList=Y[theShortestIndex]
# 返回频率最高的结果 作为样本的类别
return Counter(resultList).most_common(1)[0][0]
def printTopLineA():
print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")
def printTopLineB():
print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")
# 导入鸾尾花数据集
irisDataSet=datasets.load_iris()
#获取特征数据集
characteristicData=irisDataSet.data
# 获取分类数据集
categoricalData=irisDataSet.target
# 训练用特征数据集
# 测试用特征数据集
# 训练用分类数据集
# 测试用分类数据集
trainCharDataSet,testCharDataSet,trainCateDataSet,testCateDaSet\
=train_test_split(characteristicData,categoricalData,random_state=randomNums)
for index,i in enumerate(testCharDataSet):
print("第{}个数据\n特征数据是:{}\n数据的类别是:{}".format(index+1,i,KNNSelect(trainCharDataSet,trainCateDataSet,k,i)))
if (index&1):
printTopLineA()
else:
printTopLineB()运行结果

基于可视化的改进
我们还是从源数据入手,将源数据转换成key-value聚合的形式,
具体点就是将同一类数据打成列表,作为以列名为key的对应的value
运行网址:Replit: the collaborative browser based IDE - Replit
可视化代码
from collections import Counter # 为了做投票计数
from sklearn import datasets
from sklearn.model_selection import train_test_split
import random
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
###############说明
# 1.本地sns画图环境炸了,具体原因不详,运行平台为Replit,复制即可运行
# 2.参考了许多可视化案例,但大部分都没有理论支撑,就自己做了
###############数据定义区
# 数据集划分随机数种子
randomNums=random.randint(1,9999)
print("随机数{}".format(randomNums))
# 最小投票对象数量
k=9
###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet,DataSet):
# print("打印欧氏距离")
# print(toBeMeasuredDataSet,'\n',DataSet)
# **2的妙用
result=np.sqrt(np.sum((toBeMeasuredDataSet - DataSet)**2 ))
# print("打印欧氏距离",result)
return result
#这个方法会传来收集好的k个数据以及分类结果 然后返回成key-value的形式调用进行可视化
def showVisual(irisData,irisTarget):
#数据处理
irisDictData = {
'sepalLength': [],
'sepalWidth': [],
'petalLength': [],
'petalWidth': []
}
for index, i in enumerate(irisDictData):
# print(index,i,irisDictData[i])
#将每一列数据剥离出来
irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]
#将分类结果添加进来
irisDictData['species']=irisTarget
# 进行可视化
visual(irisDictData)
# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X,Y,k,testObject):
# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集
distanceList=[calcDistance(testObject,singleData) for singleData in X ]
# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)
theShortestIndex=np.argsort(distanceList)[:k]
# 获取这k个源数据和结果
dataList=X[theShortestIndex]
resultList=Y[theShortestIndex]
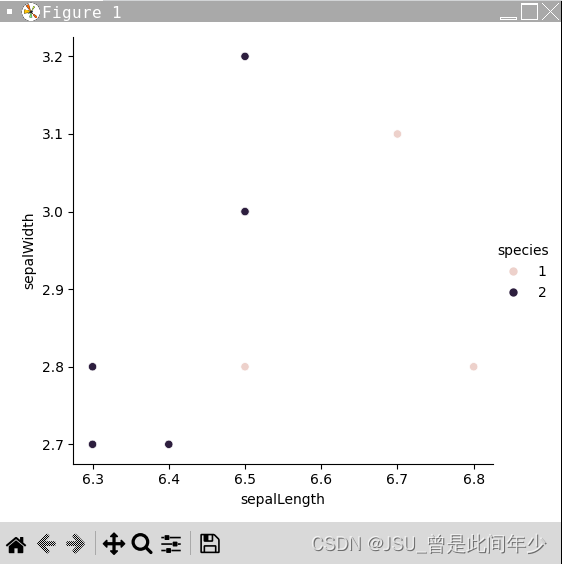
print("投票结果:{}".format(resultList))
##########可视化出最近的k个点
showVisual(dataList,resultList)
# 返回频率最高的结果 作为样本的类别
return Counter(resultList).most_common(1)[0][0]
def showNcolsData():
# 导入鸾尾花数据集
irisDataSet = datasets.load_iris()
# 分析花瓣与花萼的相关性
# 宽度的相关性
# 高度的相关性
# data是采集数据 target是人工分好的类别数据
irisData = irisDataSet["data"]
# print(irisData[0][0])
irisDictData = {
'sepalLength': [],
'sepalWidth': [],
'petalLength': [],
'petalWidth': []
}
for index, i in enumerate(irisDictData):
# print(index,i,irisDictData[i])
#将每一列数据剥离出来 注意这里用的下标是index 而不是indexs哈哈
#感觉写的时候自己挺聪明,过两天就看不懂了qwq
irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]
# k2, p = stats.normaltest(irisDictData[i])
# print(k2,p)
# 添加预测结果数据
irisDictData['species']=irisDataSet['target']
return irisDictData
# 装饰打印语句
def printTopLineA():
print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")
def printTopLineB():
print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")
#可视化函数
def visual(rawData):
# 传入一个没有被DataFrame的
dfData=pd.DataFrame(rawData)
# x X轴展示数据
# y Y轴展示数据
# data 数据源
# hub 颜色分类依据列
# 分类总览
sns.relplot(x='sepalLength',y='sepalWidth',data=dfData,hue='species')
plt.show()
# 导入鸾尾花数据集
irisDataSet=datasets.load_iris()
#获取特征数据集
characteristicData=irisDataSet.data
# 获取分类数据集
categoricalData=irisDataSet.target
# print("打印分类结果",categoricalData)
# 训练用特征数据集,测试用特征数据集,训练用分类数据集,测试用分类数据集
trainCharDataSet,testCharDataSet,trainCateDataSet,testCateDaSet\
=train_test_split(characteristicData,categoricalData,random_state=randomNums)
# 可视化需求分析
# 1.对训练集数据进行可视化
# 2.对每个测试对象展示一个独特的点
# 3.标出待测对象最近的k个点
# 每一列key的字典 对应值是该列数据
irisDictData=showNcolsData()
# sepalLength sepalWidth petalLength petalWidth
# print(dfData)
visual(irisDictData) #对整体进行可视化
###使用循环处理待测数据 并给出结果
for index,i in enumerate(testCharDataSet):
print("第{}个数据\n特征数据是:{}\n数据的类别是:{}"\
.format(index+1,i,KNNSelect(trainCharDataSet,trainCateDataSet,k,i)))
printTopLineA() if index&1 else printTopLineB()全部数据可视化总览
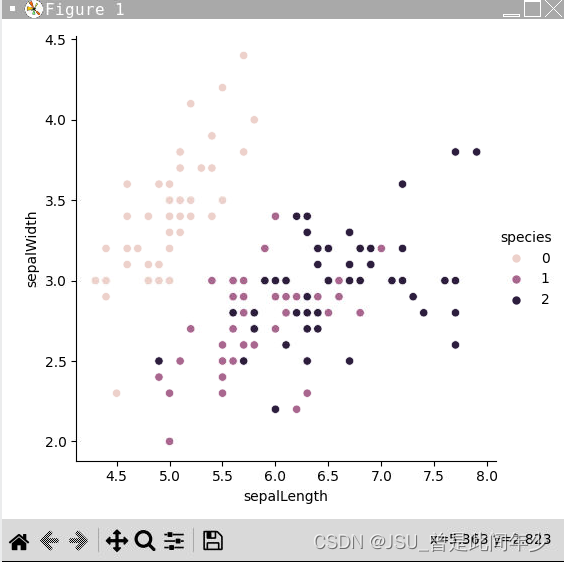
分类投票结果
改进后最终代码
我们对代码进行优化,整理后最终代码如下,可在如上在线平台直接运行
from collections import Counter # 为了做投票计数
from sklearn import datasets
from sklearn.model_selection import train_test_split
import random
import numpy as np
import pandas as pd
import seaborn as sns #流行可视化工具
import matplotlib.pyplot as plt #sns的底层基于这个。。。需要用plt.show()
###############说明
# 1.本地sns画图环境炸了,具体原因不详,运行平台为Replit,复制即可运行
# 2.参考了许多可视化案例,但大部分都没有理论支撑,就自己做了
###############数据定义区
# 数据集划分随机数种子
randomNums = random.randint(1, 9999)
print("随机数{}".format(randomNums))
# 最小投票对象数量
k = 9
# 定义空字典 增加复用率
irisDictEmptyData = {
'sepalLength': [],
'sepalWidth': [],
'petalLength': [],
'petalWidth': []
}
###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet, DataSet):
# print("打印欧氏距离")
# print(toBeMeasuredDataSet,'\n',DataSet)
# **2的妙用
result = np.sqrt(np.sum((toBeMeasuredDataSet - DataSet) ** 2))
# print("打印欧氏距离",result)
return result
def dealRawDataToDict(irisDictData, irisData):
for index, i in enumerate(irisDictData):
# print(index,i,irisDictData[i])
# 将每一列数据剥离出来 注意这里用的下标是index 而不是indexs哈哈
# 感觉写的时候自己挺聪明,过两天就看不懂了qwq
irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]
return irisDictData
# 这个方法会传来收集好的k个数据以及分类结果 然后返回成key-value的形式调用进行可视化
def showVisual(irisData, irisTarget):
# 数据处理
irisDictData = dealRawDataToDict(irisDictEmptyData, irisData)
# 将分类结果添加进来
irisDictData['species'] = irisTarget
# 进行可视化
visual(irisDictData)
# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X, Y, k, testObject):
# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集
distanceList = [calcDistance(testObject, singleData) for singleData in X]
# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)
theShortestIndex = np.argsort(distanceList)[:k]
# 获取这k个源数据和结果
dataList = X[theShortestIndex]
resultList = Y[theShortestIndex]
print("投票结果:{}".format(resultList))
##########可视化出最近的k个点
showVisual(dataList, resultList)
# 返回频率最高的结果 作为样本的类别
return Counter(resultList).most_common(1)[0][0]
#拼装全部原始数据 然后送还字典
def showNcolsData():
# 导入鸾尾花数据集
irisDataSet = datasets.load_iris()
# 分析花瓣与花萼的相关性
# 宽度的相关性
# 高度的相关性
# data是采集数据 target是人工分好的类别数据
irisData = irisDataSet["data"]
# print(irisData[0][0])
irisDictData = dealRawDataToDict(irisDictEmptyData, irisData)
# 添加预测结果数据
irisDictData['species'] = irisDataSet['target']
return irisDictData
# 装饰打印语句
def printTopLineA():
print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")
def printTopLineB():
print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")
# 可视化函数
def visual(rawData):
# 传入一个没有被DataFrame的
dfData = pd.DataFrame(rawData)
# x X轴展示数据
# y Y轴展示数据
# data 数据源
# hub 颜色分类依据列
# 分类总览
sns.relplot(x='sepalLength', y='sepalWidth', data=dfData, hue='species')
plt.show()
# 导入鸾尾花数据集
irisDataSet = datasets.load_iris()
# 获取特征数据集
characteristicData = irisDataSet.data
# 获取分类数据集
categoricalData = irisDataSet.target
# print("打印分类结果",categoricalData)
# 训练用特征数据集,测试用特征数据集,训练用分类数据集,测试用分类数据集
trainCharDataSet, testCharDataSet, trainCateDataSet, testCateDaSet \
= train_test_split(characteristicData, categoricalData, random_state=randomNums)
# 可视化需求分析
# 1.对训练集数据进行可视化
# 2.对每个测试对象展示一个独特的点
# 3.标出待测对象最近的k个点
# 每一列key的字典 对应值是该列数据
irisDictData = showNcolsData()
# sepalLength sepalWidth petalLength petalWidth
# print(dfData)
visual(irisDictData) # 进行可视化
###使用循环处理待测数据 并给出结果
for index, i in enumerate(testCharDataSet):
print("第{}个数据\n特征数据是:{}\n数据的类别是:{}" \
.format(index + 1, i, KNNSelect(trainCharDataSet, trainCateDataSet, k, i)))
printTopLineA() if index & 1 else printTopLineB()部分参考链接:
1.sklearn数据集——iris鸢尾花数据集_iris 数据_lyb06的博客-CSDN博客
2.【机器学习实战】科学处理鸢尾花数据集_鸢尾花数据标准化处理-CSDN博客
4.Python collections模块之Counter()详解_python counter-CSDN博客
5.Python基本函数:np.argsort()-CSDN博客
6.Python中的Counter.most_common()方法-CSDN博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)