机器学习(14)逻辑回归(实战) -- 癌症分析
如果不做数据处理直接划分,会出现如下的错误:ValueError: Found input variables with inconsistent numbers of samples: [697, 699]
·
目录
试错
这里必须要做对缺失数据的处理,否则会报错:
ValueError: could not convert string to float: '?'
所以我们需要进行这一步,缺失数据处理:
# 2、缺失数据处理
data = data.replace(to_replace='?', value = np.nan)
data.dropna(inplace=True)一、读取数据
# 1、读取数据
column_name=['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape',
'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli',
'Mitoses','Class']
pd.set_option('display.max_columns',1000) # 设置最大列数
pd.set_option('display.max_rows',1000) # 设置最大行数
data=pd.read_csv('breast-cancer-wisconsin.data', names=column_name)
print(data)注:为了看到数据的全貌,我对可显示行列做了一个拓展。
pd.set_option('display.max_columns',1000) # 设置最大列数
pd.set_option('display.max_rows',1000) # 设置最大行数处理前的结果:
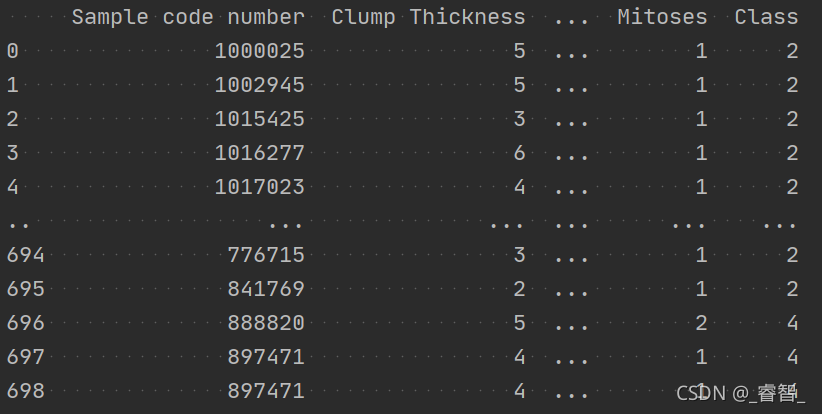
处理后的结果:
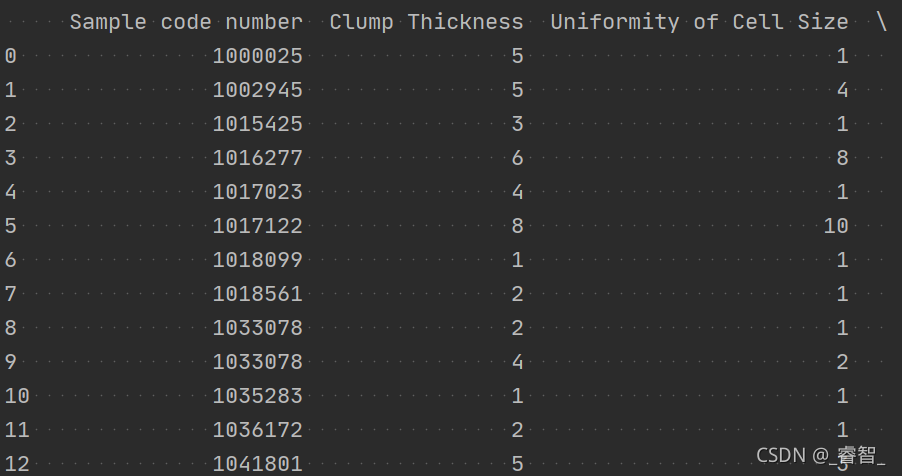
二、划分数据集
训练集舍弃掉首行和末行(编号之类的没有训练价值)
# 3、划分数据集
train = data.iloc[:, 1:-1]
target = data['Class']
train_data, test_data, train_target, test_target = train_test_split(train, target)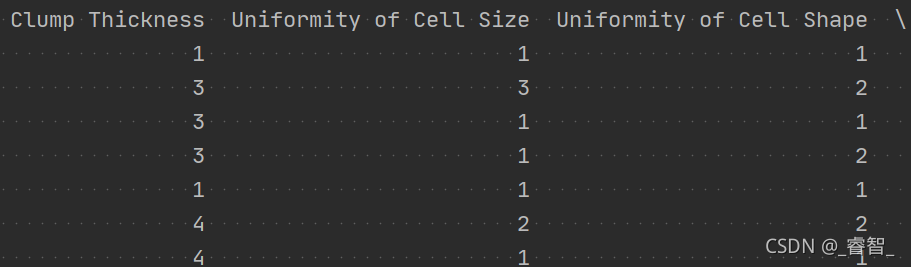
三、对训练集和测试集标准化
# 4、标准化(训练集和测试集)
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)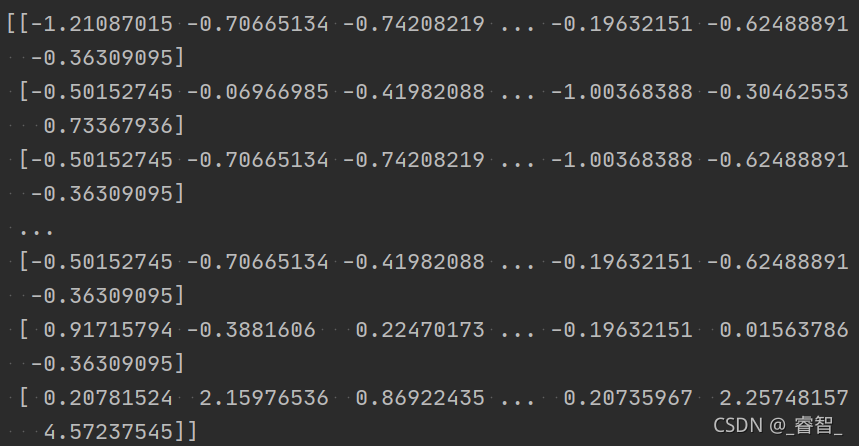
四、创建逻辑回归预估器,训练得到模型
# 5、创建逻辑回归预估器
estimator = LogisticRegression()
estimator.fit(train_data, train_target)逻辑回归预估器训练得到的模型:
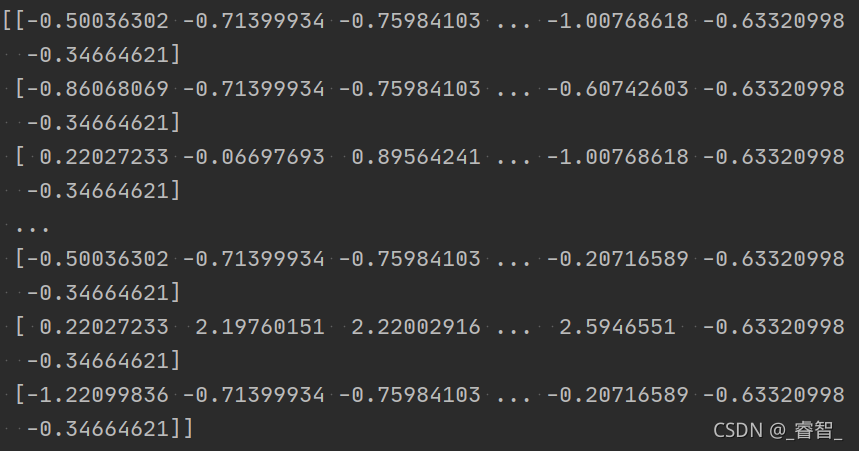
查看逻辑回归的回归系数和偏置:
# 查看模型参数:回归系数 和 偏置
print('回归系数:', estimator.coef_)
print('偏置:', estimator.intercept_)
五、模型评估
# 6、模型评估
# 方法一:比对
predict = estimator.predict(test_data)
print(predict==test_target)
# 方法二:计算正确率
score = estimator.score(test_data, test_target)
print('逻辑回归分类正确率为:', score)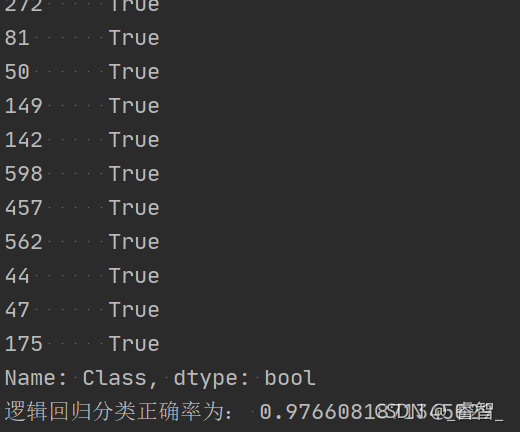
总代码
# 逻辑回归:癌症分类
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 1、读取数据
column_name=['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape',
'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli',
'Mitoses','Class']
pd.set_option('display.max_columns',1000) # 设置最大列数
pd.set_option('display.max_rows',1000) # 设置最大行数
data=pd.read_csv('breast-cancer-wisconsin.data', names=column_name)
# print(data)
# 2、缺失数据处理
data = data.replace(to_replace='?', value = np.nan)
data.dropna(inplace=True)
# 3、划分数据集
train = data.iloc[:, 1:-1]
target = data['Class']
train_data, test_data, train_target, test_target = train_test_split(train, target)
# print(train_data)
# 4、标准化(对训练集和测试集标准化)
transfer = StandardScaler()
train_data = transfer.fit_transform(train_data)
test_data = transfer.transform(test_data)
# print(train_data)
# 5、创建逻辑回归预估器
estimator = LogisticRegression()
estimator.fit(train_data, train_target)
# print(train_data)
# 查看模型参数:回归系数 和 偏置
print('回归系数:', estimator.coef_)
print('偏置:', estimator.intercept_)
# 6、模型评估
# 方法一:比对
predict = estimator.predict(test_data)
print(predict==test_target)
# 方法二:计算正确率
score = estimator.score(test_data, test_target)
print('逻辑回归分类正确率为:', score)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)