等产量曲线中r_机器学习分类模型评估(三)-F值(F-Measure)、AUC、P-R曲线
概述上二篇文章分别讲述了准确率(accuracy)、精确率(Precision)、查准类、召回率(Recall)、查全率、ROC曲线,本文讲述机器学习分类模型评估中的F值(F-Measure)、AUC、P-R曲线。F值(F-measure)F值(又称为F-Score)定义为‘精确率’和‘召回率’的调和平均。当参数α=1时,就是最常见的F1,也即可知F1综合了P和R的结果,当F1较高时则能说明试验方
概述
上二篇文章分别讲述了准确率(accuracy)、精确率(Precision)、查准类、召回率(Recall)、查全率、ROC曲线,本文讲述机器学习分类模型评估中的F值(F-Measure)、AUC、P-R曲线。
F值(F-measure)
F值(又称为F-Score)定义为‘精确率’和‘召回率’的调和平均。
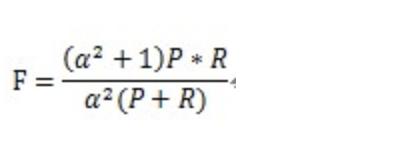
当参数α=1时,就是最常见的F1,也即
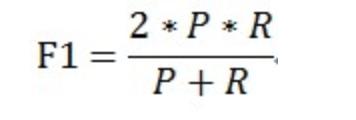
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
AUC
当绘制完成曲线后,就会对模型有一个定性的分析,如果要对模型进行量化的分析,此时需要引入一个新的概念,就是AUC(Area under roc Curve)面积,这个概念其实很简单,就是指ROC曲线下的面积大小,而计算AUC值只需要沿着ROC横轴做积分就可以了。真实场景中ROC曲线一般都会在y=x这条直线的上方,所以AUC的取值一般在0.5~1之间。AUC的值越大,说明该模型的性能越好。
AUC的计算
ROC曲线下方由梯形组成,矩形可以看成特征的梯形。因此,AUC的面积可以这样算:(上底+下底)* 高 / 2,曲线下面的面积可以由多个梯形面积叠加得到。AUC越大,分类器分类效果越好。
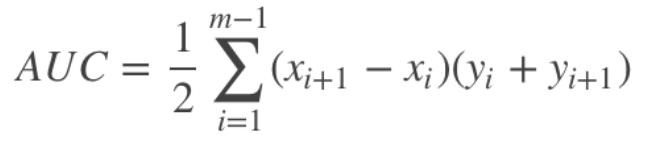
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样,模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
P-R曲线
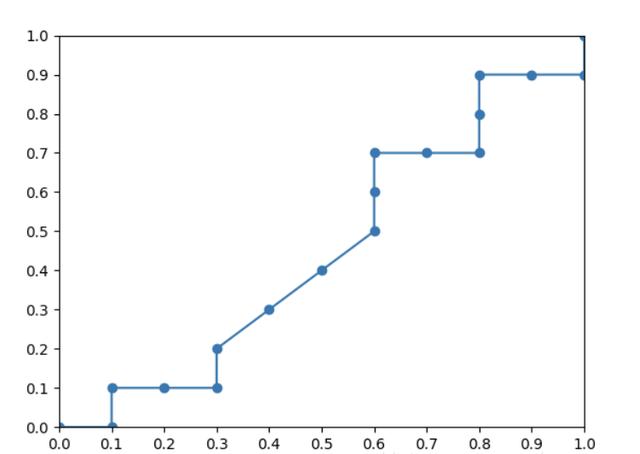
P-R曲线中,P为图中precision,即精准度,R为图中recall,即召回率。将样本按照预测为正例的概率值从大到小进行排序,从第一个开始,逐个将当前样本点的预测值设置为阈值,有了阈值之后,即可得出混淆矩阵各项的数值,然后计算出P和R,以R为横坐标,P为纵坐标,绘制于图中,即可得出P-R曲线,示意图如下。
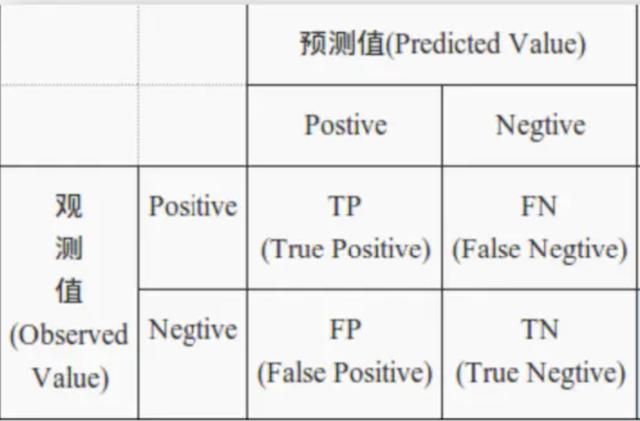
混淆矩阵
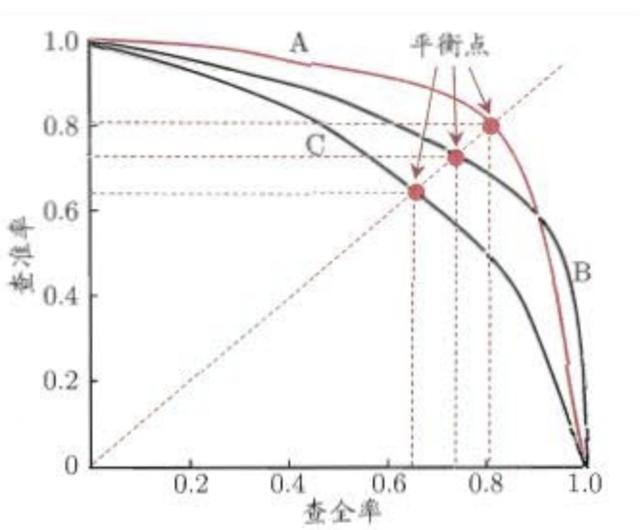
P-R曲线
根据P-R曲线来评估模型的性能:
(1)若一个学习模型的P-R曲线完全包住另一个学习模型的P-R曲线,则前者的性能优于后者。即查全率相同的情况下,查准率越高模型的泛化性能越好,如模型A优于模型B。
(2)若两个学习模型的P-R曲线互相交叉,则可通过“平衡点”(Break-Event Point,简称BEP)来评价模型的优劣,BEP是“查准率=查全率”的数值。由上图可知,模型A的平衡点大于模型B的平衡点,即模型A优于B。
(3) 由于BEP过于简化,更常用的是F1度量:
F1越大,性能越好。
(4) F1度量认为查全率和查准率的重要性程度一样,若考虑到查全率和查准率的重要性程度不一样,如推荐给用户的信息尽可能是用户感兴趣的,那么查准率更重要;抓捕逃犯时更希望尽可能少漏掉逃犯,此时查全率更重要(概念有点模糊的可以参考查准率和查全率公式)。
为了描述查准率和查全率的相对重要程度,则用F1度量的一般形式:Fβ。
其中,β> 0度量了查全率对查准率的相对重要性,β=1时退化为标准的F1;β>1时查全率更重要;β<1时查准率更重要。
相比于其他的P-R曲线(精确度和召回率),ROC曲线有一个巨大的优势就是,当正负样本的分布发生变化时,其形状能够基本保持不变,而P-R曲线的形状一般会发生剧烈的变化,因此该评估指标能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)