【深度学习笔记】Logistic 模型求解
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下:
https://mooc.study.163.com/course/2001281002
也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
目录
1 梯度下降法

在 Logistic 模型中,代价函数 是关于参数
和
的函数,
这里的目标是寻找参数 和
,使得
达到最小。
是关于
和
的凸函数(Convex function),因此可以使用梯度下降法寻找参数的最优值。梯度下降法的思路是:从随机的初始点开始,然后朝下降速度最快(负梯度)的方向前进,迭代若干次数,或者收敛到某个最优解时停止。
和
的一次迭代公式如下:
式中 称为学习率(Learning rate),用于控制梯度下降法的每一次迭代的步长。
在迭代的过程中,代价函数 沿着负梯度方向不断减小,因此称这种方法为梯度下降法(Gradient Descent Algorithm)。
2 前向传播与反向传播

在 Logistic 模型的训练过程中,存在前向传播和反向传播两个过程。前向传播(Forward propagation)是指从输入 到中间特征
,再到最终输出
的计算过程。前向传播用于计算模型输出值,以及对训练样本的损失函数值。

反向传播(Backward propagation)指损失函数值的偏差,从后往前传播的过程。反向传播用于更新模型参数。
对于单个训练样本,计算损失函数在该样本上的偏导数
参数的迭代步长为

对于 m 个训练样本,成本函数值是 m 个代价函数值的平均值,
迭代步长为
3 向量化技巧
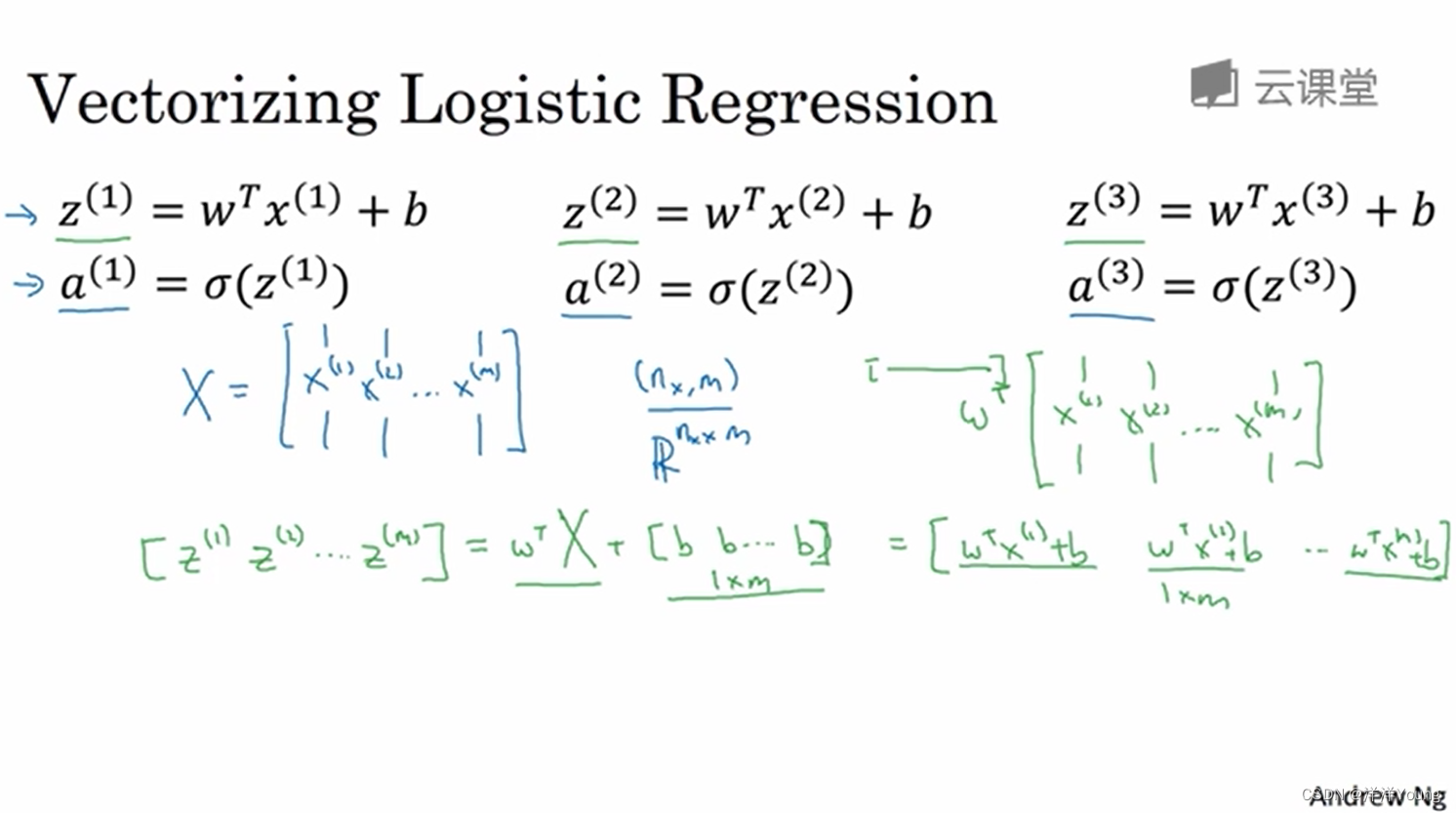

向量化 Logistic 回归,可以同时处理整个训练集,在编写代码时,不出现显式的 for 循环语句。做法是构建一个更大的矩阵 X,矩阵 X 的每一列,是每个样本的特征 ,此时矩阵 X 为一个 nx 行 m 列矩阵,这里 nx 是特征的个数。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)