机器学习实验之逻辑回归
X = np.hstack((np.ones((m, 1)), X)) # 添加偏置项X是一个m×n的特征矩阵,其中m是样本数量,n是特征数量。y是一个长度为m的标签向量。是梯度下降的学习率,控制每次参数更新的步长。iterations是迭代次数,指定梯度下降的更新次数。在函数内部,首先对输入特征矩阵X添加了偏置项,然后初始化参数θ为全零向量。接下来通过迭代更新θ,直到达到指定的迭代次数。在每次迭
目录
一、基本原理
1.逻辑回归基本思想
逻辑回归是一种用于建立分类模型的统计技术,通常用于处理二元分类问题,即将数据分为两个类别。它虽然带有"回归"一词,但实际上是一种分类算法。其主要思想为可简单表示为:
逻辑回归 = 线性回归 + sigmoid函数
2.sigmoid函数
Sigmoid函数,也称为逻辑函数(logistic function),是一种常用的S形函数,通常用于逻辑回归等机器学习算法中。它具有以下形式:
其图像如下:
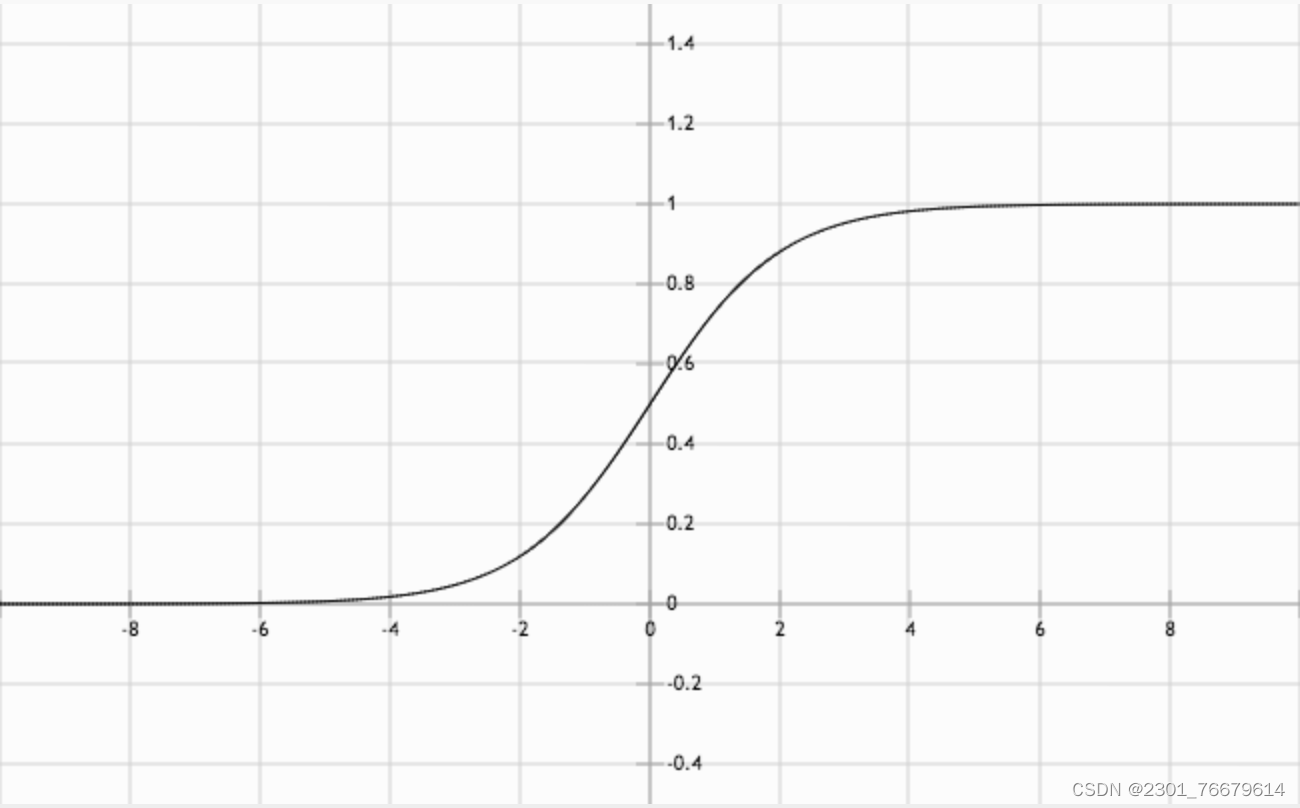
由sigmoid函数表达式以及其图像,我们易知,sigmoid函数值域为(0,1),且图像越靠右则函数返回值越接近1,反之越靠左则越靠近0
根据sigmoid函数的性质,我们可以利用其进行二分类。如图,我们假设图像与y轴交点为(0,0.5),则我们可以把该点右侧的样本点全都看作正类,反之为负类,以此完成二分类
3.线性回归
线性回归是一种用于建立和预测变量之间线性关系的统计技术。它适用于连续型的因变量和自变量,并假设因变量的值可以通过自变量的线性组合来进行预测。
线性回归模型的数学表达式为:
Y = b0 + b1X1 + b2X2 + ... + bn*Xn + ε
其中,Y 表示因变量,X1, X2, ..., Xn 表示自变量,b0, b1, b2, ..., bn 表示模型的系数,ε 表示误差项。
最后可以在坐标轴中拟合出一条直线,设置某个阈值来完成回归任务,我们已知回归直线方程为:
4.核心表达式
我们联立线性回归中的直线方程以及sigmoid函数方程可得逻辑回归核心表达式:
5.损失函数
逻辑回归的损失函数通常使用对数损失函数(Log Loss)来衡量模型的错误率。逻辑回归的损失函数(对数损失函数)定义为:
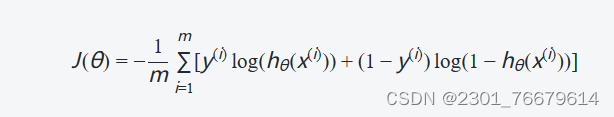
- 当y=1时,第一项ylog(hθ(x)表示真实标签为正类时的损失。
- 当y=0时,第二项(1−y)log(1−hθ(x)表示真实标签为负类时的损失。
- 通过最小化损失函数J(θ),可以利用梯度下降等优化算法来训练逻辑回归模型,找到最佳的参数θ
二、实验功能实现
1.定义sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))2.定义训练函数
def logistic_regression(X, y, learning_rate, iterations):
m, n = X.shape
X = np.hstack((np.ones((m, 1)), X)) # 添加偏置项
theta = np.zeros(n + 1)
for _ in range(iterations):
z = np.dot(X, theta)
h = sigmoid(z)
gradient = np.dot(X.T, (h - y)) / m
theta -= learning_rate * gradient
return thetaX是一个m×n的特征矩阵,其中m是样本数量,n是特征数量。y是一个长度为m的标签向量。learning_rate是梯度下降的学习率,控制每次参数更新的步长。iterations是迭代次数,指定梯度下降的更新次数。
在函数内部,首先对输入特征矩阵X添加了偏置项,然后初始化参数θ为全零向量。接下来通过迭代更新θ,直到达到指定的迭代次数。在每次迭代中,计算预测值ℎ,然后根据预测值和真实标签计算梯度,并利用梯度下降算法更新参数θ。
3.定义预测函数
def predict(X, theta):
X = np.hstack((np.ones((X.shape[0], 1)), X))
predicted_prob = sigmoid(np.dot(X, theta))
predicted_label = (predicted_prob >= 0.5).astype(int)
return predicted_label
这个predict函数接受输入特征矩阵X和训练得到的参数θ,并返回预测的标签值。
在函数内部,首先对输入特征矩阵X添加了偏置项,然后利用训练得到的参数θ计算预测概率值。接着根据概率值大于等于0.5的条件将预测的概率值转换成0或1的标签值,最后将结果返回。
4.绘制逻辑回归图像
def plot_logistic_regression(X, y, theta):
plt.figure()
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='blue', label='Positive Class', marker='o', s=80,
edgecolors='k')
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='red', label='Negative Class', marker='s', s=80, edgecolors='k')
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1), np.arange(x2_min, x2_max, 0.1))
grid = np.c_[xx1.ravel(), xx2.ravel()]
probs = predict(grid, theta).reshape(xx1.shape)
plt.contourf(xx1, xx2, probs, cmap='bwr', alpha=0.6)
# 绘制决策边界
boundary = - (theta[0] + theta[1] * xx1) / theta[2]
plt.plot(xx1[0], boundary[0], color='black', linestyle='-', linewidth=2, label='Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Logistic Regression Decision Boundary')
plt.legend()
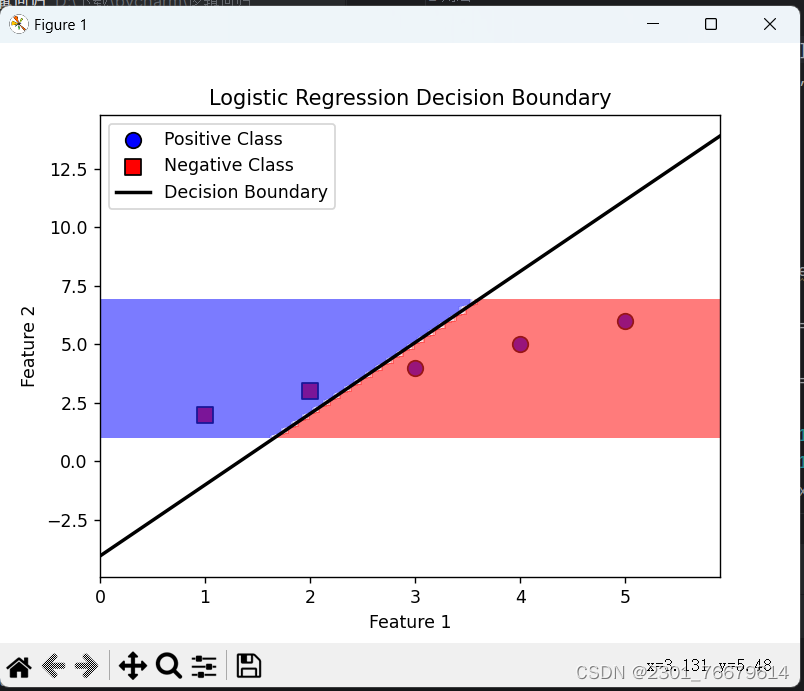
plt.show()训练集如下:
X_train = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y_train = np.array([0, 0, 1, 1, 1])
结果如图:
5.最终实验预测结果如下:
X_new = np.array([[1, 5], [4, 4]])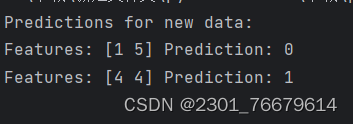
总体代码实现如下:
import numpy as np
import matplotlib.pyplot as plt
# 定义sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义训练函数
def logistic_regression(X, y, learning_rate, iterations):
m, n = X.shape
X = np.hstack((np.ones((m, 1)), X)) # 添加偏置项
theta = np.zeros(n + 1)
for _ in range(iterations):
z = np.dot(X, theta)
h = sigmoid(z)
gradient = np.dot(X.T, (h - y)) / m
theta -= learning_rate * gradient
return theta
# 定义预测函数
def predict(X, theta):
X = np.hstack((np.ones((X.shape[0], 1)), X)) # 添加偏置项
predicted_prob = sigmoid(np.dot(X, theta))
predicted_label = (predicted_prob >= 0.5).astype(int)
return predicted_label
# 定义绘制逻辑回归图像函数
def plot_logistic_regression(X, y, theta):
plt.figure()
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='blue', label='Positive Class', marker='o', s=80,
edgecolors='k')
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='red', label='Negative Class', marker='s', s=80, edgecolors='k')
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1), np.arange(x2_min, x2_max, 0.1))
grid = np.c_[xx1.ravel(), xx2.ravel()]
probs = predict(grid, theta).reshape(xx1.shape)
plt.contourf(xx1, xx2, probs, cmap='bwr', alpha=0.6)
# 绘制决策边界
boundary = - (theta[0] + theta[1] * xx1) / theta[2]
plt.plot(xx1[0], boundary[0], color='black', linestyle='-', linewidth=2, label='Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Logistic Regression Decision Boundary')
plt.legend()
plt.show()
# 准备训练数据
X_train = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y_train = np.array([0, 0, 1, 1, 1])
# 训练模型
learning_rate = 0.1
iterations = 10000
theta = logistic_regression(X_train, y_train, learning_rate, iterations)
# 预测新数据
X_new = np.array([[1, 5], [4, 4]])
predictions = predict(X_new, theta)
print("Predictions for new data:")
for i in range(len(X_new)):
print("Features:", X_new[i], "Prediction:", predictions[i])
# 绘制逻辑回归图像
plot_logistic_regression(X_train, y_train, theta)
三、实验总结
优化方向
1.特征选择:选择与预测目标密切相关的特征,可以增强模型的预测能力。可以考虑使用相关性分析、卡方检验、互信息法等特征选择方法,以选择与目标变量相关性较强的特征。
2.数据预处理:对数据进行预处理可以改善模型的性能。数据预处理包括缺失值处理、异常值处理、数据标准化等。可以使用插值、平均值填充、回归等方法处理缺失值
逻辑回归的优缺点:
优点:
- 实现简单:逻辑回归是一种简单且易于实现的分类算法,适合作为初学者的入门算法。
- 计算代价低:相对于一些复杂的分类算法,逻辑回归的计算代价较低,训练速度快。
- 输出结果易于理解:逻辑回归的输出可以直观地表示样本属于某一类别的概率,便于解释和理解。
缺点:
- 对特征的依赖性:逻辑回归对特征之间的相关性较为敏感,如果特征之间存在多重共线性,可能会影响模型的性能。
- 只能处理线性可分问题:逻辑回归在处理非线性决策边界时表现欠佳,需要通过特征工程或引入高阶特征进行改进。
- 容易受到异常值影响:逻辑回归对异常值较为敏感,可能导致模型的性能下降。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)