李哥深度学习(四)图像分类实战
通过固定种子值,即使代码包含多个随机步骤,也能保证每次执行代码时得到完全一样的结果。方便固定和复现模型训练结果。
一、随机种子的作用
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################通过固定种子值,即使代码包含多个随机步骤,也能保证每次执行代码时得到完全一样的结果。方便固定和复现模型训练结果。
二、给个路径,得到数据
定义一个read_file(path)函数,通过传入的文件路径读到数据
self.X,self.Y = read_file(path)
def read_file(path):#这个函数负责,给他一个路径,把路径中的图片和标签读出来
for i in tqdm(range(11)):#遍历数据集labled下的11个文件夹
file_dir = path + "/%02d"%i
file_list = os.listdir(file_dir)#列出文件夹下所有文件名字
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
yi = np.zeros(len(file_list), dtype=np.uint8)
for j, img_name in enumerate(tqdm(file_list)):#enumerate可以在遍历列表的同时获取当前元素的索引值(j)和元素本身(img_name)
img_path = os.path.join(file_dir, img_name)#相当于把文件夹路径和文件名相加,得到每张图片的路径
img = Image.open(img_path)#打开图片文件
img = img.resize((HW, HW))#重新修改图片尺寸为224*224,适应大多数模型
xi[j, ...] = img
yi[j] = i
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个训练数据"%len(Y))
return X, Yxi,yi是什么?
xi,是本类别文件夹下所有图片的数据,yi是本类别的标签。先初始化为全零矩阵,xi为(文件列表长度)个224*224的3通道全零矩阵,yi为对应标签的(文件列表长度)*1的全零矩阵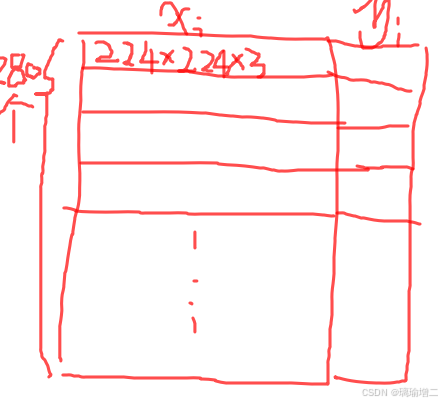 大概是这样
大概是这样
X,Y就是把所有11类的xi,yi堆叠在一起,所以当i为0的时候,X就是第0批的xi,i为1的时候再把X和第1批的xi拼到一起,axis=0表示是沿竖向拼
tqdm的作用是生成可视化的循环进度条
三、数据处理
1、数据增广:模型如果只拿原图片训练,泛化能力会比较差,通过对图像的尺寸、颜色、对比度等改变,来增强模型对多种状态下图像的识别能力
train_transform = transforms.Compose(#数据增广
[
transforms.ToPILImage(), #224, 224, 3转换为模型能接受的 3, 224, 224格式
transforms.RandomResizedCrop(224), #放大然后裁切
transforms.RandomRotation(50),#50度以内随机旋转
transforms.ToTensor()#转化为张量
]
)
val_transform = transforms.Compose(#验证集的图片不要做各种变换,降低准确率
[
transforms.ToPILImage(), #224, 224, 3转换为模型能接受的 3, 224, 224格式
transforms.ToTensor()#转化为张量
]
)四、模型构建
class myModel(nn.Module):
def __init__(self,num_class):
super(myModel,self).__init__()
# 图片尺寸3*224*224 ——》512*7*7 ——》拉直 ——》全连接分类
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) #64个3通道3*3卷积核,步长为1,padding为1 -> 64*224*224
self.bn1 = nn.BatchNorm2d(64)#归一化,通道数为64
self.relu = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential( #sequential能把多个操作合成一层
nn.Conv2d(64, 128, 3, 1, 1), # 128个64通道3*3卷积核,步长为1,padding为1 -> 128*112*112
nn.BatchNorm2d(128), # 归一化,通道数为128
nn.ReLU(),
nn.MaxPool2d(2), # 128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1), # 128个64通道3*3卷积核,步长为1,padding为1 -> 128*112*112
nn.BatchNorm2d(256), # 归一化,通道数为256
nn.ReLU(),
nn.MaxPool2d(2), # 256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1), # 128个64通道3*3卷积核,步长为1,padding为1 -> 128*112*112
nn.BatchNorm2d(512), # 归一化,通道数为256
nn.ReLU(),
nn.MaxPool2d(2), # 512*14*14
)
self.pool2 = nn.MaxPool2d(2) #512*7*7 = 25088
self.fc1 = nn.Linear(25088, 1000)
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000->11
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0], -1) #拉直模型
x= self.fc1(x)
x = self.relu2(x)
x= self.fc2(x)
return x五、超参数
model = myModel(11)
lr = 0.001
loss = nn.CrossEntropyLoss()#loss函数是交叉熵损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
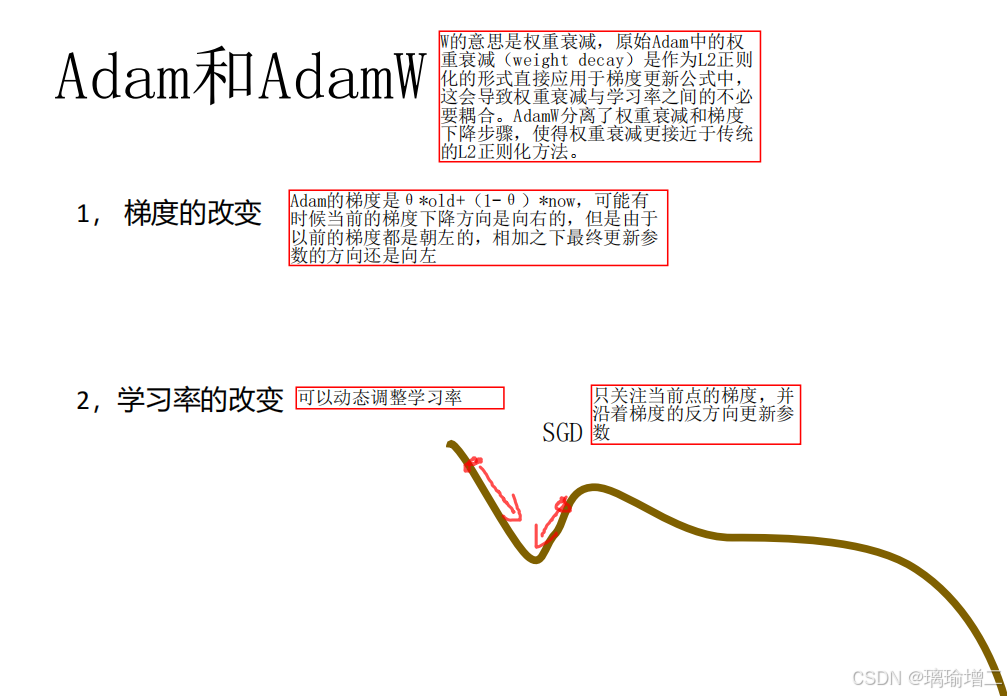
#Adam和AdamW都是模型优化器,或梯度下降算法,是SGD随机梯度下降函数的改进版Adam和AdamW和SGD
六、训练
训练函数在之前回归任务的基础上修改,要增加记录train_acc和val_acc即训练和验证的准确率,以此来评价模型好坏。
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1) == target.cpu().numpy())其中,argmax是源于argsort排序的,能找到最大值对应的下标,axis=1说明方向是矩阵横向

这句代码统计了预测对的数量
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #预测对的数量/数据集总长度得到准确率七、迁移学习
将大佬已训练好的模型拿过来用
#迁移学习
from torchvision.models import resnet18
model = resnet18(pretrained=True)#使用resnet18预训练好的参数,而不是只使用模型架构
in_fetures = model.fc.in_features#获取模型所提取的特征维度
model.fc = nn.Linear(in_fetures, 11)#把模型输出的特征通过全连接变成11类线性探测和微调的区别:线性探测是完全相信预训练模型,不计算所有参数梯度,只训练自己的分类头,微调是指将预训练模型拿过来在自己的数据集上再进行计算

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)