DeepSeek-V3震撼发布:671亿参数开源大模型,性能超越GPT-4o,引爆AI界革命!
DeepSeek-V3 是一款性能卓越的开源语言模型,具有 671 亿参数和 37 亿激活参数,采用混合专家 (MoE) 架构,训练数据量达 14.8 万亿 token。其在数学、代码生成、长文本处理等多个领域表现出色,与顶级闭源模型如 GPT-4o 相当。DeepSeek-V3 的训练成本低,仅需 558 万美元,且生成速度从 20 TPS 提升至 60 TPS。
DeepSeekV3测评
DeepSeek-V3对于复杂的逻辑问题已经形成自己思维链,对需要技巧性和灵活性的问题还缺乏思考能力。已经可以媲美GPT-4o闭源模型, 之所以能成为国际领先的语言模型,主要有以下几个原因:
一. 巨大的模型规模和训练数据量
DeepSeek-V3的总参数达到671B,激活参数37B,训练数据高达14.8T token,模型规模和数据量都处于行业领先水平,为其强大能力提供了基础。
二. 创新的模型架构设计
DeepSeek-V3在延续MLA和DeepSeek MoE架构优势的基础上,提出了无辅助损失负载均衡策略和多token预测(MTP)训练目标,有效提升了训练效率和模型性能。
2.1、MoE多专家模型架构
这个架构并不是幻方量化首创的,业界早就有这个框架模型,核心思想就是把任务分配给多个专家模型
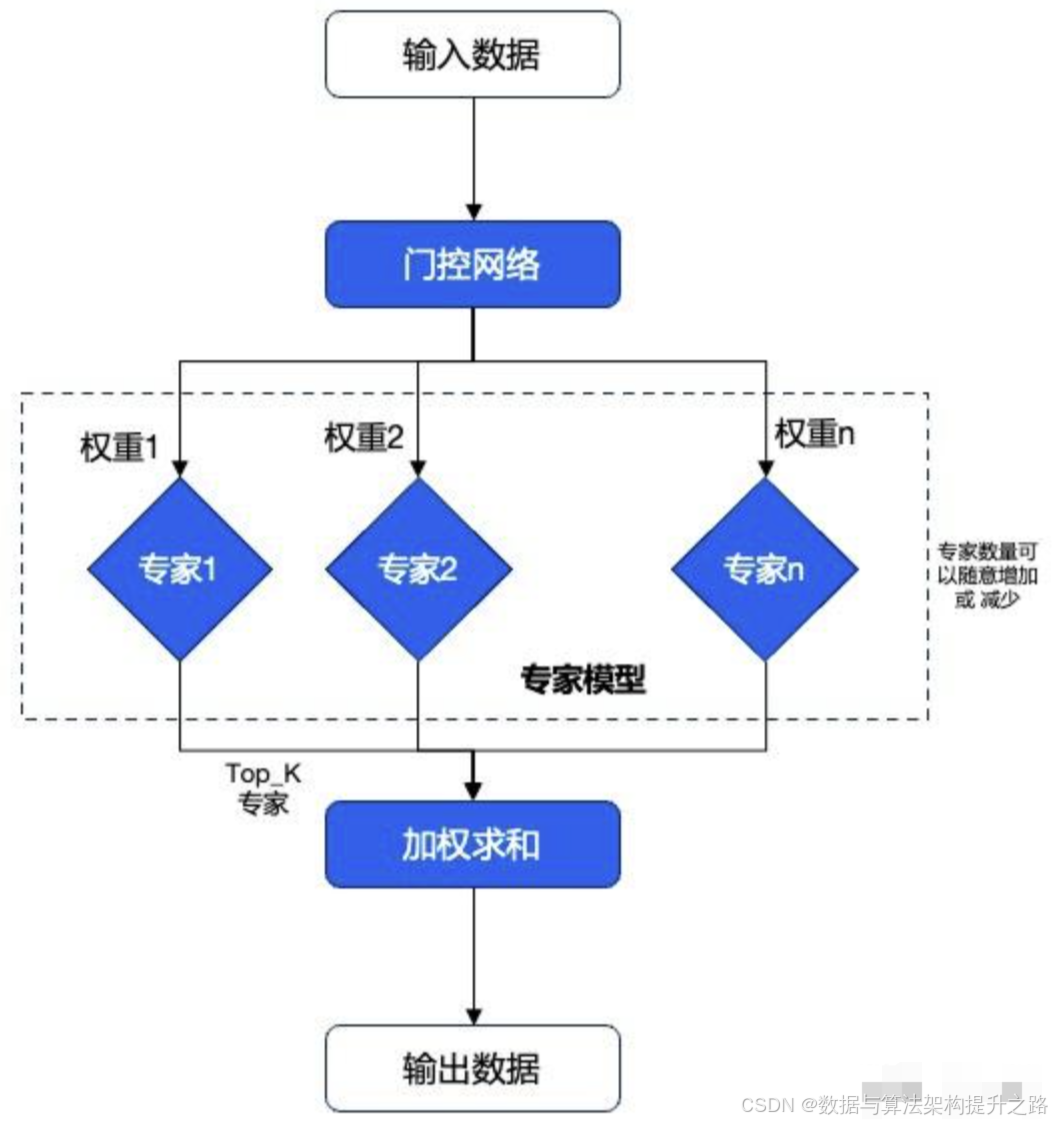
2.2、无辅助损失的负载均衡策略
在MoE结构中,不同专家的负载不均衡会导致计算效率低下,传统方法通过引入辅助损失来缓解。但辅助损失又可能损害模型性能。DeepSeek-V3提出无辅助损失负载均衡:
- 为每个专家引入一个偏置项b_i,将其加到专家与token的亲和度分数a_i上,用于Top-K路由的选择。
- 训练时实时监控每个专家的负载,对负载过高的专家,减少其偏置项;对负载不足的,增加偏置项。偏置更新速度由超参数v控制。
- 通过动态调整偏置项,在训练时实现专家间的负载均衡,且不损害模型性能。实验表明其性能优于纯辅助损失方法。
- 同时,为防止个别序列内出现极端不平衡,引入了很小的序列级辅助损失作为补充。
该策略在批次级实现专家间的负载均衡,允许不同专家适应不同领域数据的特点,提高了专家的专业化程度。消融实验证实,无辅助损失策略带来了显著的性能提升。
2.3、Token预测(MTP)机制
- 增强学习信号: 通过预测多个未来的token,而不仅仅是下一个token,MTP增加了每个位置的训练信号密度。这使得模型能够从相同数量的训练数据中学习到更多信息。
- 长期依赖建模: 通过预测更远未来的token,MTP鼓励模型建立更长期的依赖关系,有助于捕捉更广泛的上下文信息。
- 提前规划能力: 预测多个未来token迫使模型"思考"更长的序列,从而培养其提前规划表征的能力。这有助于生成更连贯、更有逻辑的长文本。
- 保持因果性: 尽管预测多个token,MTP仍然保持了完整的因果依赖链,确保模型不会"看到"未来信息,从而保持了语言模型的基本特性。
- 计算效率: 通过共享参数和仅在训练时使用,MTP避免了显著增加模型的参数量和推理时的计算负担。
- 灵活性: MTP可以在推理时选择性地使用,既可以保持原有的生成方式,也可以用于加速推理过程。
- 补充学习目标: MTP损失作为额外的优化目标,补充了传统的下一个token预测目标,丰富了模型的学习内容。
消融实验表明,MTP机制能在多个评估任务上带来1-2%的性能提升,证实了该策略的有效性。
这两项创新有效地提升了MoE结构的训练效率和整体模型性能,为进一步扩大模型规模奠定了基础。同时,它们所体现的负载均衡和预测目标优化思路,对未来的大模型架构设计具有重要的启发意义。
2.4、多头线性注意力机制(MLA)
MLA指的是DeepSeek-V3中使用的多头线性注意力(Multi-head Linear Attention)机制。它是对传统Transformer中多头注意力(Multi-head Attention, MHA)的改进,主要目的是降低注意力计算的时间和空间复杂度,提高推理效率。
MLA通过降低注意力计算的复杂度来提高推理速度,但这种近似计算方法确实可能会对模型的逻辑能力产生一定影响。不过DeepSeek-V3的实验结果表明,这种影响是相当有限的。
在多个基准测试中,DeepSeek-V3与使用标准注意力机制的模型性能相当,在某些任务上甚至有所超越。这说明MLA在提高效率的同时,很大程度上保留了原有的建模能力。
这可能有以下几方面原因:
- MLA的低秩分解虽然是一种近似,但它能够很好地保留原始注意力矩阵的主要特征。大多数任务并不需要完全精确的注意力计算。
- MLA引入的其他改进如RoPE位置编码和RMSNorm等,也有助于提升模型的表达能力,在一定程度上弥补了近似计算的损失。
- 现代的大规模语言模型本身就有很强的泛化和容错能力。少量的近似误差并不会显著影响其在下游任务上的表现。
- DeepSeek-V3的整体架构和训练方法都经过了精心设计和优化,MLA只是其中的一个环节。模型的整体能力是各个部件协同作用的结果。
三. 先进的低精度训练技术
通过采用FP8混合精度训练框架,DeepSeek-V3在保证性能的同时大幅降低了训练成本,实现了极高的训练效率。完整训练过程仅需2.788M GPU小时。
FP8 训练框架的落地除了需要在应用层选择合适的框架和适配模型外,还可能涉及到较多的技术细节和工程开发。一些通用性的功能(如FP8算子、量化感知训练)未来可能会逐步进入主流框架,而一些创新性的策略则需要团队投入专项研发。
总的来说,FP8 训练框架的落地需要模型、框架、硬件等多个层面的联合。
四. 知识蒸馏和强化学习的有效运用
通过将DeepSeek-R1系列模型的推理能力迁移,并采用强化学习持续优化,DeepSeek-V3的性能得到显著提升。
- DeepSeek-R1是一个思维链(CoT)模型,擅长通过逐步推理得出答案。但其推理过程冗长,输出格式不规范。
- 研究在数学、代码、推理等领域,用R1模型生成高质量的训练数据。对每个样本,生成两种数据:一是问题-R1原始答案,二是加入引导R1输出进行自我验证的系统提示。
- 在保留R1高准确率的同时,引导模型学习简洁的输出格式。通过蒸馏R1的推理能力,V3在数学、编程等任务上取得了显著提升。
- 消融实验表明,在LiveCodeBench和MATH基准测试中,蒸馏数据使V3的性能平均提升5-8%,证实了R1知识的有效迁移。
五. 综合评估体系
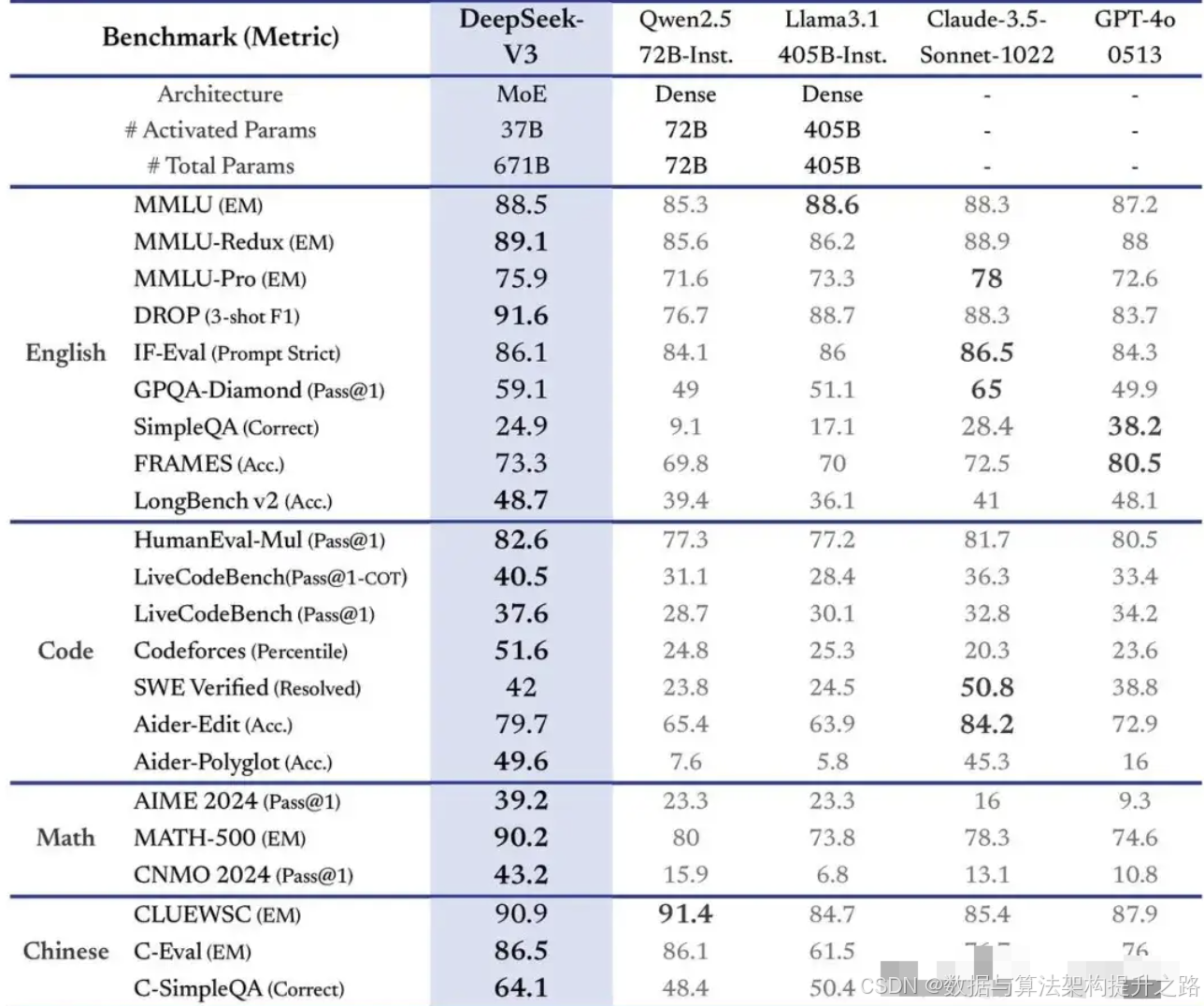
DeepSeek-V3在英语、中文、编程、数学等多个维度进行了全面评估,证明了其作为通用语言模型的能力。它不仅是性能最强的开源模型,也达到了与GPT-4、Claude等顶级闭源模型相当的水平。
六. 训练基础设施优化
6.1、DualPipe 流水线并行算法
- 在跨节点的混合专家(MoE)并行训练中,通信开销会成为显著的瓶颈,计算和通信的比例甚至接近 1:1,严重影响训练速度。
- DualPipe 的核心创新是实现了前向和反向传播中计算与通信的重叠。每个前向/反向块被拆分为注意力、全局通信、MLP、全局归约等多个功能模块。通过精心设计模块间的先后次序和资源分配,大部分通信代价都能被计算过程隐藏。
- DualPipe 采用双向流水线设计,从流水线的两端交替输入微批次数据。优化后的调度策略使绝大部分通信都能与计算重叠,将通信开销降至接近于零,显著提升了训练速度。

假设我们有一条生产线,需要生产一款玩具。这个玩具的生产需要经过以下步骤:
- 注塑:将塑料原料注入模具,形成玩具的各个零件。
- 零件分发:将注塑成型的零件分发到组装区的不同工位。
- 组装:在不同工位上将零件组装成完整的玩具。
- 成品打包:将组装好的玩具打包,准备出货。
如果我们按照传统的流水线方式组织生产,每个步骤都需要等待上一步完成才能开始。零件分发需要等所有零件注塑完毕,组装要等零件送达,打包又需要等玩具组装完成。这就导致了很多等待和空闲,生产效率不高。DualPipe算法的思路是,将每个工序再细分,实现生产过程的交叉进行:
- 将注塑过程细分为不同零件的生产,比如身体部件、轮子、装饰件等。
- 零件分发不等所有零件生产完毕,而是分批进行。比如身体部件做好后就立即发往组装区。
- 组装区的不同工位并行作业,不同零件一到位就开始装配。比如装配身体部件的工位就不用等轮子。
- 成品打包穿插在组装中进行,不同工位组装完成的半成品就流转到打包区。
- 在DualPipe中,这种交叉流水线还是双向的。也就是说,从流水线的两端都在持续输入原料。从后端看,组装区的半成品也在源源不断地回流给前端的注塑工序。
- 这样一来,注塑、分发、组装、打包四个工序实现了高度重叠,几乎没有空闲和等待。生产效率比简单的串行流水线高很多。
- 这就是DualPipe算法的核心思想。将一个前向/反向计算块划分为多个小的计算和通信单元,然后交错进行,尽可能重叠计算和通信的过程。前向计算已经开始下一个批次,反向传播也已经从后面返回,整个流水线满负荷运转。这种双向交错的流水线大大提高了硬件的使用效率和整体的训练速度。
- 这个例子虽然简化了很多细节,但应该可以直观地解释DualPipe的设计思想。它的精髓在于将原本的串行计算流程打散,变成前后交错、双向流动的细粒度流水线,从而最大化硬件的利用率,提升整体训练性能。这种思路对于理解分布式训练系统中的调度优化有重要启发意义。
6.2、高效跨节点通信内核
- 为充分利用硬件带宽,DeepSeek-V3针对集群的网络拓扑特点(IB互连+NVLink),定制了高效的集合通信内核。
- 考虑到 NVLink (160GB/s) 比 IB (50GB/s) 快 3.2 倍,通信内核限制每个 token 最多只会被发送到4个节点。到达目标节点后,立即通过 NVLink 转发到对应设备,避免被后续到达的数据阻塞。
- 这种 IB+NVLink 混合通信模式能充分利用二者的带宽,在额外开销很小的情况下,使每个节点能并发处理 3-4 个专家的数据,为计算与通信的平衡创造了条件。
6.3、显存和带宽优化
- 采用重计算、CPU 异步更新权重副本等策略,节省了大量 GPU 显存。配合FP8混合精度训练,最终实现了几乎零冗余的显存利用。
- 针对激活值存储和优化器状态,采用FP8和FP16的低精度表示,在保证训练数值稳定性的同时,将带宽压力降低了近50%。
- 在自适应的分布式训练中,通过高效的tensor和optimizer状态分片,DeepSeek-V3在671B的大规模下依然实现了良好的显存扩展效率。
综上所述,DeepSeek-V3 在模型架构、训练数据、低精度训练、知识蒸馏等方面的系统性创新,支撑其在标准评估和开放式评估中取得国际领先的优异成绩,代表了当前中国开源大模型技术发展的最高水平。
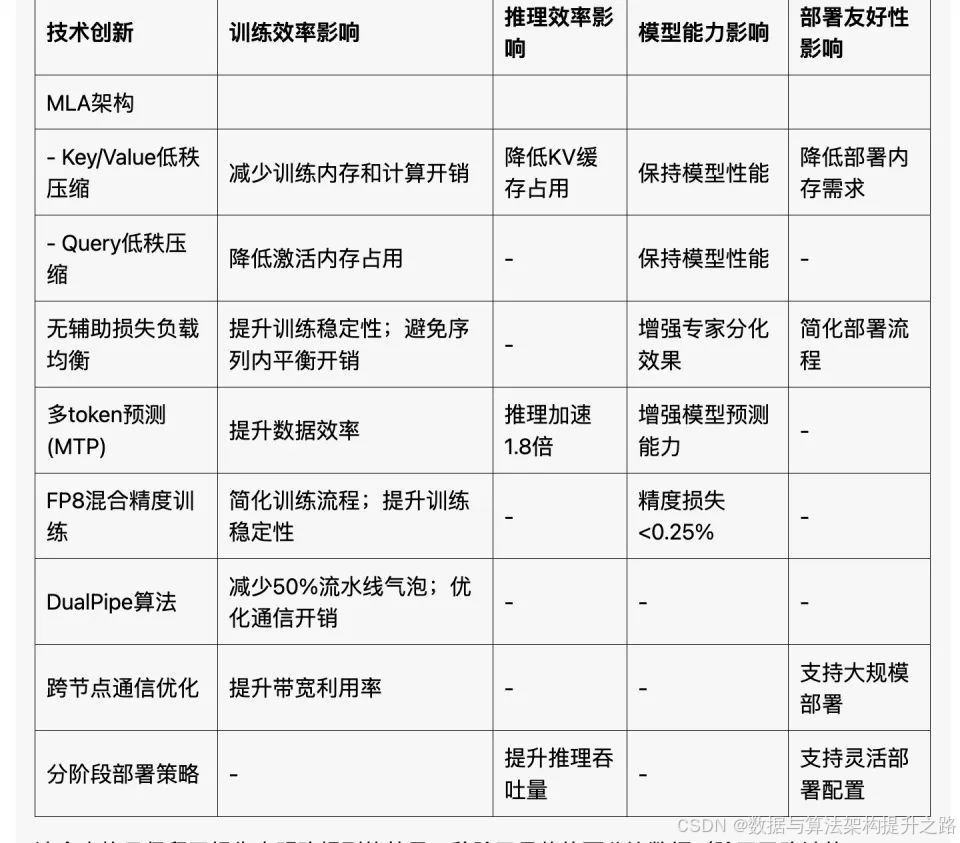
七、工程调优总结
DeepSeek-V3这回真的可以说是在训练工程上无所不用其极。总结下来,最重要的包括以下这么几个方面。
八、相关文章

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)