深度学习之激活函数篇(Sigmoid、tanh、ReLU、PReLU)
常用激活函数(激励函数)理解与总结激活函数的区别与优点梯度消失与爆炸1. 激活函数是什么?在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。2. 激活函数的用途如果不用激活函数,每一层的输入都是上一层输出的线性函数,而多层线性函数与一层线性函数的功能是等价的,网络的逼近能力就相当有限,因此引入非线性函数作为激励函数,使得深层神经...
·
写在前面:此文只记录了下本人感觉需要注意的地方,不全且不一定准确。详细内容可以参考文中帖的链接,比较好!!!
常用激活函数(激励函数)理解与总结
激活函数的区别与优点
梯度消失与爆炸
1. 激活函数是什么?
在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
2. 激活函数的用途
如果不用激活函数,每一层的输入都是上一层输出的线性函数,而多层线性函数与一层线性函数的功能是等价的,网络的逼近能力就相当有限,因此引入非线性函数作为激励函数,使得深层神经网络的可以更好的逼近任意函数。
3. 常见的激活函数:
Sigmoid 函数:
- 表达形式:
f ( z ) = 1 1 + e − z f(z) = \frac{1}{1+e^{-z}} f(z)=1+e−z1 - 函数图像:

- 导数图像:

- 优缺点:
优点
- 能够把输入的连续值压缩到【0~1】之间,可解释性强,0为不活跃,1为活跃
缺点
- 梯度反向传递时,容易导致梯度的爆炸和消失(大概率梯度消失,有时梯度爆炸)。

而由于 σ ( z ) \sigma (z) σ(z)最大值为0.25,且通常初始| w | < 1 ,则有: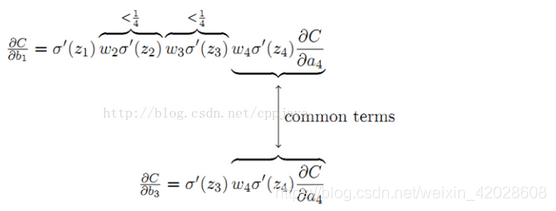
极易出现梯度消失;当初始化 |w| > 4 时,w * σ ( z ) \sigma (z) σ(z) > 1 ,才会产生梯度爆炸。 - sigmoid函数的输出不是0均值。若该层神经元得到上一层的非0输出作为输入,产生的回传梯度的符号就会相同,或者都为正或者都为负,导致捆绑效果,使结果收敛变慢(例如,当x>0时,y = wx + b,对w求导,得到的梯度全为正,但可能w1 > w1,w2 < w2*,使得w1离w1*越来越远)详解sigmoid输出非0均值对网络训练的影响
- 解析式中有幂运算,计算量相对较大
tanh 函数:
- 表达式:
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac{e^{x} - e ^ {-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x - 函数图像及导数图像:

- 特点:解决了sigmoid函数中的输出非0均值,但梯度消失或爆炸、及计算量较大的问题仍存在
Relu 函数:
- 表达式:
R e l u = m a x ( 0 , x ) Relu = max (0, x) Relu=max(0,x) - 函数图像及导数图像:

- 优缺点:
优点
- 在正区间上解决了梯度消失或爆炸问题
- 计算梯度时只需判断是否大于0,而不用幂函数,计算速度快,收敛速度快
缺点
- ReLU的输出非0均值
- 当输入激活函数的值小于0时,对应的神经元的回传梯度为0,导致相应参数永远不会被更新(非正部分不会更新参数)
Relu与Relu6 对比:
参考:Relu6 作用
- Relu6就是普通的Relu,但是限制最大输出值为6,。优点是在移动端设备float16的低精度时,也能有不错的分辨率。因为如果激活不加限制,输出范围为0到正无穷,float16的精度下无法很好的精确描述如此大的范围数,带来精度损失【精度不足,导致溢出】。
Leaky Relu 函数(PReLU):
- 表达式
f ( x ) = m a x ( α x , x ) , α = 0.01 f(x) = max(\alpha x, x), \alpha = 0.01 f(x)=max(αx,x),α=0.01 - 解决了ReLU非正梯度为0,导致有些参数永远不会被更新的问题
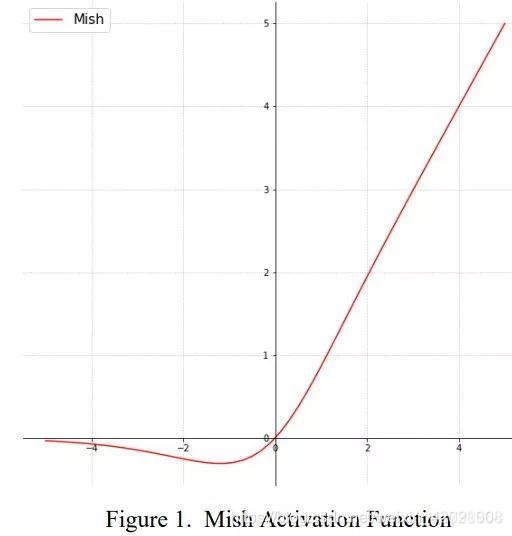
Mish 函数:
- 表达式
M i s h = x × t a n h ( l n ( 1 + e x ) ) Mish=x×tanh(ln(1+ex)) Mish=x×tanh(ln(1+ex)) - 解决了ReLU非正梯度为0,导致有些参数永远不会被更新的问题
- 函数图像:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)