Ray构建GPU隔离的机器学习平台
Ray框架介绍Ray框架介绍Ray 是一个开源分布式计算框架,在 机器学习基础设施中发挥着至关重要的作用。Ray 促进分布式机器学习训练,使机器学习从业者能够有效利用多个 GPU 的能力。Ray可以在集群上分布式地运行任务,并且可以指定任务运行时需要使用的GPU数量。
目录
Ray框架介绍
Ray 是一个开源分布式计算框架,在 机器学习基础设施中发挥着至关重要的作用。Ray 促进分布式机器学习训练,使机器学习从业者能够有效利用多个 GPU 的能力。
Ray 允许开发者编写可以在集群上运行的分布式应用程序,并且可以指定任务运行时需要使用的GPU数量,而不必处理底层通信和同步的复杂性。
Ray可与Nvidia-docker等技术相结合,以实现在使用Ray进行分布式计算时,每个任务都在自己的隔离环境中。
Ray 最显着的优势之一是它能够无缝扩展 ML 工作负载。无论您是训练具有数十亿参数的模型还是执行复杂的计算,Ray 都能提供必要的弹性。这种可扩展性确保了即使模型规模和复杂性增加,机器学习模型也能快速有效地进行训练。
Ray 的核心是一个分布式任务调度器,可以智能地将任务分配到集群中的不同节点上
机器学习平台
Ray 及其 AI 库为希望简化 ML 平台的团队提供统一的计算运行时。Ray 的库(例如 Ray Train、Ray Data 和 Ray Serve)可用于组成端到端 ML 工作流程,提供用于数据预处理(作为训练的一部分)以及从训练过渡到服务的功能和 API。

Ray Core
-
任务和演员:Ray将计算工作分为任务(无状态函数)和演员(有状态的类实例),以便进行分布式执行。
-
分布式对象存储:Ray利用内存对象存储来共享数据,支持高效的数据访问和通信。
-
灵活的调度:Ray自动管理任务和资源调度,允许无缝扩展计算工作负载。
-
容错性:Ray通过数据和任务的自动复制实现高可靠性。
示例
# Define the square task.
@ray.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]在分布式环境中执行一个简单的数值平方任务
示例2
# 定义一个叫Counter的actor类。
@ray.remote
class Counter:
def __init__(self):
self.i = 0 # 初始值设为0
def get(self):
return self.i # 返回当前值
def incr(self, value):
self.i += value # 将当前值增加指定的数值
# 创建一个Counter actor的实例。
c = Counter.remote()
# 提交调用到actor。这些调用在远程actor进程中异步执行,但按提交顺序执行。
for _ in range(10):
c.incr.remote(1) # 对i进行10次增量操作,每次增加1
# 获取最终actor状态。
print(ray.get(c.get.remote())) # -> 10 打印最终的i值
这个代码演示了如何在Ray中定义和使用actor来进行状态的存储和异步操作。它创建了一个简单的计数器actor,通过10次远程调用增加其内部计数,最后检索并打印出这个计数器的最终值。
示例3
import numpy as np
# 定义一个任务,用于计算矩阵中的值之和。
@ray.remote
def sum_matrix(matrix):
return np.sum(matrix) # 使用numpy的sum函数计算矩阵的总和
# 使用具体的参数值调用任务。
print(ray.get(sum_matrix.remote(np.ones((100, 100))))) # -> 10000.0
# 此行输出100x100的全1矩阵的元素和,即10000.0
# 将一个大数组放入对象存储中。
matrix_ref = ray.put(np.ones((1000, 1000))) # 创建1000x1000的全1矩阵并获取其引用
# 使用对象引用matrix_ref 作为参数调用任务。
print(ray.get(sum_matrix.remote(matrix_ref))) # -> 1000000.0
# 此行输出1000x1000的全1矩阵的元素和,即1000000.0
Ray Data组件
Ray Data 是一个适用于 ML 工作负载的可扩展数据处理库。
Ray Data 和 Apache Spark的离线计算有一些相似之处,但也有重要的区别。Ray Data的设计更加灵活,能够更好地与机器学习和AI工作流程集成。此外,Ray Data支持的动态任务调度和弹性扩展能力在某些方面超越了Spark。总体而言,尽管二者在处理大规模数据方面有共通之处,但它们的设计理念、优化点和适用场景存在差异。
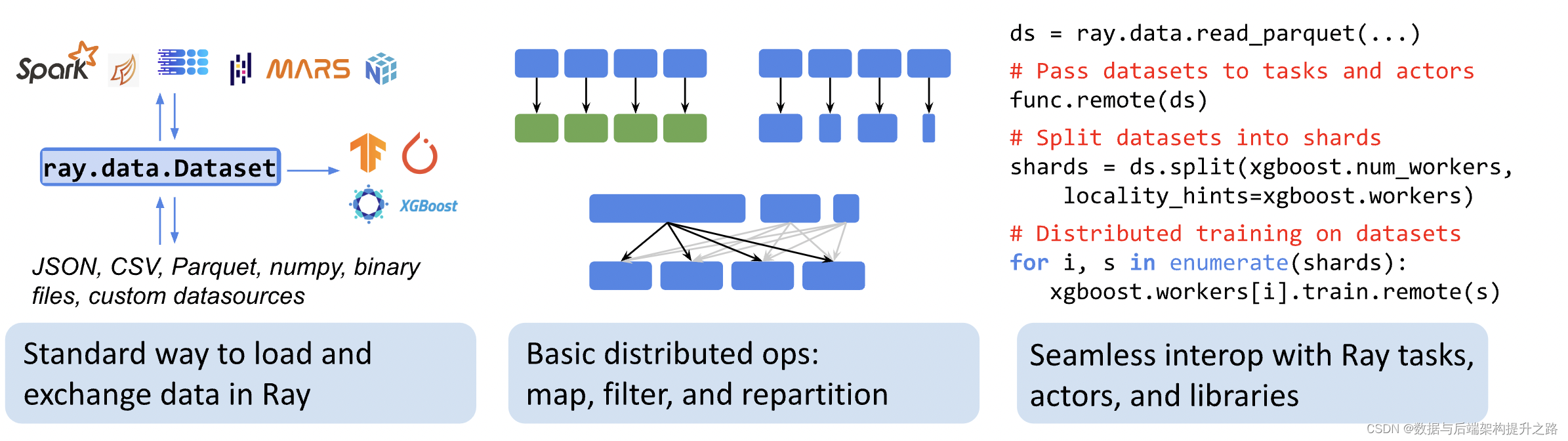
Ray Data 是一个适用于 ML 工作负载的可扩展数据处理库,特别适合以下工作负载:
它为分布式数据处理提供灵活且高性能的API:
-
简单的变换,例如映射 ( map_batches())
-
全局聚合和分组聚合 ( groupby())
-
洗牌操作 ( random_shuffle(), sort(), repartition())。
Ray Data 构建在 Ray 之上,因此它可以有效地扩展到大型集群,并为 CPU 和 GPU 资源提供调度支持。Ray Data 使用流式执行来高效处理大型数据集。
Ray Train组件
Ray Train组件为TensorFlow、PyTorch和Keras提供了分布式训练的封装。它使得在多GPU或多节点环境中进行模型训练变得简单,无需深入了解底层的分布式计算细节。Ray Train自动管理数据的分布和同步,优化资源分配,并提供了一套简洁的API来透明地实现数据并行和模型并行。这允许开发者专注于模型的设计和训练,而不是分布式系统的复杂性。
具体应用
相关资料

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 21
21 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)