在 PyTorch 中构建卷积神经网络
这篇文章分为四个部分;他们是卷积神经网络的案例卷积神经网络的构建模块卷积神经网络的一个例子特征图中有什么?
✍面向读者:软件工程师、架构师、IT人士、设计人员等
✍所属专栏:人工智能工具实践
目录
神经网络是由相互连接的层构建的。有许多不同类型的层。对于图像相关的应用程序,您总是可以找到卷积层。它是一个参数很少的层,但应用于大尺寸的输入。它很强大,因为它可以保留图像的空间结构。因此,它被用来在计算机视觉神经网络上产生最先进的结果。在这篇文章中,您将了解卷积层及其构建的网络。完成这篇文章后,您将了解:
- 什么是卷积层和池化层
- 它们如何在神经网络中组合在一起
- 如何设计使用卷积层的神经网络

概述
这篇文章分为四个部分;他们是
- 卷积神经网络的案例
- 卷积神经网络的构建模块
- 卷积神经网络的一个例子
- 特征图中有什么?
卷积神经网络的案例
让我们考虑创建一个神经网络来处理灰度图像作为输入,这是计算机视觉深度学习中最简单的用例。
灰度图像是像素阵列。每个像素通常是 0 到 255 范围内的值。尺寸为 32×32 的图像将有 1024 个像素。将其作为神经网络的输入意味着第一层至少有 1024 个输入权重。
查看像素值对于理解图片没有多大用处,因为数据隐藏在空间结构中(例如,图片上是否有水平线或垂直线)。因此传统的神经网络很难从图像输入中找出信息。
卷积神经网络是利用卷积层来保存像素的空间信息。它了解相邻像素的相似程度并生成特征表示。卷积层从图片中看到的内容在某种程度上不受失真的影响。例如,即使输入图像发生颜色变化、旋转或重新缩放,卷积神经网络也可以预测相同的结果。此外,卷积层的权重较少,因此更容易训练。
卷积神经网络的构建模块
卷积神经网络最简单的用例是分类。您会发现它包含三种类型的图层:
- 卷积层
- 池化层
- 全连接层
卷积层上的神经元称为滤波器。在图像应用中通常是2D卷积层。滤波器是应用于输入图像像素的2D补丁(例如,3×3像素)。这个 2D 块的大小也称为感受野,意味着它一次可以看到图像的多大部分。
卷积层的滤波器就是与输入像素相乘,然后将结果相加。该结果是输出处的一个像素值。过滤器将在输入图像周围移动以填充输出处的所有像素值。通常多个滤波器应用于同一输入,产生多个输出张量。这些输出张量称为 该层生成的特征图。它们作为一个张量堆叠在一起并作为输入传递到下一层。
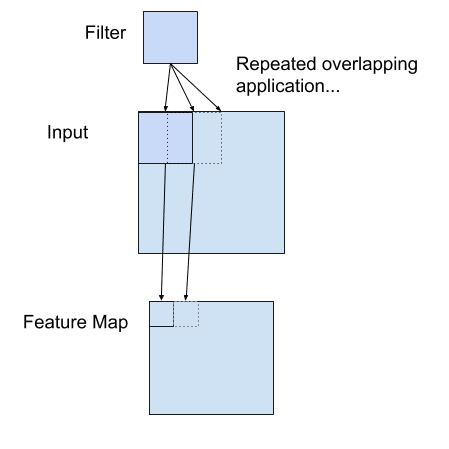
应用于二维输入以创建特征映射的过滤器示例
卷积层的输出称为特征图,因为它通常了解输入图像的特征。例如该位置是否有竖线。从像素中学习特征有助于在更高层次上理解图像。多个卷积层堆叠在一起,以便从较低级别的细节推断较高级别的特征。
池化层是对前一层的特征图进行下采样。它通常在卷积层之后使用,以巩固学习到的特征。它可以压缩和概括特征表示。池化层也有一个感受野,通常是对感受野上的所有值取平均值(平均池化)或最大值(最大池化)。
全连接层通常是网络中的最后一层。就是将之前的卷积层和池化层合并的特征作为输入来产生预测。可能有多个完全连接的层堆叠在一起。在分类的情况下,您通常会看到最终全连接层的输出应用了 softmax 函数来生成类似概率的分类。
卷积神经网络的一个例子
以下是在 CIFAR-10 数据集上进行图像分类的程序。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
batch_size = 32
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1)
self.act1 = nn.ReLU()
self.drop1 = nn.Dropout(0.3)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1)
self.act2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.flat = nn.Flatten()
self.fc3 = nn.Linear(8192, 512)
self.act3 = nn.ReLU()
self.drop3 = nn.Dropout(0.5)
self.fc4 = nn.Linear(512, 10)
def forward(self, x):
# input 3x32x32, output 32x32x32
x = self.act1(self.conv1(x))
x = self.drop1(x)
# input 32x32x32, output 32x32x32
x = self.act2(self.conv2(x))
# input 32x32x32, output 32x16x16
x = self.pool2(x)
# input 32x16x16, output 8192
x = self.flat(x)
# input 8192, output 512
x = self.act3(self.fc3(x))
x = self.drop3(x)
# input 512, output 10
x = self.fc4(x)
return x
model = CIFAR10Model()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
n_epochs = 20
for epoch in range(n_epochs):
for inputs, labels in trainloader:
# forward, backward, and then weight update
y_pred = model(inputs)
loss = loss_fn(y_pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = 0
count = 0
for inputs, labels in testloader:
y_pred = model(inputs)
acc += (torch.argmax(y_pred, 1) == labels).float().sum()
count += len(labels)
acc /= count
print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100))
torch.save(model.state_dict(), "cifar10model.pth")torchvision很有用。在上面,您使用它从互联网下载 CIFAR-10 数据集并将其转换为 PyTorch 张量:
...
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)DataLoaderPyTorch 中的 a 来帮助创建训练批次。训练是为了优化模型的交叉熵损失,使用随机梯度下降。它是一个分类模型,因此分类的准确性比交叉熵更直观,交叉熵是在每个时期结束时通过将输出 logit 中的最大值与数据集的标签进行比较来计算的:
...
acc += (torch.argmax(y_pred, 1) == labels).float().sum()运行上面的程序来训练网络需要时间。该网络应该能够实现 70% 以上的分类准确率。
在图像分类网络中,早期阶段通常由卷积层组成,其中 dropout 层和池化层交错。然后,在稍后阶段,卷积层的输出被一些全连接层展平并处理。
特征图中有什么?
上面定义的网络中有两个卷积层。它们都是用 3×3 的内核大小定义的,因此它一次查看 9 个像素以产生一个输出像素。请注意,第一个卷积层将 RGB 图像作为输入。因此每个像素具有三个通道。第二个卷积层采用 32 个通道的特征图作为输入。它看到的每个“像素”都有 32 个值。因此,第二个卷积层具有更多的参数,即使它们具有相同的感受野。
让我们看看特征图中有什么。假设我们从训练集中选择一个输入样本:
import matplotlib.pyplot as plt
plt.imshow(trainset.data[7])
plt.show()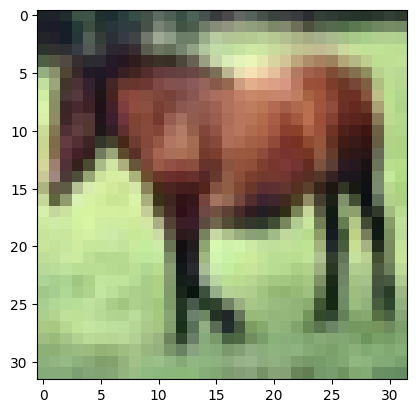
首先,您需要将其转换为 PyTorch 张量,并使其成为一批图像。PyTorch 模型期望每个图像作为(通道,高度,宽度)格式的张量,但您读取的数据采用(高度,宽度,通道)格式。如果您用于torchvision将图像转换为 PyTorch 张量,则此格式转换会自动完成。否则,您需要在使用前对尺寸进行排列。
然后,将其传递到模型的第一个卷积层并捕获输出。您需要告诉 PyTorch 此计算不需要梯度,因为您不打算优化模型权重:
X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2)
model.eval()
with torch.no_grad():
feature_maps = model.conv1(X)fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(feature_maps[0][i])
plt.show()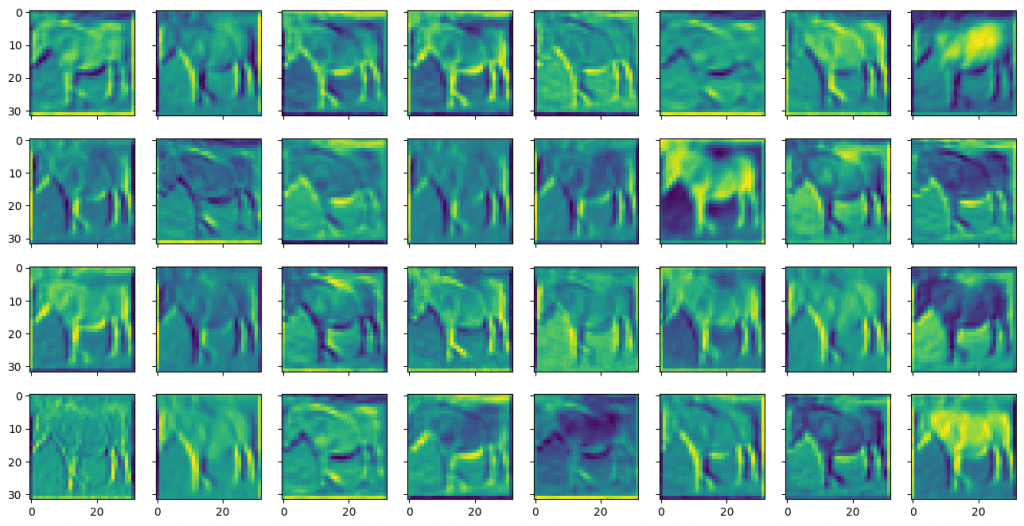
您可以看到它们被称为特征图,因为它们突出显示输入图像中的某些特征。使用小窗口(在本例中为 3×3 像素过滤器)来识别特征。输入图像具有三个颜色通道。每个通道都应用了不同的滤波器,并将它们的结果组合起来形成输出特征。
您可以类似地显示第二个卷积层输出的特征图,如下所示:
X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2)
model.eval()
with torch.no_grad():
feature_maps = model.act1(model.conv1(X))
feature_maps = model.drop1(feature_maps)
feature_maps = model.conv2(feature_maps)
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(feature_maps[0][i])
plt.show()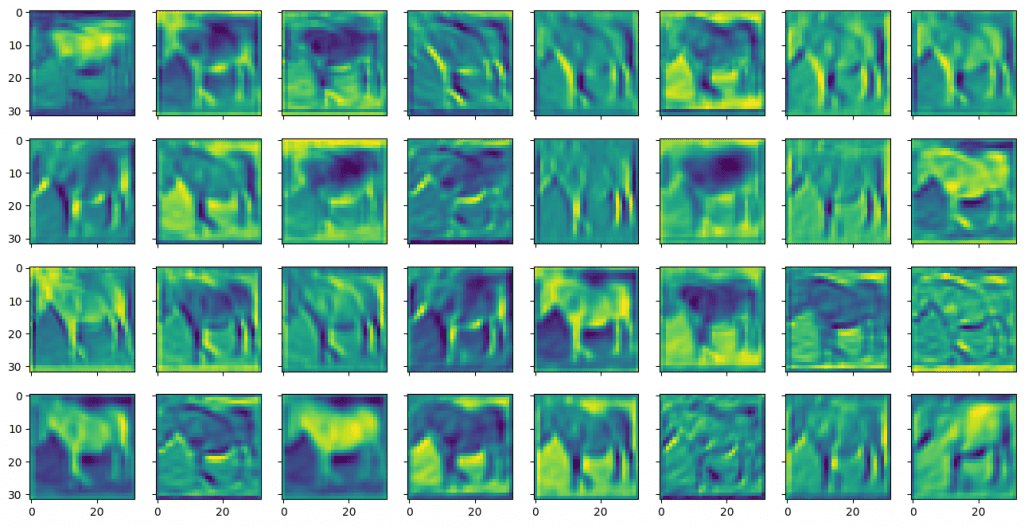
与第一个卷积层的输出相比,第二个卷积层的特征图看起来模糊且更抽象。但这些对于模型识别对象更有用。
将所有内容放在一起,下面的代码加载上一节中保存的模型并生成特征图:
import torch
import torch.nn as nn
import torchvision
import matplotlib.pyplot as plt
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1)
self.act1 = nn.ReLU()
self.drop1 = nn.Dropout(0.3)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1)
self.act2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.flat = nn.Flatten()
self.fc3 = nn.Linear(8192, 512)
self.act3 = nn.ReLU()
self.drop3 = nn.Dropout(0.5)
self.fc4 = nn.Linear(512, 10)
def forward(self, x):
# input 3x32x32, output 32x32x32
x = self.act1(self.conv1(x))
x = self.drop1(x)
# input 32x32x32, output 32x32x32
x = self.act2(self.conv2(x))
# input 32x32x32, output 32x16x16
x = self.pool2(x)
# input 32x16x16, output 8192
x = self.flat(x)
# input 8192, output 512
x = self.act3(self.fc3(x))
x = self.drop3(x)
# input 512, output 10
x = self.fc4(x)
return x
model = CIFAR10Model()
model.load_state_dict(torch.load("cifar10model.pth"))
plt.imshow(trainset.data[7])
plt.show()
X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2)
model.eval()
with torch.no_grad():
feature_maps = model.conv1(X)
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(feature_maps[0][i])
plt.show()
with torch.no_grad():
feature_maps = model.act1(model.conv1(X))
feature_maps = model.drop1(feature_maps)
feature_maps = model.conv2(feature_maps)
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(feature_maps[0][i])
plt.show()概括
在这篇文章中,您学习了如何使用卷积神经网络来处理图像输入以及如何可视化特征图。
具体来说,您了解到:
- 典型的卷积神经网络的结构
- 滤波器大小对卷积层有什么影响
- 在网络中堆叠卷积层有什么效果
- 如何从卷积神经网络中提取和可视化特征图

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)