论文导读 | 异构图神经网络
近年来,图神经网络(Graph Neural Networks, GNNs)已成为图挖掘研究的核心,研究人员开始关注其在异构图方面的潜力。异构图由多种类型的节点和边构成,且带有不同的辅助信息,这将新颖有效的图学习算法与嘈杂复杂的工业场景(如推荐系统)联系起来。在异构信息网络中,各类节点的嵌入空间通常不同。不同节点对之间以及相同节点对之间,都存在着各种各样的关系。
近年来,图神经网络(Graph Neural Networks, GNNs)已成为图挖掘研究的核心,研究人员开始关注其在异构图方面的潜力。异构图由多种类型的节点和边构成,且带有不同的辅助信息,这将新颖有效的图学习算法与嘈杂复杂的工业场景(如推荐系统)联系起来。
在异构信息网络中,各类节点的嵌入空间通常不同。不同节点对之间以及相同节点对之间,都存在着各种各样的关系。为应对异质性挑战,人们提出了各种异构图神经网络(Heterogeneous Graph Neural Networks, HGNNs)来处理相关任务,包括节点分类、链接预测和知识感知推荐。在过去两年中开发了众多异构图神经网络。HGNNs可以大致分为两类,基于元路径的方法和无元路径的方法。本文将简单介绍具有代表性的模型和其背后思想。
Metapath-based methods
基于元路径的方法首先捕捉相同语义的结构信息,然后融合不同的语义信息。这些模型首先在每个元路径的范围内聚合邻居特征以生成语义向量,然后融合这些语义向量以生成最终的嵌入向量。
元路径是由节点类型和边类型交替组成的序列,它规定了在图中从一种类型的节点到另一种类型的节点所遵循的特定路径模式。例如,在一个包含 Author、Paper、Conference等多种类型节点和边的学术图中,一条元路径可以是 “Author-Paper-Conference-Paper-Author”,它表示了作者通过论文与会议建立联系,并进一步通过其他论文与其他作者相连的一种特定关系模式。
给定异构图中的一个节点iii和一条元路径ϕ\phiϕ,节点𝑖的基于元路径的邻居NiϕN_i^\phiNiϕ被定义为通过元路径ϕ\phiϕ与节点iii相连的节点集合。
Heterogeneous Graph Attention Network (HAN)
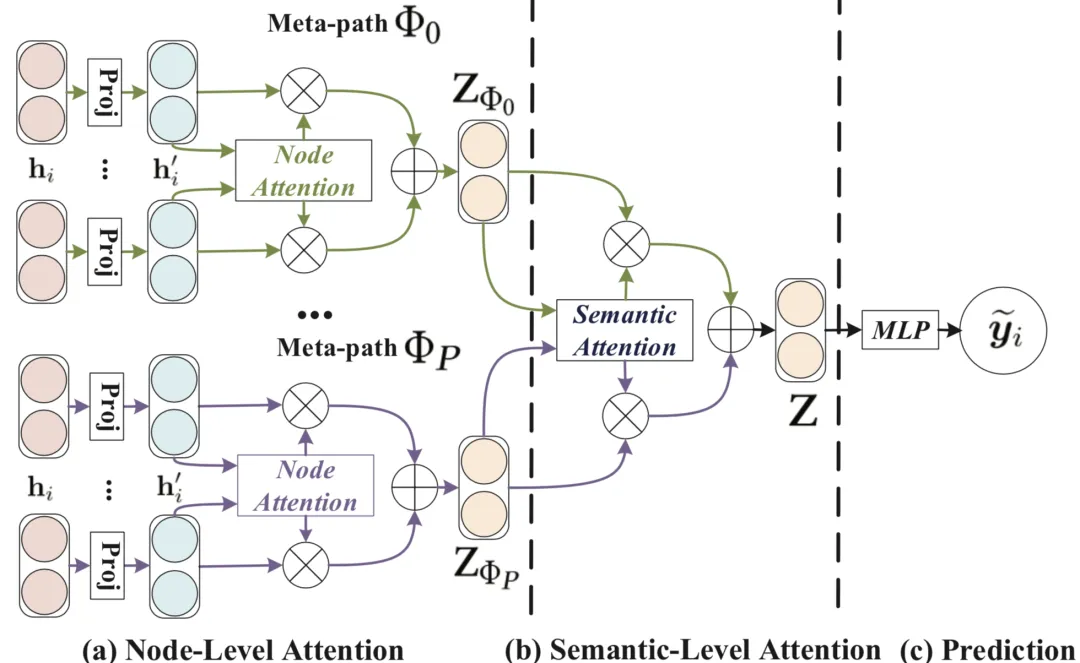
HAN提出了一种完全基于注意力机制的半监督异构图神经网络,能够捕捉异构图背后的复杂结构和丰富语义。该模型先后借助节点级注意力和语义级注意力,来学习节点和元路径的重要性。
Metapath Aggregated Graph Neural Network (MAGNN)
MAGNN在HAN的基础上对模型进行改进。HAN在聚合邻居信息的时候,只考虑元路径的起始节点和末尾节点,造成信息损失。
计算attention score的公式为
αijΦ=softmaxj(eijΦ)=exp(σ(aΦT⋅[hi′∥hP(i,j)]))∑k∈NiΦexp(σ(aΦT⋅[hi′∥hP(i,k)])) \alpha_{ij}^{\Phi}=\text{softmax}_j(e_{ij}^{\Phi})=\frac{\exp\left(\sigma\left(\mathbf{a}_{\Phi}^{\mathrm{T}}\cdot\left[\mathbf{h}_{i}^{\prime}\|\mathbf{h}_{P(i,j)}\right]\right)\right)}{\sum_{k\in\mathcal{N}_{i}^{\Phi}}\exp\left(\sigma\left(\mathbf{a}_{\Phi}^{\mathrm{T}}\cdot\left[\mathbf{h}_{i}^{\prime}\|\mathbf{h}_{P(i,k)}\right]\right)\right)} αijΦ=softmaxj(eijΦ)=∑k∈NiΦexp(σ(aΦT⋅[hi′∥hP(i,k)]))exp(σ(aΦT⋅[hi′∥hP(i,j)]))
其中hP(i,j)\mathbf{h}_{P(i,j)}hP(i,j)表示元路径的信息。MAGNN设计了三个候选编码
(1) Mean encoder: hP(v,u)=MEAN(ht′,∀t∈P(v,u))h_{P(v,u)}=MEAN({h_t^′,∀t∈P(v,u)})hP(v,u)=MEAN(ht′,∀t∈P(v,u))
(2) Linear encoder: hP(v,u)=WP⋅MEAN(ht′,∀t∈P(v,u))h_{P(v,u)}=W_P \cdot MEAN({h_t^′,∀t∈P(v,u)})hP(v,u)=WP⋅MEAN(ht′,∀t∈P(v,u))
(3) Relational rotation encoder: 上面两种编码方式忽略了元路径的序列信息,故提出第三种编码方式
o0=ht0′=hu′oi=hti′+oi−1⊙rihP(v,u)=onn+1 \begin{align*} \mathbf{o}_0 &= \mathbf{h}_{t_0}^{\prime} = \mathbf{h}_{u}^{\prime}\\ \mathbf{o}_i &= \mathbf{h}_{t_i}^{\prime} + \mathbf{o}_{i - 1} \odot \mathbf{r}_i\\ \mathbf{h}_{P(v,u)} &= \frac{\mathbf{o}_n}{n + 1} \end{align*} o0oihP(v,u)=ht0′=hu′=hti′+oi−1⊙ri=n+1on
其中第三种编码方式的效果最好
Heterogeneous Graph Neural Network (HetGNN)
HetGNN设计了一个带重启的随机游走策略,为异构图中的每个节点采样固定数量的异质邻居,并基于节点类型对它们分类。在邻居聚合阶段,HetGNN采用Bi-LSTM捕获邻居节点的深度特征信息。在语义聚合阶段,HetGNN运用注意力机制,为不同语义的邻居信息分配不同的权重。
Simple and Efficient Heterogeneous Graph Neural Network (SeHGNN)
文章做了预实验并得出了两个结论:(1)语义注意力是必不可少的,而邻居注意力则并非必要;(2)具有单层结构和长元路径的模型优于具有多层结构和短元路径的模型。
SeHGNN采用均值聚合器来简化邻居聚合,采用具有长元路径的单层结构来聚合邻居信息,并利用基于 Transformer 的模块来学习不同语义信息之间的注意力分数。此外,由于 SeHGNN 中邻居聚合函数是无参数的,且仅涉及线性运算,因此只要在预处理步骤中执行一次邻居聚合。SeHGNN 不仅预测准确度高,还避免了在每个训练轮次中重复进行邻居聚合,显著提高了训练速度。
Step1. 邻居聚合
mi={ziP=1∥SP∥∑p(i,j)∈SPxj:P∈ΦX} m_i=\left\{\mathbf{z}_i^{\mathcal{P}}=\frac{1}{\|S^{\mathcal{P}}\|}\sum_{p(i,j)\in S_{\mathcal{P}}}\mathbf{x}_j:\mathcal{P}\in\Phi_X\right\} mi=⎩
⎨
⎧ziP=∥SP∥1p(i,j)∈SP∑xj:P∈ΦX⎭
⎬
⎫
Step2. 语义聚合
qPi=WQh′Pi,kPi=WKh′Pi,vPi=WVh′Pi,Pi∈Φα(Pi,Pj)=exp(qPi⋅kPjT)∑Pt∈Φexp(qPi⋅kPtT),hPi=β∑Pj∈Φα(Pi,Pj)vPj+h′Pi, \begin{align*} q^{\mathcal{P}_i}&=W_Qh^{\prime\mathcal{P}_i},k^{\mathcal{P}_i}=W_Kh^{\prime\mathcal{P}_i},v^{\mathcal{P}_i}=W_Vh^{\prime\mathcal{P}_i},\mathcal{P}_i\in\Phi\\ \alpha(\mathcal{P}_i,\mathcal{P}_j)&=\frac{\exp(q^{\mathcal{P}_i}\cdot k^{\mathcal{P}_jT})}{\sum_{\mathcal{P}_t\in\Phi}\exp(q^{\mathcal{P}_i}\cdot k^{\mathcal{P}_tT})},\\ h^{\mathcal{P}_i}&=\beta\sum_{\mathcal{P}_j\in\Phi}\alpha(\mathcal{P}_i,\mathcal{P}_j)v^{\mathcal{P}_j}+h^{\prime\mathcal{P}_i}, \end{align*} qPiα(Pi,Pj)hPi=WQh′Pi,kPi=WKh′Pi,vPi=WVh′Pi,Pi∈Φ=∑Pt∈Φexp(qPi⋅kPtT)exp(qPi⋅kPjT),=βPj∈Φ∑α(Pi,Pj)vPj+h′Pi,
Metapath-free methods
无元路径方法在聚合邻居的时候同时捕捉结构信息和语义信息。这些模型如同传统的图神经网络一样,从节点的局部邻域聚合信息。但与传统方法不同的是,它们采用了额外的模块(例如注意力机制),将诸如节点类型和边类型等语义信息嵌入到传播的消息中。这种方式避免了传统元路径方法中对预先定义元路径的依赖,能够更加灵活地挖掘异构图中潜在的结构和语义信息。
Heterogeneous Graph Structural Attention Neural Network (HetSANN)
HetSANN和图注意力网络(Graph Attention Networks, GAT)的模型结构大致一样。为了解决异质节点嵌入空间不一样的问题,HetSANN在计算attention score的时候会先将不同类型的邻居嵌入映射到当前节点类型的低维嵌入空间。
Step1. 计算注意力分数
Font metrics not found for font: .
Step2. 消息传递
Font metrics not found for font: .
除此之外,在捕获异质实体空间转换关系时,额外引入循环一致性损失。即如图所示,一个节点经过一个循环的转换过程后,应该能回到初始状态。
Wpj,pi(l+1,m)(Wpi,pi(l+1,m))−1Wpi,pj(l+1,m)hj(l)≈Wpj,pj(l+1,m)hj(l) W_{p_j,p_i}^{(l + 1,m)}\left(W_{p_i,p_i}^{(l + 1,m)}\right)^{-1}W_{p_i,p_j}^{(l + 1,m)}h_j^{(l)}\approx W_{p_j,p_j}^{(l + 1,m)}h_j^{(l)} Wpj,pi(l+1,m)(Wpi,pi(l+1,m))−1Wpi,pj(l+1,m)hj(l)≈Wpj,pj(l+1,m)hj(l)
由于求逆矩阵时间开销较大,故采用可训练的矩阵替换上式逆矩阵。循环一致性损失如下
Jcycle=β1Epi,pj∈A[(Wpj,pi(l,m)W~pi,pi(l,m)Wpi,pj(l,m)hj(l−1)−Wpj,pj(l,m)hj(l−1))2]+β2Ep∈A[(W~p,p(l,m)Wp,p(l,m)−I)2+(Wp,p(l,m)W~p,p(l,m)−I)2] \begin{align*} &\mathcal{J}_{\text{cycle}} = \\ &\beta_1\underset{p_i,p_j\in\mathcal{A}}{\mathbb{E}}\left[\left(W_{p_j,p_i}^{(l,m)}\widetilde{W}_{p_i,p_i}^{(l,m)}W_{p_i,p_j}^{(l,m)}h_j^{(l-1)}-W_{p_j,p_j}^{(l,m)}h_j^{(l-1)}\right)^2\right]\\ &+\beta_2\underset{p\in\mathcal{A}}{\mathbb{E}}\left[\left(\widetilde{W}_{p,p}^{(l,m)}W_{p,p}^{(l,m)}-I\right)^2+\left(W_{p,p}^{(l,m)}\widetilde{W}_{p,p}^{(l,m)}-I\right)^2\right] \end{align*} Jcycle=β1pi,pj∈AE[(Wpj,pi(l,m)W
pi,pi(l,m)Wpi,pj(l,m)hj(l−1)−Wpj,pj(l,m)hj(l−1))2]+β2p∈AE[(W
p,p(l,m)Wp,p(l,m)−I)2+(Wp,p(l,m)W
p,p(l,m)−I)2]
Heterogeneous Graph Transformer (HGT)
HGT参考了Transformer的注意力框架,把参数和元关系<τ(s),ϕ(e),τ(t)>关联。
Step1. 计算注意力分数
AttentionHGT(s,e,t)=Softmax∀s∈N(t)(∥i∈[1,h]ATT−headi(s,e,t))AATT−headi(s,e,t)=(Ki(s)Wϕ(e)ATTQi(t)T)⋅μ⟨τ(s),ϕ(e),τ(t)⟩dKi(s)=K-Linearτ(s)i(H(l−1)[s])Qi(t)=Q-Linearτ(t)i(H(l−1)[t]) \begin{align*} \text{Attention}_{HGT}(s,e,t)&=\underset{\forall s\in N(t)}{\text{Softmax}}\left(\|_{i\in[1,h]}ATT - head^{i}(s,e,t)\right)\\ A_{ATT-head}^{i}(s,e,t)&=\left(K^{i}(s)W_{\phi(e)}^{ATT}Q^{i}(t)^{T}\right)\cdot\frac{\mu_{\langle\tau(s),\phi(e),\tau(t)\rangle}}{\sqrt{d}}\\ K^{i}(s)&=\text{K-Linear}_{\tau(s)}^{i}\left(H^{(l-1)}[s]\right)\\ Q^{i}(t)&=\text{Q-Linear}_{\tau(t)}^{i}\left(H^{(l-1)}[t]\right) \end{align*} AttentionHGT(s,e,t)AATT−headi(s,e,t)Ki(s)Qi(t)=∀s∈N(t)Softmax(∥i∈[1,h]ATT−headi(s,e,t))=(Ki(s)Wϕ(e)ATTQi(t)T)⋅dμ⟨τ(s),ϕ(e),τ(t)⟩=K-Linearτ(s)i(H(l−1)[s])=Q-Linearτ(t)i(H(l−1)[t])
Step2. 消息传递
$$
\begin{align*}
\text{Message}{HGT}(s,e,t)&=|{i\in[1,h]}MSG - head^{i}(s,e,t)\
MSG - head{i}(s,e,t)&=\text{M-Linear}_{\tau(s)}{i}\left(H^{(l - 1)}[s]\right)W_{\phi(e)}^{MSG}\
\widetilde{H}^{(l)}[t]&=\underset{\forall s\in N(t)}{\oplus}\left(\text{Attention}{HGT}(s,e,t)\cdot\text{Message}{HGT}(s,e,t)\right)\
H{(l)}[t]&=\sigma\left(\text{A-Linear}_{\tau(t)}\widetilde{H}{(l)}[t]\right)+H^{(l - 1)}[t]
\end{align*}
$$
Heterogeneous Graph Benchmark (HGB)
实验表明在同构图神经网络(例如GCN和GAT)在部分数据集上的表现并不比某些异构图神经网络差。故文章提出了一种既简单又行之有效的异构图建模方法。该方法以GAT作为其主干网络,并使用残差连接和L2正则化等技术对模型进行改进。除此之外还在计算注意力分数时加入边类型嵌入。
α^ij=exp(LeakyReLU(aT[Whi∥Whj∥Wrrψ(⟨i,j⟩)]))∑k∈Niexp(LeakyReLU(aT[Whi∥Whk∥Wrrψ(⟨i,k⟩)])) \hat{\alpha}_{ij}=\frac{\exp\left(\text{LeakyReLU}\left(\boldsymbol{a}^{T}\left[\boldsymbol{W}\boldsymbol{h}_{i}\|\boldsymbol{W}\boldsymbol{h}_{\boldsymbol{j}}\|\boldsymbol{W}_{r}\boldsymbol{r}_{\psi(\langle i,j\rangle)}\right]\right)\right)}{\sum_{k\in\mathcal{N}_{i}}\exp\left(\text{LeakyReLU}\left(\boldsymbol{a}^{T}\left[\boldsymbol{W}\boldsymbol{h}_{\boldsymbol{i}}\|\boldsymbol{W}\boldsymbol{h}_{k}\|\boldsymbol{W}_{r}\boldsymbol{r}_{\psi(\langle i,k\rangle)}\right]\right)\right)} α^ij=∑k∈Niexp(LeakyReLU(aT[Whi∥Whk∥Wrrψ(⟨i,k⟩)]))exp(LeakyReLU(aT[Whi∥Whj∥Wrrψ(⟨i,j⟩)]))


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)