[ADAS预研笔记]感知算法 - 现代深度学习算法结构
现代深度学习算法结构
现代的图像感知算法由三个组件组成:Backbone、Neck和Head。
Backbone
骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet, COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等。
语义分割算法的解码器部分即backbone。
一般而言,一个网络backbone包括多个Stages,每个Stage包含多个Block。
- Stage是指卷积提取特征中,feature map的size是逐级降低的,同一个feature map分辨率之间的所有网络结构叫做一个Stage;
- Block是指用于构建网络的基本单元,每个block包含卷积层、pooling层等基本操作。
在进行感知算法设计时,会创造或优化Block,并搭建一个或多个Stage;网络搜索设计同样也是基于这种结构分解来搜索合适的网络。
Neck
Neck可以认为是backbone和head的连接层,主要负责对backbone的特征进行高效融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等。
此处的融合指同一传感器输入下所提取的特征的融合,与多传感器之间的特征融合不同。
最常用的Neck是FPN(Feature Pyramid Network, 特征金字塔),在目标检测和语义分割中都有应用,详见上文介绍。
Head
Head用来处理backbone或neck的特征图,根据Head的不同可以实现不同的感知功能。
-
分类头:(全连接层+softmax)
-
检测头:分类 + 回归
-
分割头:解码器 + 语义预测/(实例预测+实例回归)
以YOLO的HEAD部分为例,HEAD部分在不同尺度的特征图上分别做检测,然后汇总得到初步的Bouding Box, 最后做非极大值抑制(NMS),筛选合并Bounding Box, 输出最终的结果。
HEAD结构可以参考下图:
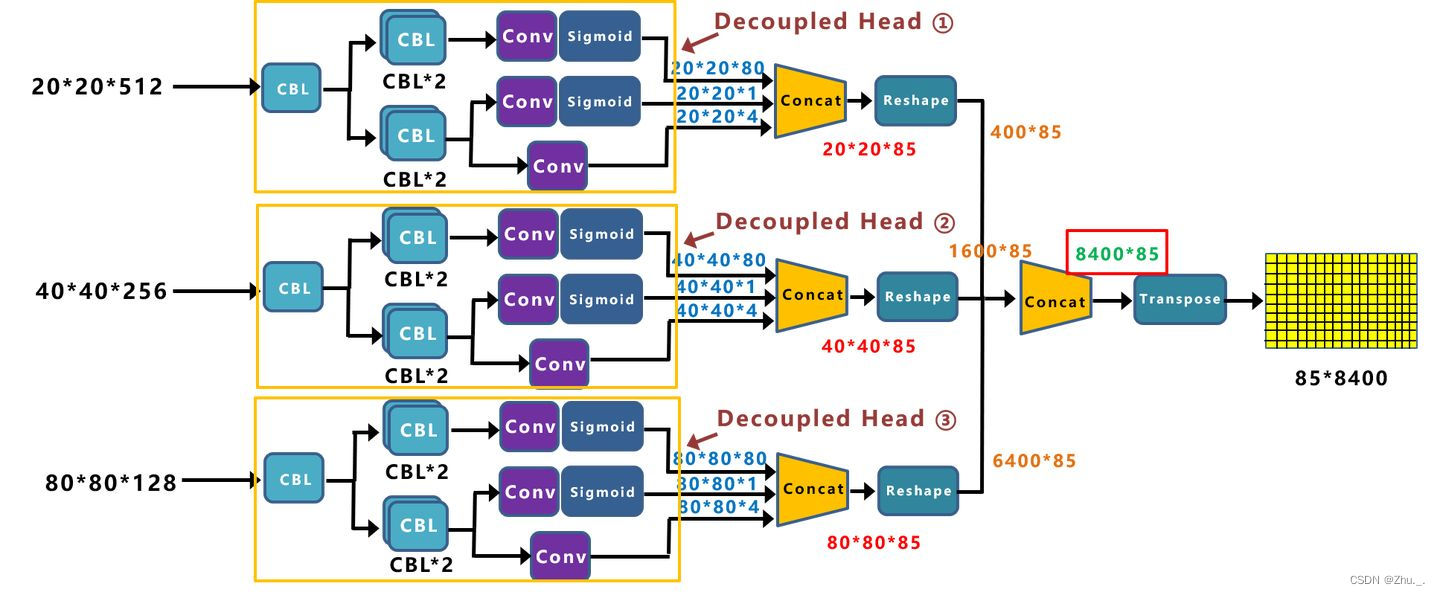
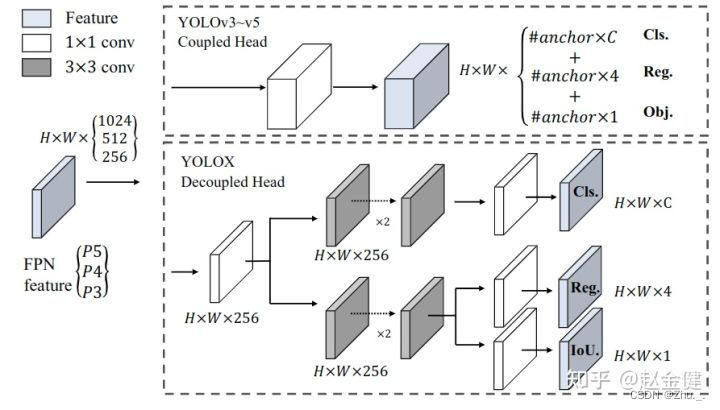
图中展示的是yolox模型的HEAD结构,使用了去耦合的检测头 Decoupled Head。yolov5中使用的是普通的Coupled Head,其余结构是一样的。
Decoupled Head和Coupled Head的差异如下图所示:
每个Head分支输出张量(tensor)的长宽与输入的特征图的长宽保持一致,
- 张量的深度 = 检测类别 + 5,
- 其中5表示Bouding Box的x坐标,y坐标,w宽度,h高度,score置信度。
图中的检测类别有80种,因此输出的张量深度=80+5。3个分支输出的不同尺寸的张量经过reshape,concat,合并成一个8400*85的矩阵,其实就是8400个Bouding Box。
这些初步的Bouding Box包含了许多重复的box, 需要做进一步的NMS处理。NMS处理的效果如下图所示:
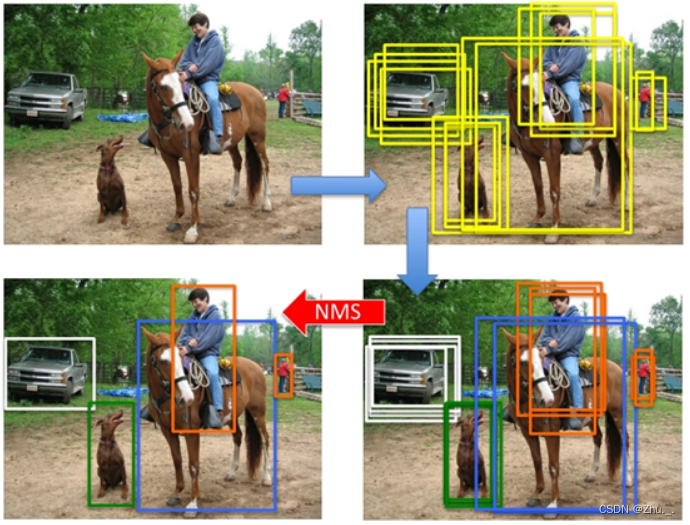
经过NMS处理后,得到最终输出的bbox信息与分类信息。
发展路线
单任务环境感知:
-
更深的网络:即上文图像分类算法的发展历程,AlexNet->VGG->Inception->Xception->ResNet->ResNext->SENet
-
更好的网络设计:网络搜索概念下的NasNet、EfficientNet、RegNet;通过Transformer的设计来模态CNN得到的ConvNeXt
-
更多的特征融合:DenseNet、FPN、DLA、HRNet、PANet、EfficientDet
多任务环境感知:单个深度学习模型能够同时完成两个或两个以上的检测任务
-
共享部分:backbone输出特征图到neck进行增强与融合,再输出给多个head
-
多任务部分:head中基于特征图继续提取特征,不同的head基于不同的任务进行不同形式的特征提取并输出结果计算loss,总体loss由多任务loss加权得到

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)