Kafka集成Flume/Spark/Flink(大数据)/SpringBoot
集成
·
Kafka集成Flume
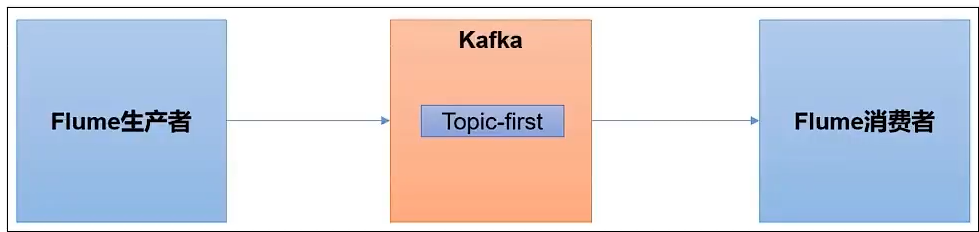
Flume生产者

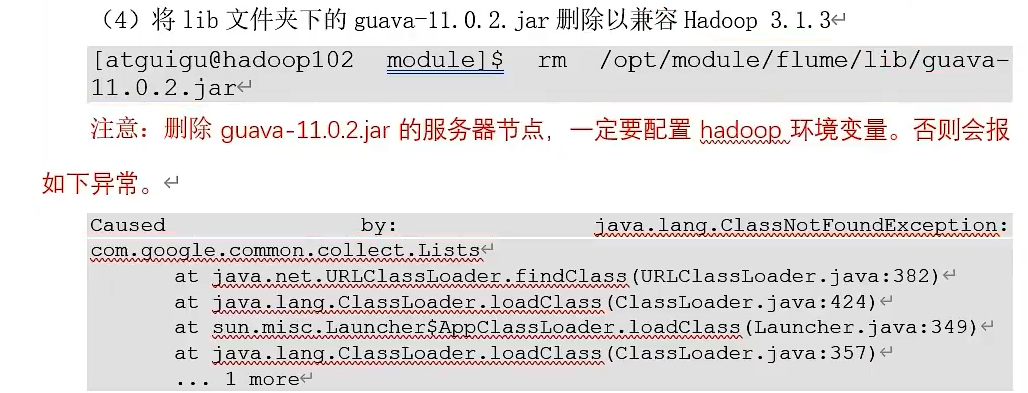
③、安装Flume,上传apache-flume的压缩包.tar.gz到Linux系统的software,并解压到/opt/module目录下,并修改其名称为flume


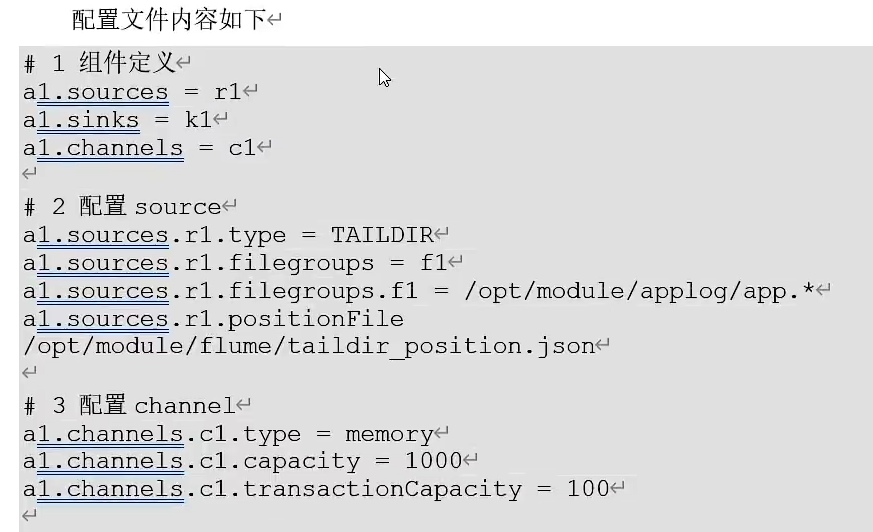
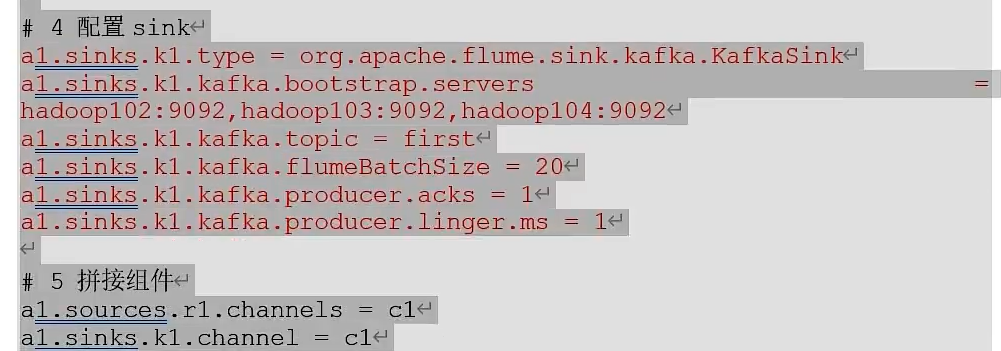




Flume消费者
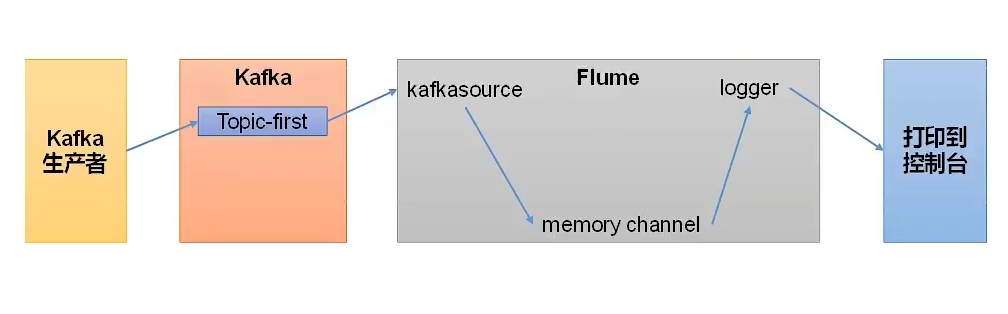

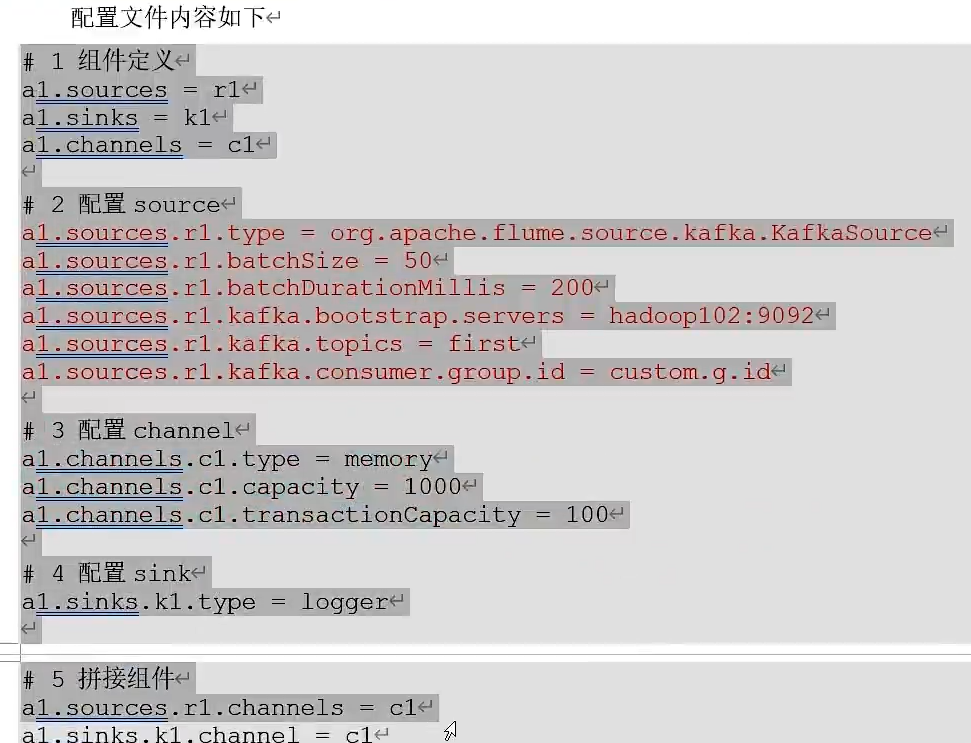


Kafka集成Spark
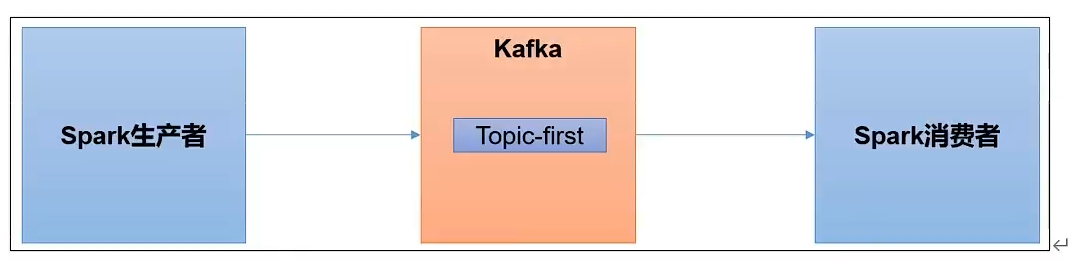


生产者

object SparkKafkaProducer{
def main(args:Array[String]):Unit = {
//配置信息
val properties = new Properties()
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092")
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
//创建一个生产者
var producer = new KafkaProducer[String,String](properties)
//发送数据
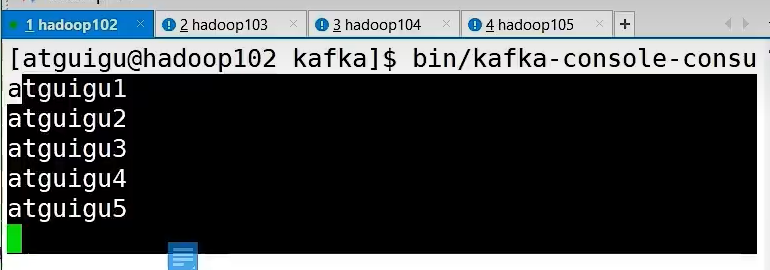
for(i <- 1 to 5){
producer.send(new ProducerRecord[String,String]("first","atguigu"+i))
}
//关闭资源
producer.close()
}
}
消费者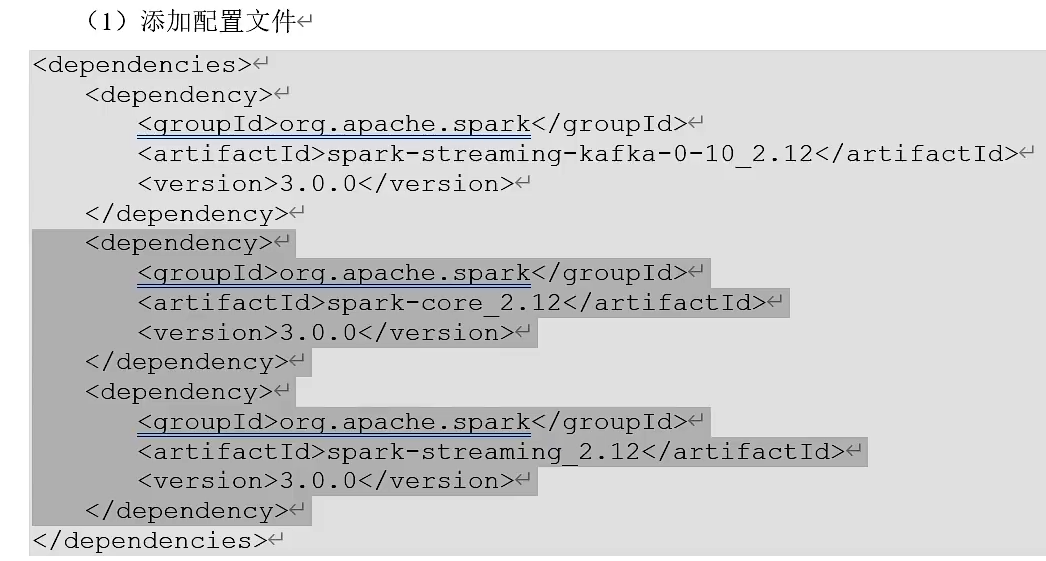
Object SparkKafkaConsumer{
def main(args:Array[String]):Unit = {
//初始化上下文环境
val conf = new SparkConf().setMaster("local[*]").setAppName("spark-kafka")
val ssc = new StreamingContext(conf,Seconds(3))
//消费数据
val kafkapara = Map[String,Object](
ConsumerConfig.BOOT_STRAP_SERVERS_CONFIG->"hadoop102:9092,hadoop103:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.GROUP_ID_CONFIG->"test"
)
val kafkaDStream = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreFerConsistent
,ConsumerStrategies.Subscribe[String,String](Set("first"),kafkapara))
val valueDStream = kafkaDStream.map(record=>record.value())
valueDStream.print()
//执行代码,并阻塞
ssc.start()
ssc.awaitTermination()
}
}
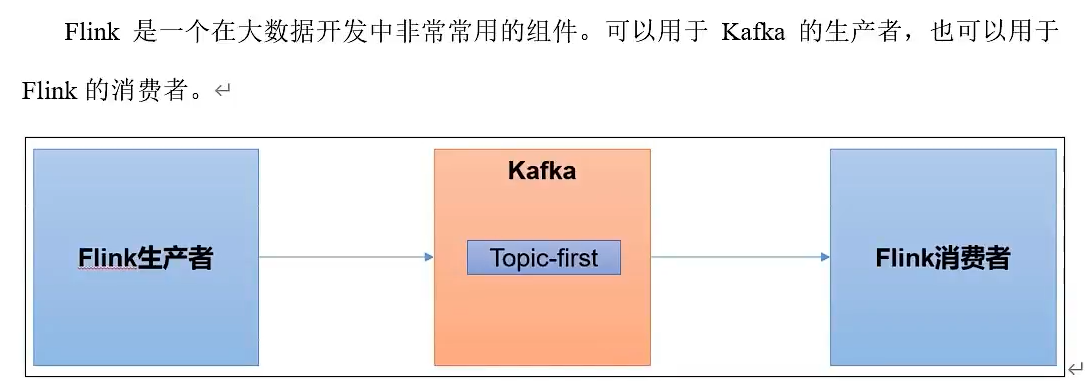
Kafka集成Flink
创建maven项目,导入以下依赖
resources里面添加log4j.properties文件,可以更改打印日志的级别为error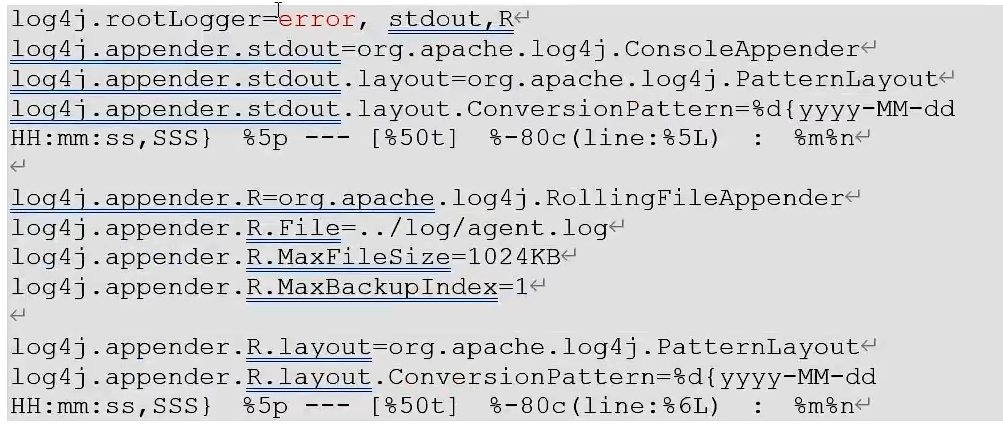
Flink生产者
public class FlinkafkaProducer1{
public static void main(String[] args){
//获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//准备数据源
ArrayList<String> wordList = new ArrayList<>();
wordList.add("hello");
wordList.add("atguigu");
DataStreamSource<String> stream = env.fromCollection();
//创建一个kafka生产者
Properties properteis = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("first",new SimpleStringSchema(),properties);
//添加数据源Kafka生产者
stream.addSink(kafkaProducer);
//执行
env.execute();
}
}
Flink消费者
public class FlinkafkaConsumer1{
public static void main(String[] args){
//获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//创建一个消费者
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("first",new SimpleSStringSchema(),properties);
//关联消费者和flink流
env.addSource(kafkaConsumer).print();
//执行
env.execute();
}
}
Kafka 作为高吞吐的分布式消息队列,承接交易日志、用户行为等实时数据
Flink 消费 Kafka 数据并实时处理,替代传统的定时批处理任务
实时风控:检测盗刷、频繁转账等异常行为(如1分钟内同一卡号多笔大额交易)
交易监控:实时统计支付成功率、渠道分布
动态定价:基于市场行情实时调整外汇汇率
/**
Flink实时处理作业
*/
public class FraudDetectionJob{
public static void main(String[] args)throws Exception{
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);//每5秒做一次Checkpoint
//2.定义Kafka Source
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "kafka1:9092,kafka2:9092");
kafkaProps.setProperty("group.id", "flink-fraud-detection");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"transactions",
new SimpleStringSchema(),
kafkaProps
);
kafkaSource.setStartFromLatest();//从最新偏移量开始
//3.数据处理逻辑
DataStream<Transaction> transactions = env
.addSource(kafkaSource)
.map(json -> JSON.parseObject(json, Transaction.class)); // JSON解析
// 4. 风控规则:检测1分钟内同一卡号超过3次大额转账
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getCardNo) // 按卡号分组
.window(TumblingEventTimeWindows.of(Time.minutes(1))) // 1分钟滚动窗口
.process(new FraudDetector());
// 5. 输出告警到Kafka
alerts.addSink(new FlinkKafkaProducer<>(
"alerts",
new AlertSerializer(),
kafkaProps
));
env.execute("Real-Time Fraud Detection");
}
// 自定义风控逻辑
public static class FraudDetector extends ProcessWindowFunction<Transaction, Alert, String, TimeWindow> {
@Override
public void process(
String cardNo,
Context context,
Iterable<Transaction> transactions,
Collector<Alert> out
) {
int largeTxCount = 0;
for (Transaction tx : transactions) {
if (tx.getAmount() > 50000) { // 大额交易阈值
largeTxCount++;
}
}
if (largeTxCount >= 3) {
out.collect(new Alert(cardNo, "高频大额转账风险"));
}
}
}
}
在这里插入代码片
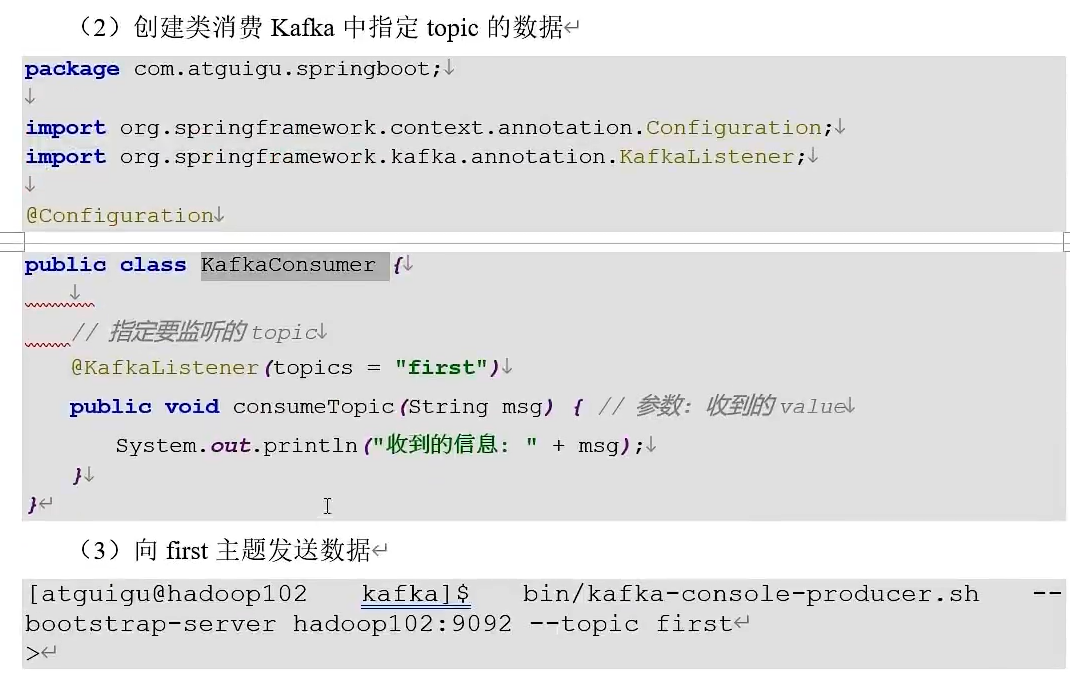
Kafka集成SpringBoot
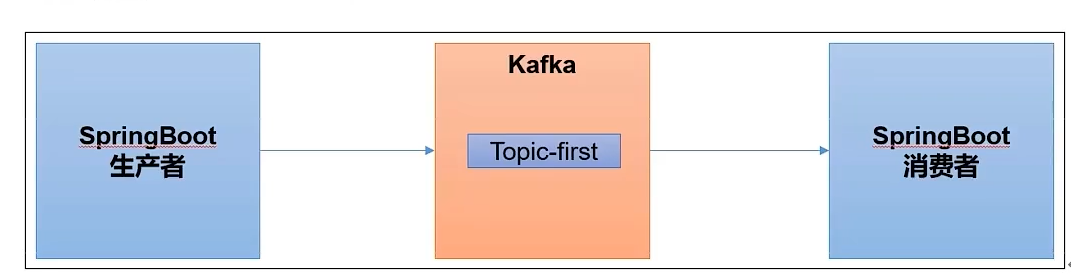
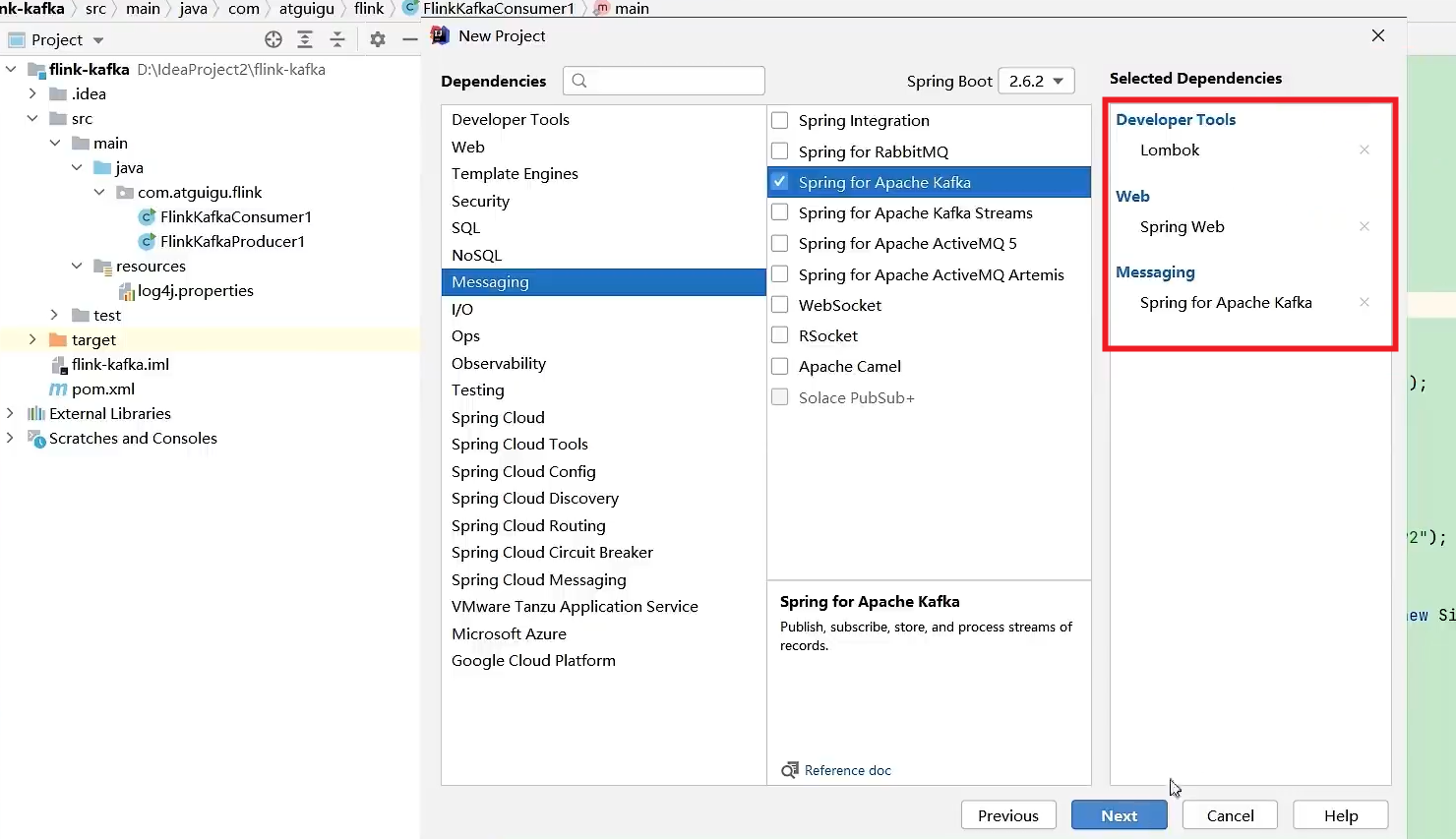
生产者

通过浏览器发送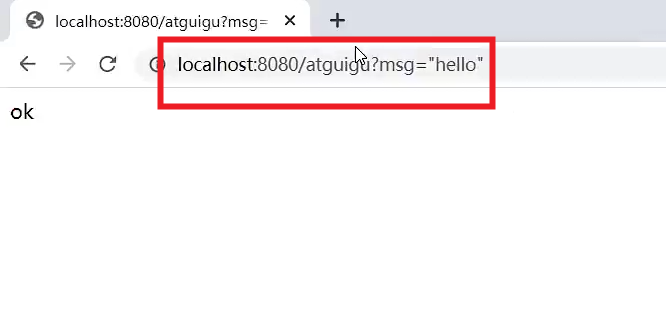
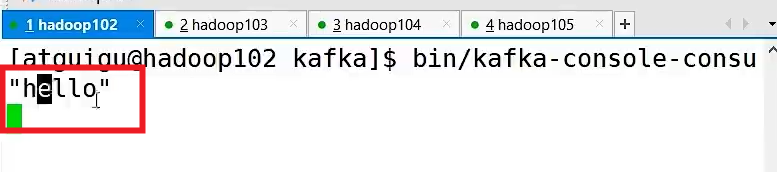
消费者


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)