自然语言处理实验—用隐马尔可夫模型在分词中的应用计算概率矩阵(含python代码和详细例子解释)
自然语言处理基础算法—隐马尔可夫模型在分词中的应用一、问题导入最近,从头到尾学习了隐马尔可夫模型,这个模型十分神奇,核心思想就是过去发生的,现在发生的,和将要发生的,都只和这个时间的前一个事件相关。简单来说,你考试过不过我只看成绩,和你上课表现状况无关。而这些事件相连组成的链条就叫做马尔可夫链。那么问题又来了,为什么叫做隐马尔可夫模型呢?其实就是这里面包含一个隐状态。我们不妨举个例子,比如我和小梦
自然语言处理实验—隐马尔可夫模型在分词中的应用
一、问题导入
最近,从头到尾学习了隐马尔可夫模型,这个模型十分神奇,其核心思想就是过去发生的,现在发生的,和将要发生的,都只和这个时间的前一个事件相关。简单来说,过去的都无所谓,我是看你前一步干了啥。而这些事件相连组成的链条就叫做马尔可夫链。
那么问题又来了,为什么叫做隐马尔可夫模型呢?其实就是因为这里面包含了一个隐状态。我们不妨举个例子,比如我和小梦天天聊天,她每天都会给我讲都干了啥?而不给我说她那边的天气。但是其实我是可以根据经验推测以为她告诉我做的事情推测出来她那边的天气的,这里的天气就是隐状态。很容易理解,隐状态就是根据已知条件去推测的未知状态。
二、隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是描述两个时序序列联合分布p(x,y)的概率模型。
• x序列外界可见(外界指的是观测者),称为观测序列(observation sequence),观测x为单词。
• y序列外界不可见,称为状态序列(state sequence),状态y为词性。
人们也称状态为隐状态(hidden state),而称观测为显状态(visible state)
隐马尔可夫模型之所以称为“马尔可夫模型”,是因为它满足马尔可夫假设。
• 用箭头表示事件的依赖关系(箭头终点是结果,依赖于起点的因缘)
隐马尔可夫模型利用三个要素来模拟时序序列的发生过程
• 初始状态概率向量
• 状态转移概率矩阵
• 发射概率矩阵(也称作观测概率矩阵)
为了说明这三个要素,我们如下图所示,来模拟一个马尔科夫链的过程,由初始状态的转化π\piπ到y1的过程就是初始状态,也就是说要计算这个过程的概率,当然y1可能有很多种可能,他们就组成了向量,这也就是初始状态概率向量。
那么什么是状态转移矩阵呢?我们可以看到当我们现在在状态y1时,马尔可夫链也可以通过A从状态y1转化为y2,同理y2也会有很多种可能,而y1到y2的所有可能就可以组成一个矩阵。这也就是状态转移概率矩阵。
最后的发射矩阵,也叫观测概率矩阵,就是从y1通过B从y1转化到x1。x1也会有很多可能,那么这个就叫做发射概率矩阵。
最后,为了让大家更能体会隐马尔科夫模型。我们举一个具体的实际例子
某医院招标开发“智能”医疗诊断系统,用来辅助感冒诊断。已知
①来诊者只有两种状态:要么健康,要么发烧。
②来诊者不确定自己到底是哪种状态,只能回答感觉头晕、体寒或正常。
③医院认为,感冒这种病,只跟病人前一天的状态有关,并且,当天的病情决定当天的身体感觉。
有位来诊者的病历卡上完整地记录了最近T天的身体感受(头晕、体寒或正常),请预测这T天的身体状态(健康或发烧)。
我么的系统可以通过大数据技术总结出一个状态转移的基本规律,以此为根据可以对来诊者的隐状态(健康,发烧)进行判断。
假设现在规律如下图所示。
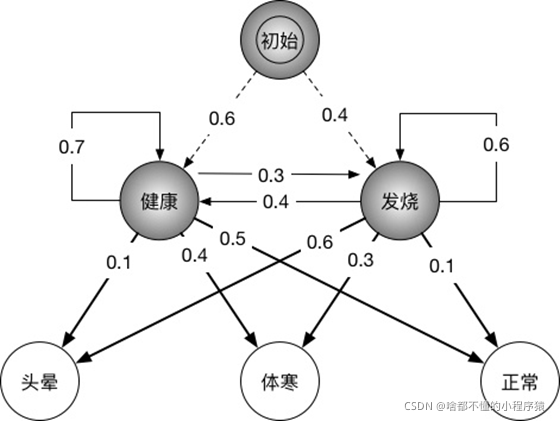
且来诊者告诉我们,最近三天分别显状态x1,x2, x3分别为正常,体寒,头晕。我们根据π\piπ,A,B.来对来诊者的隐状态y1 ,y2 ,y3.
那么我们首先就可以针对这个问题分别建立初始状态概率向量,状态转移概率矩阵,发射概率矩阵。
那么从开始到y1有两种可能,分别是健康和发烧。那么初始状态概率向量π\piπ就是[0.6,0.4]
而从y1经过A到y2可以是健康到健康,健康到发烧,发烧到发烧,发烧到健康,一共四个状态,y1两种,y2也两种。所以状态转移概率矩阵A是一个2 ×\times× 2的矩阵[[0.7,0.3],[0.4,0.6]]
最后对于y1经过B到x1可以是健康表现为头晕、体寒、正常。或者发烧表现为头晕、体寒、正常。那么发射概率矩阵就是一个2 ×\times× 3的矩阵B[[0.1,0.4,0.5],[0.6,0.3,0.1]]
那么根据这三个矩阵我们就可以根据隐马尔可夫模型,对来诊者的状态进行判断。
那么第一天,是正常。只有来诊者只有两个状态,健康和发烧。那么我们就要计算他在不同隐状态的前提下,表现正常的概率。
来诊者健康表现正常的概率是P(normal∣healthy)=0.6×0.5=0.3P(normal\mid healthy)=0.6 \times 0.5 =0.3P(normal∣healthy)=0.6×0.5=0.3
来诊者发烧表现正常的概率是P(normal∣fever)=0.4×0.1=0.04P(normal\mid fever)=0.4 \times 0.1 =0.04P(normal∣fever)=0.4×0.1=0.04
第二天来诊者也只可能有两个状态健康和发烧,分别是健康到健康,健康到发烧,发烧到发烧,发烧到健康。那么我们就要计算不同隐状态的前提下,表现为体寒的概率。
来诊者第一天健康,第二天还健康表现体寒的概率是P(dizzy∣healthy−>healthy)=0.3×0.7×0.4=0.084P(dizzy\mid healthy->healthy)=0.3 \times 0.7 \times 0.4=0.084P(dizzy∣healthy−>healthy)=0.3×0.7×0.4=0.084
来诊者第一天健康,第二天发烧表现体寒的概率是P(dizzy∣healthy−>fever)=0.3×0.3×0.3=0.027P(dizzy\mid healthy->fever)=0.3 \times 0.3 \times 0.3=0.027P(dizzy∣healthy−>fever)=0.3×0.3×0.3=0.027
来诊者第一天发烧,第二天健康表现体寒的概率是P(dizzy∣fever−>healthy)=0.04×0.4×0.4=0.0064P(dizzy\mid fever->healthy)=0.04 \times 0.4 \times 0.4=0.0064P(dizzy∣fever−>healthy)=0.04×0.4×0.4=0.0064
来诊者第一天发烧,第二天发烧表现体寒的概率是P(dizzy∣fever−>fever)=0.04×0.6×0.3=0.0072P(dizzy\mid fever->fever)=0.04 \times 0.6 \times 0.3=0.0072P(dizzy∣fever−>fever)=0.04×0.6×0.3=0.0072
第三天来诊者仍然只可能有两个状态健康和发烧,分别是健康到健康,健康到发烧,发烧到发烧,发烧到健康。那么我们就要计算不同隐状态的前提下,表现为头晕的概率。
来诊者前一天健康,第三天还健康表现头晕的概率是P(dizzy∣healthy−>healthy)=0.084×0.7×0.1=0.00588P(dizzy\mid healthy->healthy)=0.084\times 0.7 \times 0.1=0.00588P(dizzy∣healthy−>healthy)=0.084×0.7×0.1=0.00588
来诊者前一天健康,第三天发烧表现头晕的概率是P(dizzy∣healthy−>fever)=0.3×0.3×0.3=0.01512P(dizzy\mid healthy->fever)=0.3 \times 0.3 \times 0.3=0.01512P(dizzy∣healthy−>fever)=0.3×0.3×0.3=0.01512
来诊者前一天发烧,第三天健康表现头晕的概率是P(dizzy∣fever−>healthy)=0.04×0.4×0.4=0.00108P(dizzy\mid fever->healthy)=0.04 \times 0.4 \times 0.4=0.00108P(dizzy∣fever−>healthy)=0.04×0.4×0.4=0.00108
来诊者前一天发烧,第三天发烧表现头晕的概率是P(dizzy∣fever−>fever)=0.04×0.6×0.3=0.00972P(dizzy\mid fever->fever)=0.04 \times 0.6 \times 0.3=0.00972P(dizzy∣fever−>fever)=0.04×0.6×0.3=0.00972
同理,对于第三天,经过计算可得患者隐状态。从而我们使用了隐马尔科夫模型对患者的隐状态判断,最终根据维特比算法可以得到来诊者第一天健康,第二天健康,第三天发烧的概率最大。即推断患者的隐状态为健康、健康、发烧。
三、隐马尔可夫模型在分词中的应用
相信现在你已经对隐马尔可夫模型已经有了充分的认识,其实这个模型的功能十分强大,可以做很多事情。感兴趣的小伙伴可以自行搜索。相信你一定可以受益良多。这里我们主要介绍隐马尔科夫模型在自然语言处理中的应用,也就是分词算法。
那么首先我们要首先介绍人们提出的{B,M,E,S}这种最流行的标注集
汉字分别作为词语首尾(Begin、End)、词中(Middle)以及单字成词(Single)
举个栗子,对“参观了北京天安门”进行标注
可以想到其实每个字就是隐马尔可夫模型的显状态,而{B,M,E,S}这种标注集就是我们需要的隐状态,通过构建隐马尔科夫模型从而对句子的标准集做出预测,从而达到了对句子的分词。
以此类推对一个分好词的句子我们可以根据目前的状况求出我们需要的初始概率矩阵,状态转移矩阵,状态发射概率矩阵。当然我们可以想到,当我们对马尔可夫输入的分好词的句子足够多时,那么这三个矩阵对未知分词句子的分词的精度是相当高的。而这个过程就类似于机器学习的与训练。
原理还是一样的,具体细节都在代码里。我们话不多说,直接上代码。该代码的核心思想还是构造隐马尔科夫模型,然后根据输入的句子,计算三个状态概率矩阵
读者注意,代码拷贝命名为文件后,在代码同一目录下,新建文件夹命名为mat_pickle.用于存储模型。
# -- encoding:utf-8 --
import numpy as np
import pandas as pd
import pickle
import copy
def get_tag(word):
tag=[]
if len(word)==1:
tag = ['S']
elif len(word)==2:
tag = ['B','E']
else:
num = len(word)-2
tag.append('B')
tag.extend(['M']*num)
tag.append('E')
return tag
def compute(init_mat,trans_mat,emit_mat):
init_sum = sum(init_mat.values())
for key,value in init_mat.items():
init_mat[key] = round(value/init_sum,3)
for key,value in trans_mat.items():
cur_sum = sum(value.values())
if(cur_sum==0):
continue
for i,j in value.items():
trans_mat[key][i] = round(j/cur_sum,3)
emit_list = emit_mat.values.tolist()
for i in range(len(emit_list)):
cur_sum = sum(emit_list[i])
if (cur_sum == 0):
continue
for j in range(len(emit_list[i])):
emit_mat.iloc[i,j] = round(emit_list[i][j]/cur_sum,3)
def markov(txt,init_mat,trans_mat,emit_mat):
list_all = txt.split(" ")
print("词库", list_all)
sentence = "".join(list_all)
#处理发射矩阵
original = [i for i in sentence]
list_column = [0, 0, 0, 0]
df_column = [column for column in emit_mat]
for item in original:
if item not in df_column:
emit_mat[item] = list_column
#处理BMSE
single = []
for word in list_all:
word_tag = get_tag(word)
single.extend(word_tag)
BMES.append(single)
print("BMES:", BMES)
item = single.copy()
first = item[0]
init_mat[first] += 1
for i in range(len(item) - 1):
i1 = item[i]
i2 = item[i + 1]
trans_mat[i1][i2] += 1
for i, j in zip(item, original):
emit_mat.loc[i, j] += 1
if __name__ == "__main__":
init_mat = {'B': 0, 'M': 0, 'E': 0, 'S': 0}
trans_mat = {'B': {'B': 0, 'M': 0, 'E': 0, 'S': 0}, 'M': {'B': 0, 'M': 0, 'E': 0, 'S': 0},
'E': {'B': 0, 'M': 0, 'E': 0, 'S': 0}, 'S': {'B': 0, 'M': 0, 'E': 0, 'S': 0}}
BMES = []
emit_mat = pd.DataFrame(index=['B','M','E','S'])
while (1):
print("请在下面输入你要分词的句子(用空格将词分开,输入0结束输入),例如:项目 的 研究")
a = input("情输入:")
if (a == '0'):
print("输入结束!正在存储模型矩阵...")
with open('./mat_pickle/init_mat.pkl',"wb") as f0:
pickle.dump(init_mat,f0)
with open('./mat_pickle/trans_mat.pkl',"wb") as f1:
pickle.dump(trans_mat,f1)
with open('./mat_pickle/emit_mat.pkl',"wb") as f2:
pickle.dump(emit_mat,f2)
print("存储模型成功!")
break
markov(a,init_mat,trans_mat,emit_mat)
init_mat_compute = copy.deepcopy(init_mat)
trans_mat_compute = copy.deepcopy(trans_mat)
emit_mat_compute = copy.deepcopy(emit_mat)
print(init_mat)
print(trans_mat)
print(emit_mat)
compute(init_mat_compute,trans_mat_compute,emit_mat_compute)
print("当前初始状态向量", init_mat_compute)
print("当前转移矩阵", trans_mat_compute)
print("当前发射矩阵:",emit_mat_compute)
至大家
这次的博客原创性很强,基本都是自己写的自己对隐马尔可夫模型的理解,应该通俗易懂,但是笔者还是水平有限。如果,哪里写的有误和不足之处,还请大家指出,我一定改正,哈哈!看到这里点赞个再走呗!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)