codeformer:towards robust blind face restoration with codebook lookup transformer
刚好上班又到了我分享论文的时候,顺便分享给大家,有啥想法可以留言交流hhh,这个字幕机翻的有点蠢,大家将就看一下,下次不弄字幕了。vqgan和vqvae是一致的,通过编码器得到特征之后,通过最近邻匹配,训练解码器,这个流程训练好之后,丢掉编码器,只要解码器,但是做无监督生成的话,你就需要有一个对应的index表,这样才能从codebook中找出对应的embedding去得到解码器的输入,那么这个i
 https://www.bilibili.com/video/BV11M4y1U7z2/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV11M4y1U7z2/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
低质量图输入,输出高质量图,和通用超分一个路子。codeformer和下面两张图的思路不太一样,它的一个motivataion是目前一些模型在严重退化过程中,对低质量输入是很敏感的,当这个低质量的输入稍微发生抖动或者变化,高质量的hr输出就会变化很大,质量退化比较严重,这是什么原因呢?比如gfpgan在网络中有大量的跳跃连接,就是残差结构,会把低质量的一些信息传到后面解码器中座位它的特征,当你退化很严重时,一些低质量的图的特征会直接影响hr的生成。
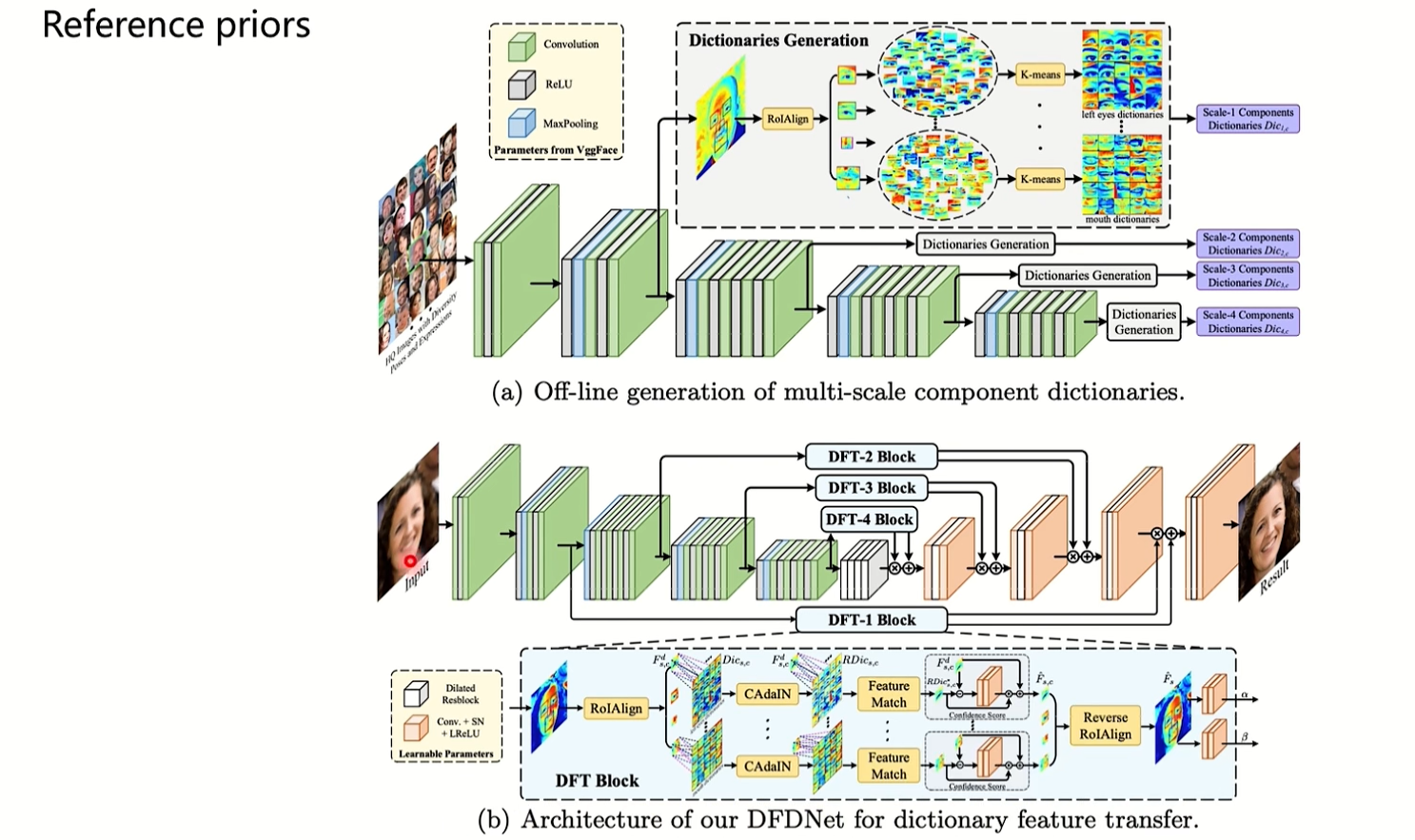
上面这一张图是参考先验,在生成过程中,会拿一些高质量的人脸图像去训练,模型会从高质量人脸图像中自动学习到一些人脸的结构或者特征,把它当成一个参考先验去指导去指导低质量图片图像生成。
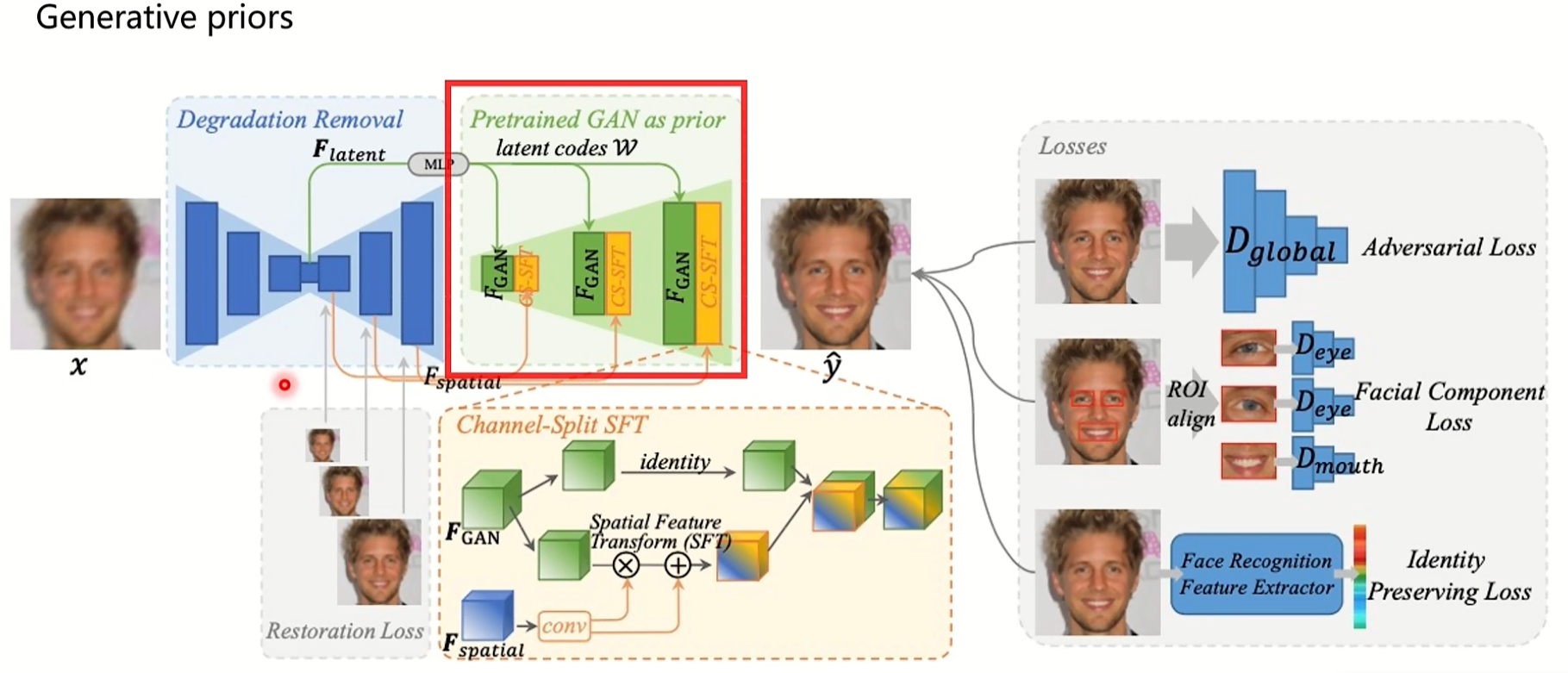
上面这张图是gfpgan,是生成先验,用一个训练好的网络作为一个生成器,把低质量的人脸图进行一个编码解码,之后把不同层次的特征送入到已经训练的stylegan中辅助图像生成。

1.codeformer把人脸超分任务转化为预测一个离散的codebook,以往的方法都是预测一个连续的隐向量,通过编码器预测之后的到一个解码,作为解码器的输入,但是codeformer不是编码到一个连续的空间,而是编码到一个离散的codebook中,比如codebook是1024维的,数量是1024, 维度是256,预测到codebook中是因为把图像映射到一个连续的空间中,这个范围太大了,codebook是一个有限的空间,完成了一个张图到一个较小的codebook的映射,将不确定性大大减少,也会减少网络对于lr的依赖,因为codeformer基本没用残差连结;2.用transformer来代替最近邻匹配。
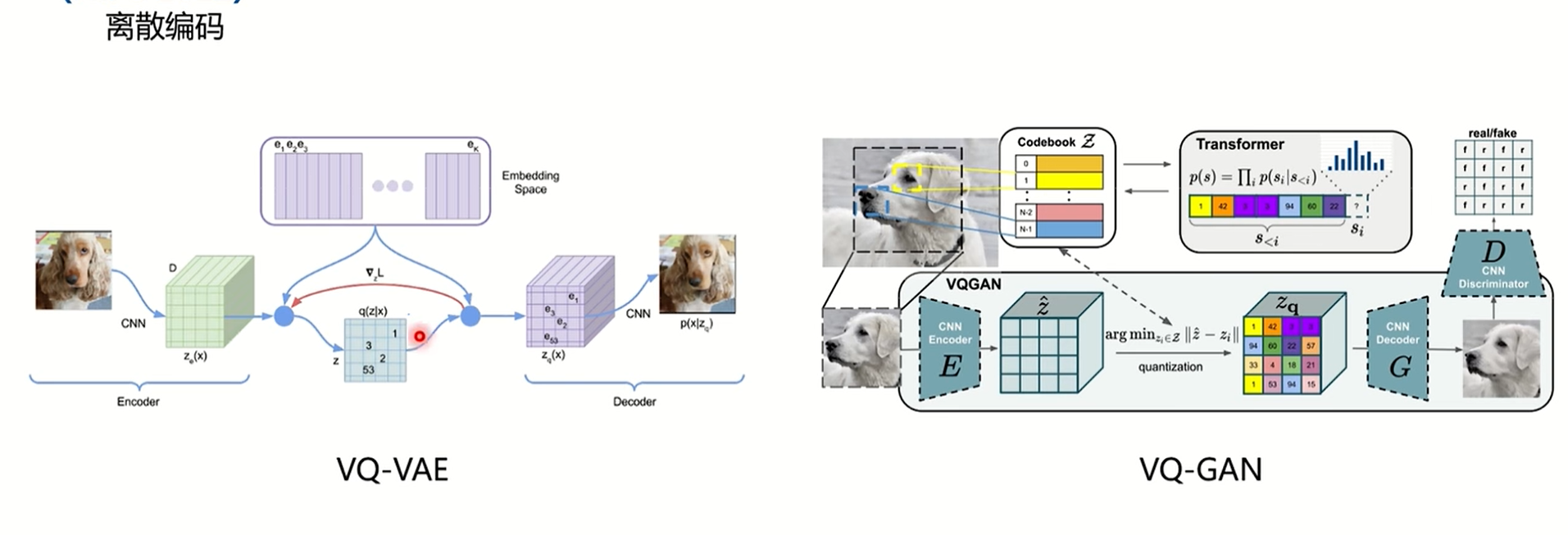
有一张图片,通过一个编码器编码一个特征向量,这个特征向量的维度是mxnxd,如果是vae结构,它是生成一个连续的向量,其实就是生成一个分布,从分布上直接采样送入到解码器中,vqvae多了vq的操作,向量量化,比如这张图上的绿色方块,是mxnxd,深度是d维,第0个方块就是1x1xd,通过在离散的codebook中找一个和它最相近的,codebook维度是1024xd,就把codebook中最近邻的向量的索引放到蓝色表中,用codebook做一个映射,在蓝色的表中的索引赌赢codebook中的embedding,这样的话就可以从蓝色表中的到解码器的输入,再让解码器重建。vqgan和vqvae是一致的,通过编码器得到特征之后,通过最近邻匹配,训练解码器,这个流程训练好之后,丢掉编码器,只要解码器,但是做无监督生成的话,你就需要有一个对应的index表,这样才能从codebook中找出对应的embedding去得到解码器的输入,那么这个index表是通过gpt2生成的,是自回归预测出来的,有个index表就可以得到输入。之所以叫vqgan,只因为加了一些gan的损失。
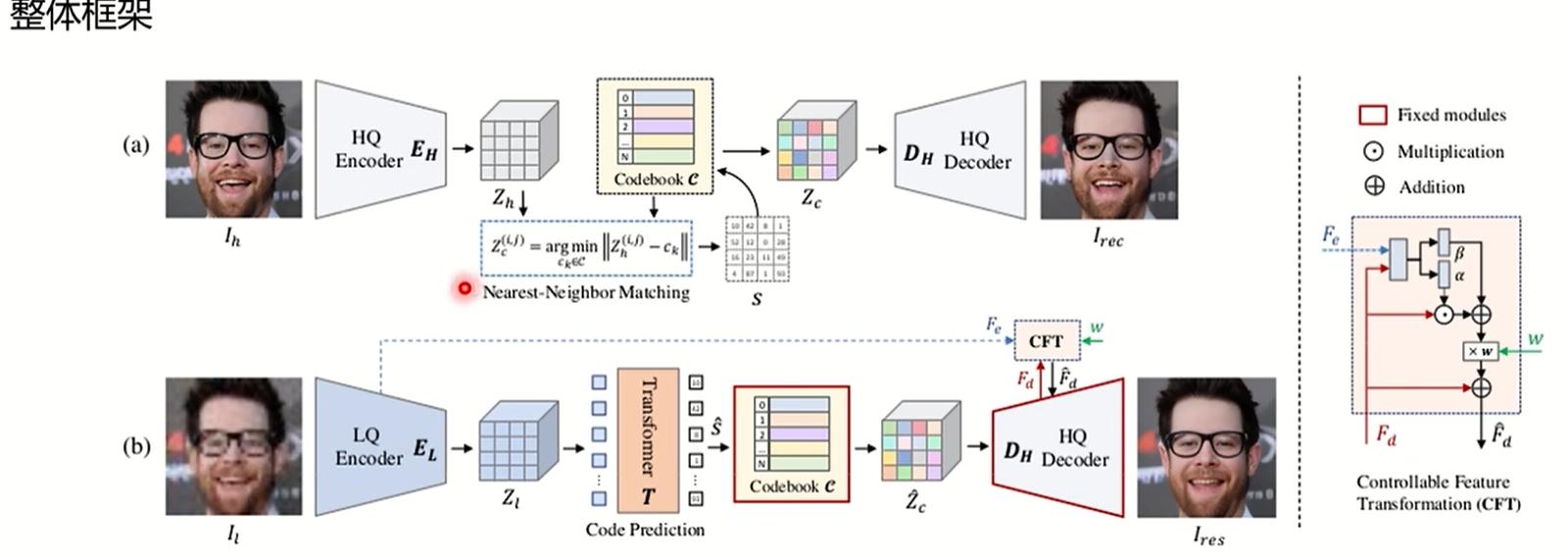
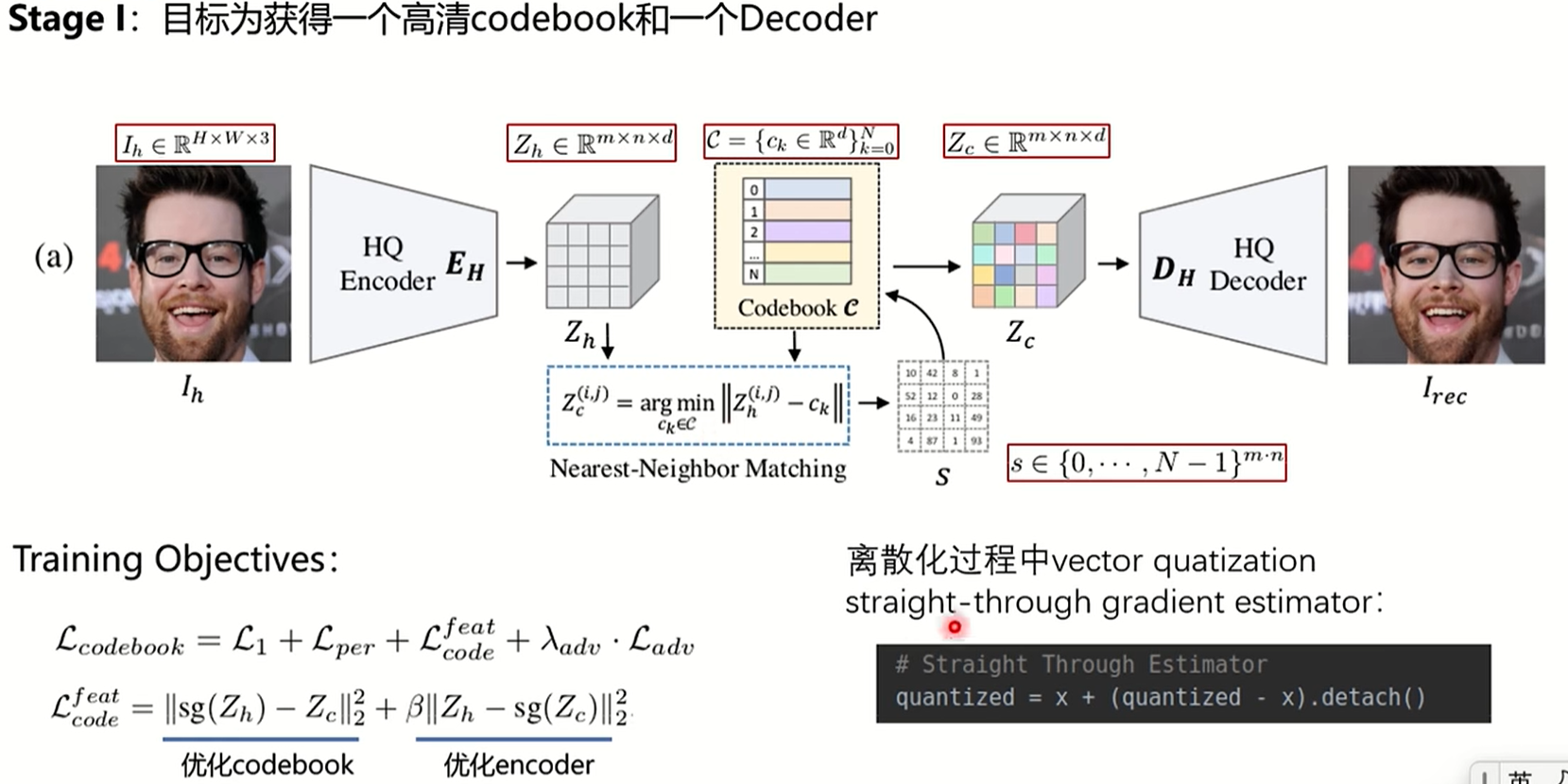
codeformer训练是分成三个部分的,第一阶段是为了获得高清的codebook和一个训练好的decoder,直接用高清的图做输入,输出也是高清图,但这个过程不使用任何残差连接,例如输入是hxwx3,编码之后是mxnxd,和离散编码的过程一个,对mxn位置中的每一个d都去codebook中找最近的embedding,argmin匹配起来,encoder生成的mxnxd其实就是一组特征,从codebook中找最相近的去代替encoder输出的特征,其实就是聚类,相当于codebook中有这么多聚类中心,在最上面图上也可以看到hr的图聚类效果是很好的,从codebook中转化一下就得到zc,作为解码器的输入,这其中如果直接拿lr图训练可能效果不好,所以直接取hr的图训练,可以得到一个真正好的codebook,这种方式没有任何的残差连接,hr是从codebook中恢复出来,最上面的图中的code gt就是从第一阶段生成出来的图,和原图是非常接近的。但是argmin是不可导的,它直接把zc的梯度在反向传播时复制给zh,就是上面那一行代码,quantized就代表zc,上述公式是一个恒等式,其实detach之后,梯度为0了,在第一阶段整体的loss等于l1 loss,其实就是编码解码过程(AE),Lper是感知损失,就是把两张图都送进vgg提取特征之后,比特征的相似度,但是在训练过程中把zc的梯度直接复制给zh,所以codebook实际是未训练的,额外提出了Lcode损失,sg是stop gradient,就是锁住zh的梯度,所以Lcode实际在训练zc,zc是从codebook中的一维组合,所以这一项实际就在优化codebook,第二项同理,就是在优化zh。
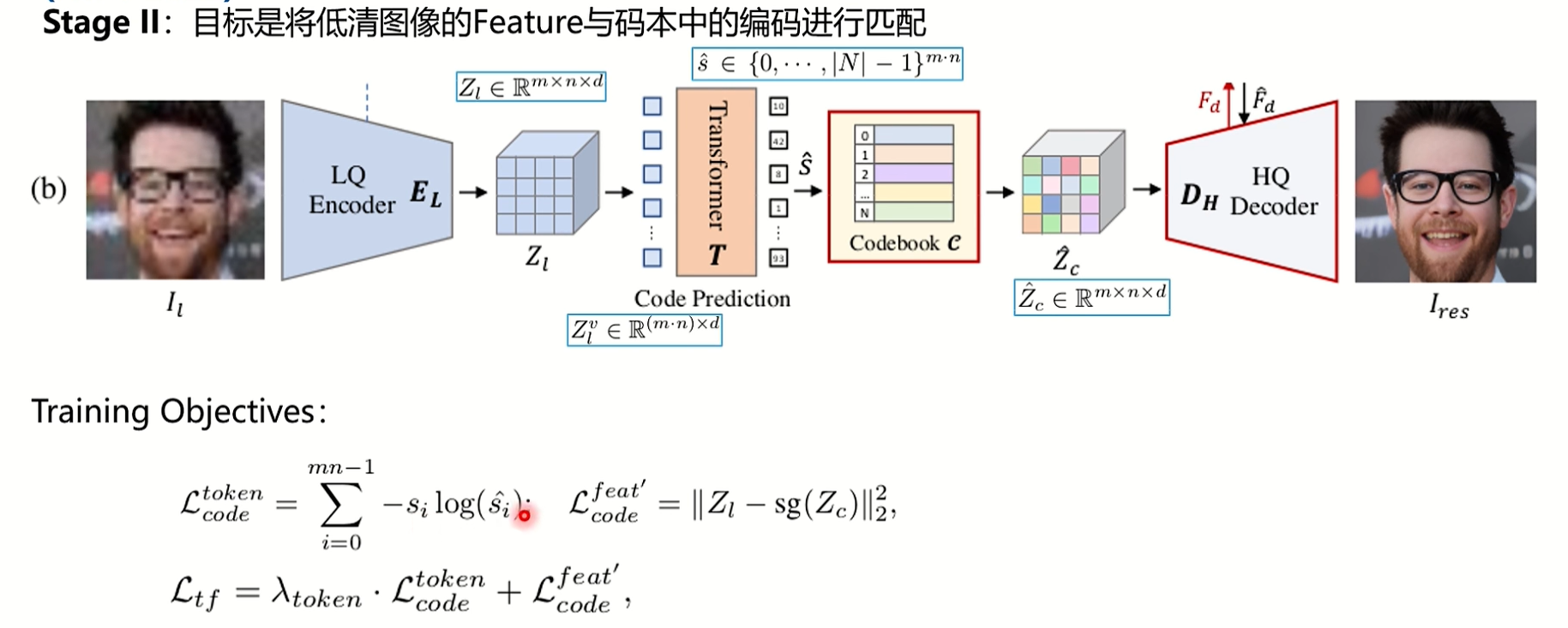
在第一阶段训练得到一个高清的codebook和一个训练好的decoder,第二阶段就是就是将低清的图片的feature和codebook里面的编码匹配起来,这个匹配在第一阶段用的是最近邻匹配,第一阶段之所以用最近邻,是因为在高清图中特征本身就是很好聚类的,但是在退化之后的低清图中,特征是比较难聚类的,此时引入了transformer去代替最近邻,在第二阶段输入是没有高清图的,把一张退化的低清图经过编码器,得到mxnxd的方块,因为使用transformer,所以要对输入输出做下处理,输入变成(mxn)xd,输出变成si,即第一阶段的index表,也是(mxn)xd的,即使用transformer去预测index表,这一段是对code层级的loss训练,不是图像loss,在第一阶段训练hr图时会产生一个si,此时这个si就是gt,这个gt在第一阶段也证明了对于原图的恢复是非常有效的,transformer训练出来的s和si进行监督,Lcode变成了一个交叉熵损失函数,后面这部分损失和之前时一样的,此时训练的就是前面这个编码器,有两个损失。
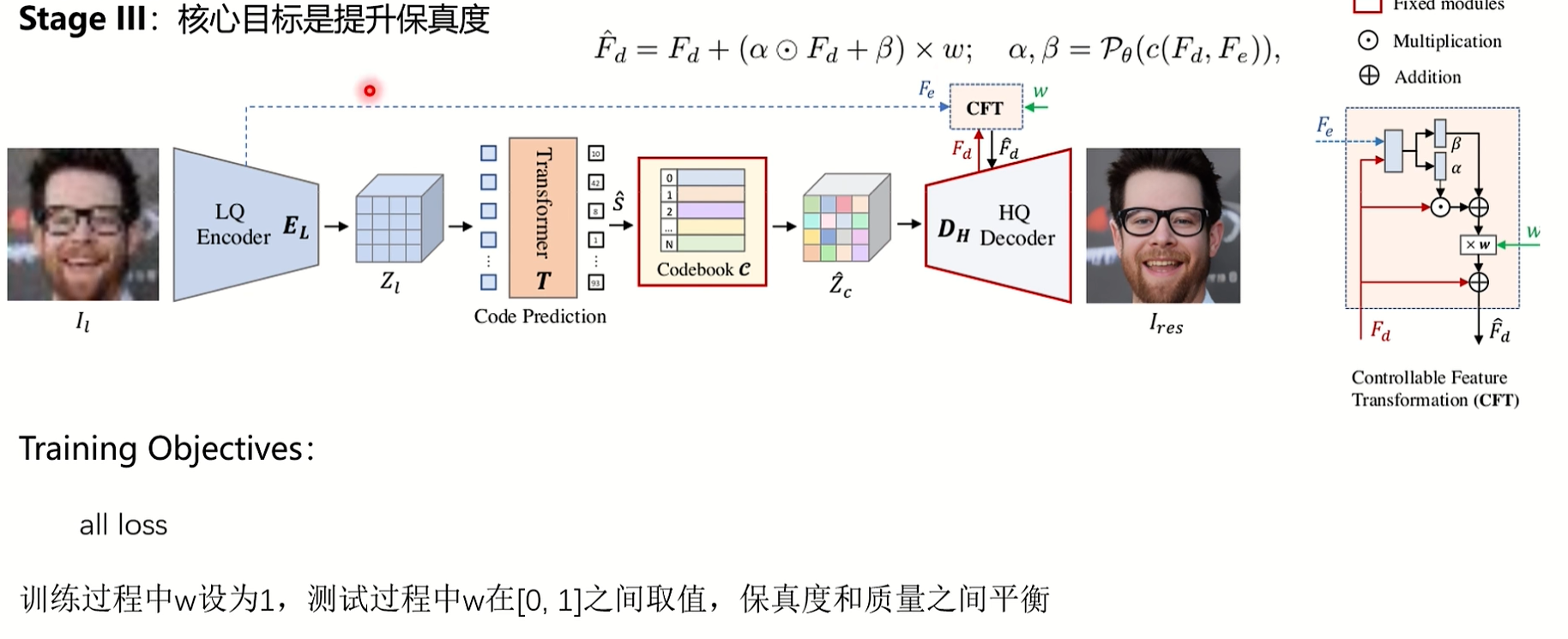
第三阶段是保真度和质量之间的平衡,保真度是因为你没有残差连结,所以生成出来的图可能质量很高,但是和原图不像,所以需要添加一个约束,所以在训练过程中,w一般取0.5,其实就是通过残差连接来控制和原图的相似度。这一阶段会把所有的损失都用上。



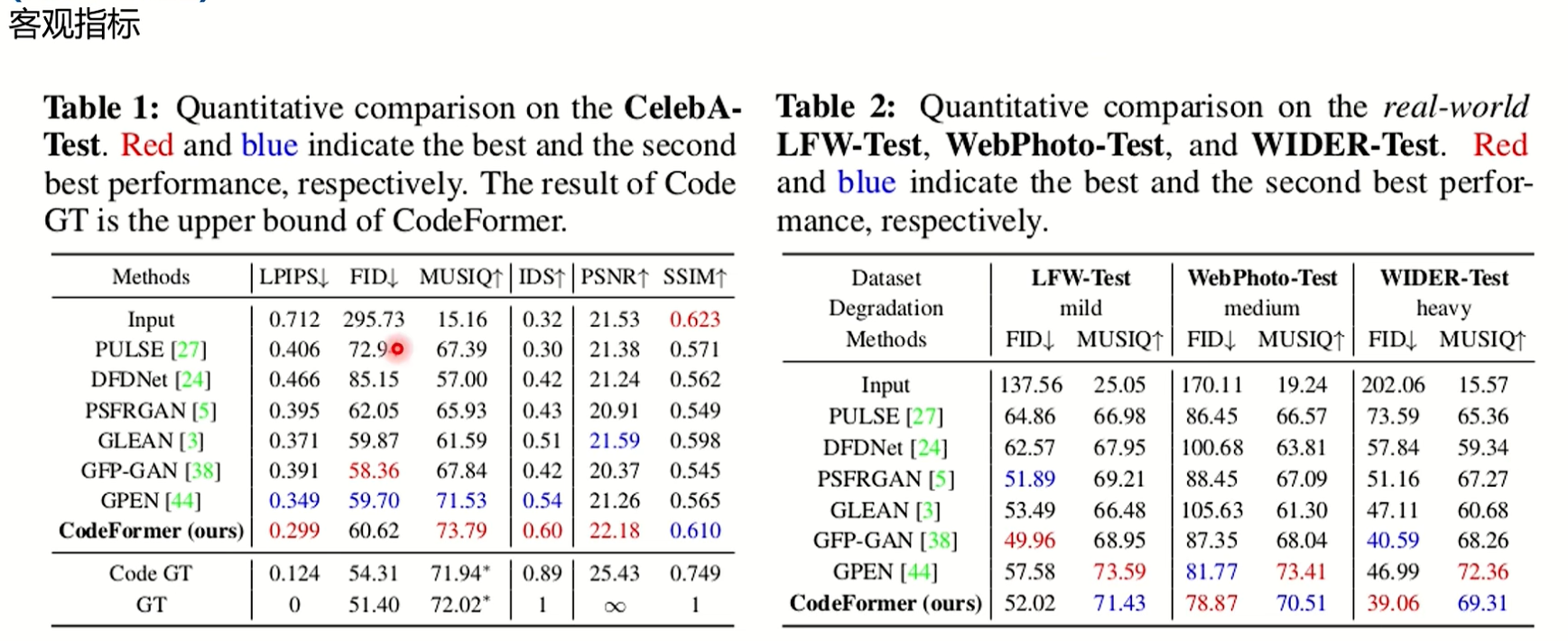
GFPGAN在真实场景上效果也很好,但是在合成场景上效果不行。




把去噪的图输入转成了匹配问题。把连续的空间转到离散空间,把解空间减小减弱,分类问题因为往往有有限解,而回归问题有无限解,难度会大一点。detr会比传统的box回归能力上传会大一点吗?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)