Spark大数据处理实战指南:从入门到进阶
分析某电商平台的用户行为数据,包括:(1)用户浏览记录;(2)购买记录;(3)评价数据。Spark作为大数据处理的利器,掌握它能让你在大数据领域游刃有余。本文从基础概念到实战应用,带你全面了解Spark的核心技术。记住:(1)理解RDD和DataFrame的区别与联系;(2)掌握常用的转换和动作操作;(3)学会性能优化技巧;(4)多动手实践真实项目。
一、初识Spark
大数据处理的瑞士军刀 Apache Spark作为当今最流行的大数据处理框架之一,已经成为大数据领域不可或缺的工具。作为一名大数据技术学习者,掌握Spark的使用是必备技能。
1.1 Spark的核心优势
(1)闪电般的速度:内存计算比Hadoop MapReduce快100倍;
(2)一站式解决方案:SQL查询、流处理、机器学习、图计算全支持;
(3)开发者友好:支持Python、Scala、Java、R多种语言;
(4)强大的生态系统:与Hadoop、Kafka等完美集成。
1.2 Spark适用场景
(1)海量数据ETL处理;
(2)实时数据分析;
(3)机器学习模型训练;
(4)图数据分析。
二、Spark核心架构解析
2.1 Spark核心组件
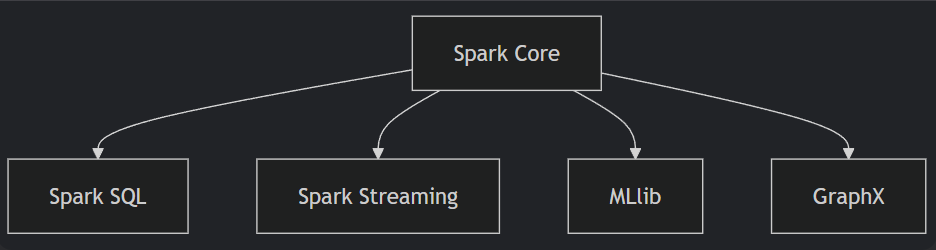
2.2 Spark运行架构
Driver程序:负责任务调度
Executor:真正执行任务的进程
Cluster Manager:资源管理器(Standalone/YARN/Mesos)
三、Spark编程模型实战
3.1 RDD编程基础
(1)创建RDD的三种方式
# 1. 从集合创建
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 2. 从外部存储系统
rdd = sc.textFile("hdfs://path/to/file")
# 3. 从其他RDD转换
new_rdd = rdd.map(lambda x: x*2)
(2)常用转换操作
# map: 一对一转换
rdd.map(lambda x: x+1)
# filter: 过滤
rdd.filter(lambda x: x>3)
# flatMap: 一对多转换
rdd.flatMap(lambda x: range(x))
# distinct: 去重
rdd.distinct()
# sample: 采样
rdd.sample(False, 0.5)
3.2 DataFrame编程进阶
(1)DataFrame创建与操作
# 创建DataFrame
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
df = spark.createDataFrame(
[(1, "Alice"), (2, "Bob")],
["id", "name"]
)
# 基本操作
df.show()
df.printSchema()
df.select("name").show()
df.filter(df["id"] > 1).show()
(2)聚合操作
from pyspark.sql import functions as F
df.groupBy("department") \
.agg(F.avg("salary"), F.max("age")) \
.show()
四、Spark性能优化技巧
4.1 数据分区优化
# 合理设置分区数
rdd = rdd.repartition(100) # 增加分区
rdd = rdd.coalesce(10) # 减少分区
4.2 缓存策略选择
rdd.persist(StorageLevel.MEMORY_ONLY) # 仅内存
rdd.persist(StorageLevel.MEMORY_AND_DISK) # 内存+磁盘
4.3 数据倾斜处理
# 加盐处理解决数据倾斜
from pyspark.sql.functions import rand
df = df.withColumn("salt", (rand() * 10).cast("int"))
result = df.groupBy("key", "salt").agg(...)
五、Spark实战项目:电商用户行为分析
5.1 项目概述
分析某电商平台的用户行为数据,包括:
(1)用户浏览记录;
(2)购买记录;
(3)评价数据。
5.2 核心代码实现
# 1. 数据加载
user_behavior = spark.read.parquet("hdfs://user_behavior/")
# 2. 用户购买转化率分析
conversion_rate = user_behavior.groupBy("user_id") \
.agg(
(F.sum(F.when(F.col("action") == "purchase", 1).otherwise(0)) /
F.count("*")).alias("conversion_rate")
)
# 3. 热门商品统计
top_products = user_behavior.filter(F.col("action") == "view") \
.groupBy("product_id") \
.count() \
.orderBy(F.desc("count")) \
.limit(10)
六、总结
Spark作为大数据处理的利器,掌握它能让你在大数据领域游刃有余。本文从基础概念到实战应用,带你全面了解Spark的核心技术。记住:
(1)理解RDD和DataFrame的区别与联系;
(2)掌握常用的转换和动作操作;
(3)学会性能优化技巧;
(4)多动手实践真实项目。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)