Python情感分析+TF-IDF关键词+Gephi共现(大连理工情感词库)
目录
前言
最近使用Python做了一个以大连理工情感词库为基础,数据方面是爬取了一定有关书籍的评论数据的中英文数据,用来做“基于情感词典的文本正负向情感分类”的项目。具体的需求文档需求在顶部自取!以下是简要对文档的描述!
步骤一:用TF-IDF算法提取出中英文评论中得分较高的情感词,再通过人工筛选出100左右的专属情感词典,再与大连理工情感词库合并形成一个新情感词库,(PS:这是一个创新点,可以提高最终的正负向分类的准确率)。然后通过算法计算出每一个评论的得分情况,最终得出分类结果。
步骤二:得出分类结果后,分4组各提取Top 50高频词+TF-IDF值(分组:中文正面、中文负面、英文正面、英文负面),随后构建关键词列表,绘制出词云图。
步骤三:构建共现语义矩阵,并且使用Gephi绘图,计算模块化值、度中心性、接近中心线、中介中心性,得出最终数据表格导出csv文件。
(PS:此分享非免费分享,只展示部分代码。需要全套代码和数据结果,请关注私信联系!!!!)
基于情感分析与关键词共现的文本挖掘实践
一、项目背景与目标
在当今数字化时代,文本数据的分析与挖掘已成为信息处理领域的重要课题。本文将详细介绍一个基于情感分析、关键词提取以及共现语义网络构建的文本挖掘项目。该项目旨在通过对中英文评论的情感分类、关键词提取以及共现关系分析,深入挖掘文本数据中的潜在信息。
项目目录图如下: 此目录中其中step1-step3放置的是各步骤响应的代码文件。全部文件与数据文件的详细描述均存放在readme.md文件中,部分内容如下:
此目录中其中step1-step3放置的是各步骤响应的代码文件。全部文件与数据文件的详细描述均存放在readme.md文件中,部分内容如下:
二、情感分析:精准分类文本情感倾向
情感分析是文本挖掘中的核心任务之一,其目的是通过分析文本内容,判断文本的情感倾向是正面、负面还是中性。本项目采用基于情感词典的方法实现情感分析。
1. 情感词典构建
情感词典是情感分析的基础,其质量直接影响分析结果的准确性。本项目构建了专属的中英文情感词典,具体如下:
- 中文情感词典:结合大连理工大学情感词汇本体库、知网 Hownet 中文程度级别词语以及否定词表,构建了全面的中文情感词典。情感词的初始情感强度分为五个档(1、3、5、7、9),情感极性分为中性(0)、褒义(1)、贬义(-1)和褒贬兼顾(3)。
- 英文情感词典:基于 SentiWordNet、知网 Hownet 英文程度级别词语以及否定词表构建。与中文情感词典类似,英文情感词典也对情感词的情感强度和极性进行了细致的标注。
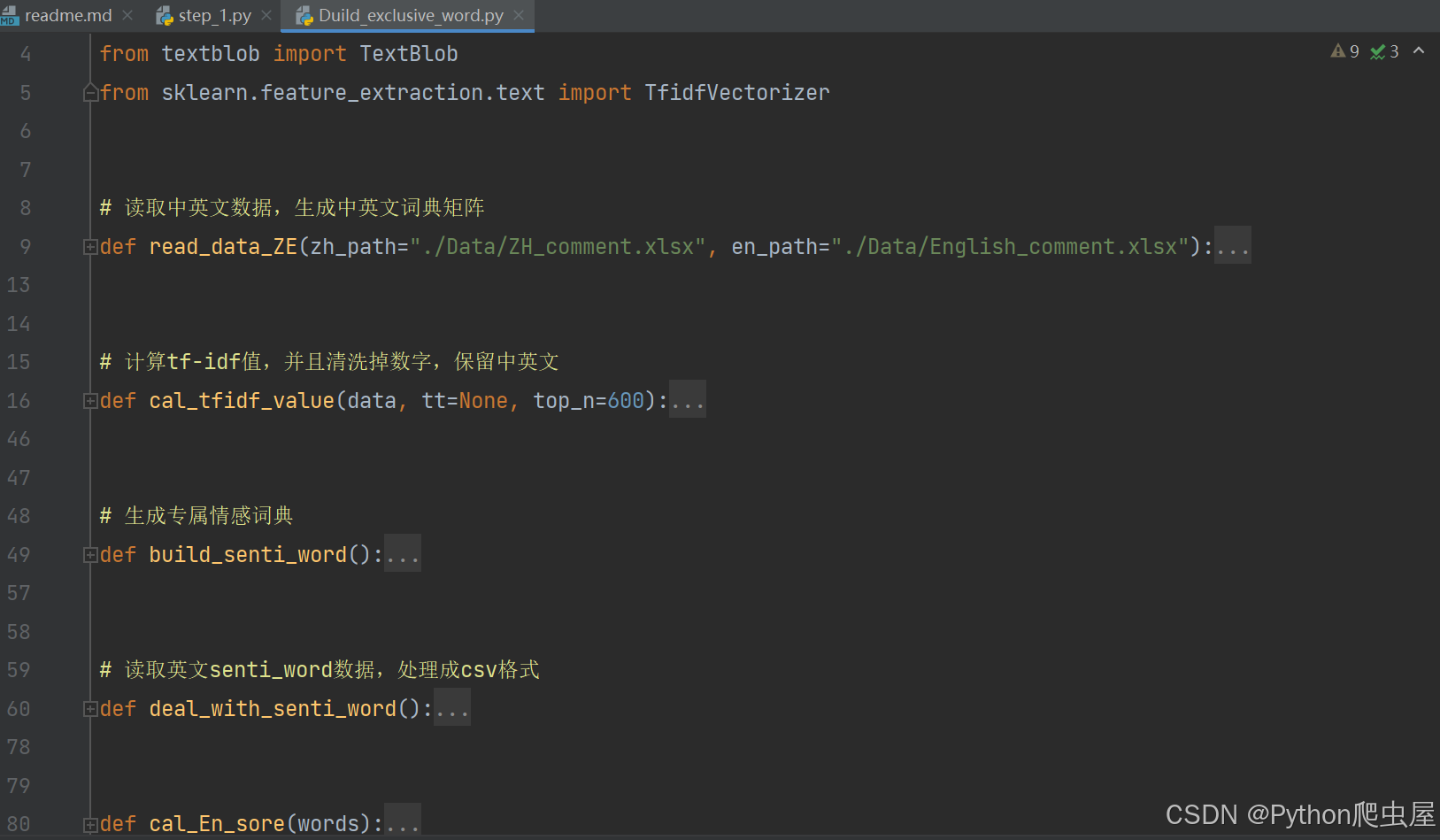
2. 情感词典权重计算
情感词典中的每个词都具有相应的权重,用于表示其情感强度。本项目对情感词典权重的计算规则如下:
- 否定词权重:所有否定词赋予“-1”的权重。根据否定词的数量计算权重值,奇数个否定词表示否定,偶数个否定词表示肯定。
- 程度副词权重:根据知网 Hownet 中的中英文程度副词,将其分为不同等级,并赋予相应的权重值。例如:
- “极其”、“非常”等词的权重为 2.00
- “超”、“过”等词的权重为 1.75
- “很”、“very”等词的权重为 1.50
- “较”、“more”等词的权重为 1.25
- “稍”、“a bit”等词的权重为 0.50
- “欠”、“just”等词的权重为 0.25
3. 情感值计算与文本分类
在情感分析过程中,需要根据情感词典中的词及其权重,计算文本的情感值。具体计算公式如下:
- 英文情感值计算公式:
l(w) = d(w) × a(w) × s(w) - 中文情感值计算公式:
l(w) = d(w) × a(w) × s(w) × m(w)
其中:
d(w)表示否定词权重a(w)表示情感词所在位置周围程度副词的加权总和s(w)表示情感词的情感得分m(w)表示程度副词与否定词处在不同位置时的权重值
通过上述公式计算每条评论的整体情感分值,并根据情感分值对文本进行正负向情感分类。部分代码如下: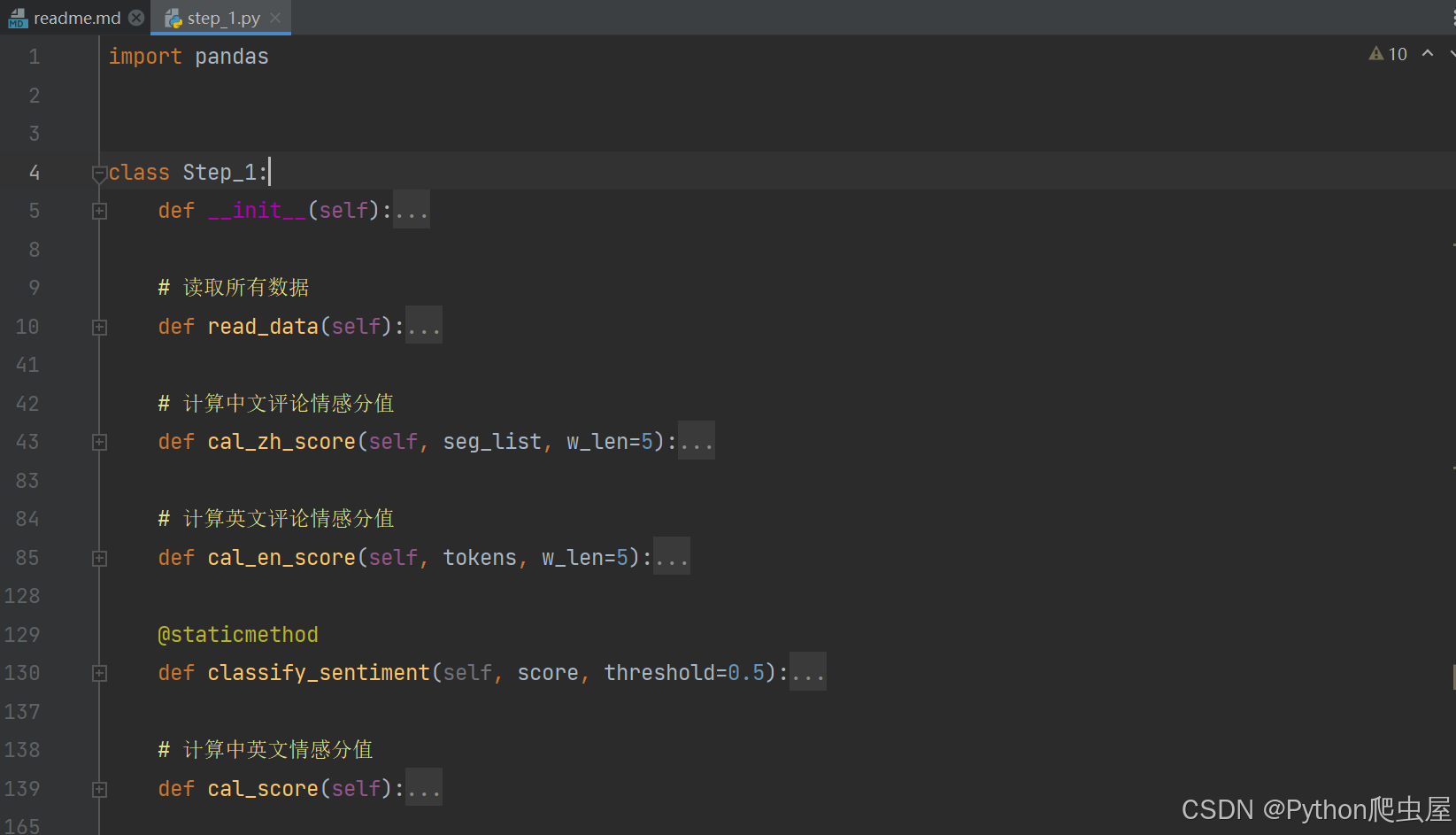
三、关键词提取:挖掘文本核心信息
关键词提取是文本挖掘中的重要环节,能够帮助我们快速了解文本的核心内容。本项目采用 TF-IDF 算法提取关键词,并结合情感分析结果,分别对中文正面、中文负面、英文正面和英文负面四组评论进行分析。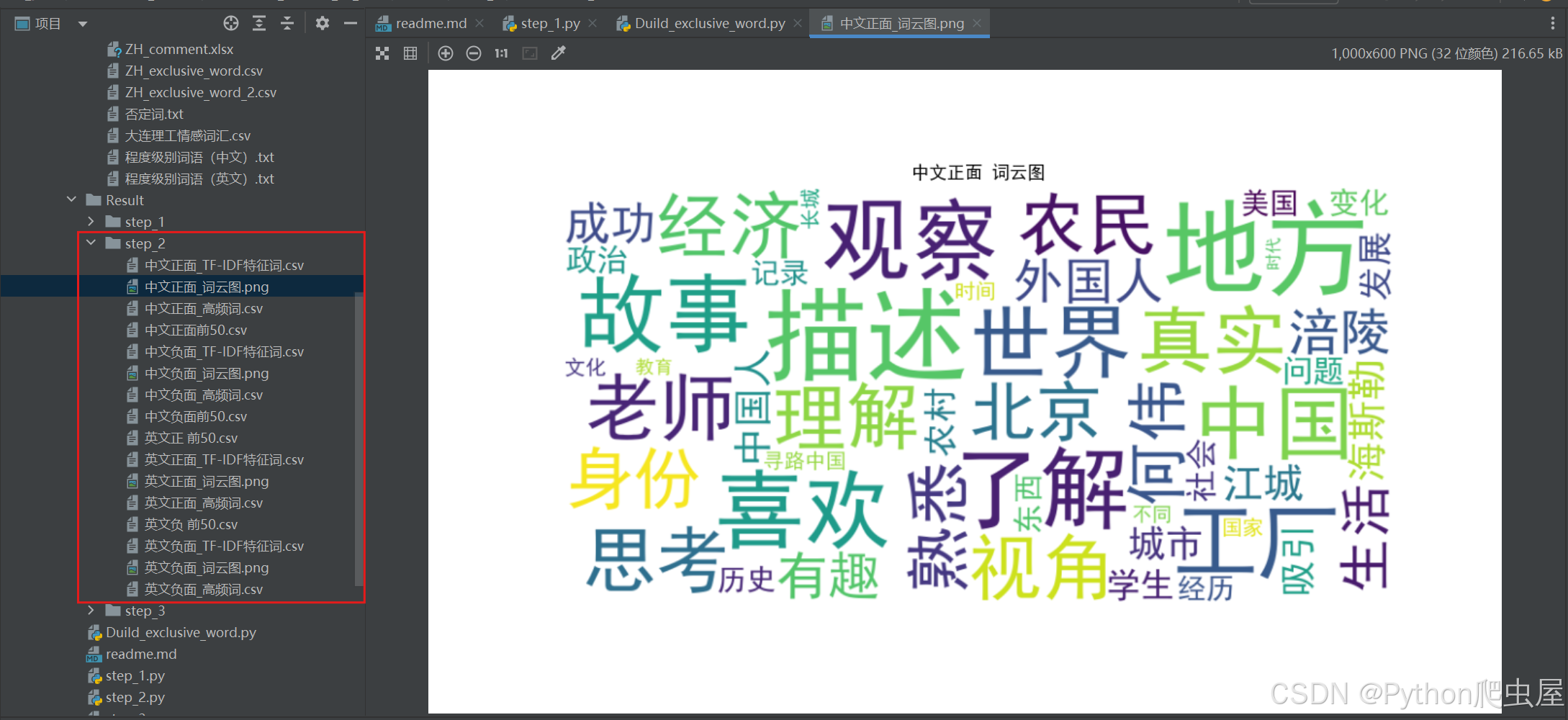
1. TF-IDF 算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法,用于评估一个词语对于一个文本集或一个语料库中的其中一份文本的重要性。本项目使用 TF-IDF 算法分别计算四组评论的特征关键词及其 TF-IDF 值。
2. 高频关键词提取与筛选
通过 TF-IDF 算法,分别提取四组评论中词频统计前 50 个词以及 TF-IDF 排名前 50 个特征词。然后,人工筛选高频词,并将高频词与 TF-IDF 词合并,构成高频关键词。
3. 关键词可视化
为了更直观地展示关键词的分布情况,本项目分别为四组评论绘制了关键词词云图。词云图能够清晰地展示关键词的频率和重要性,帮助我们快速了解文本的核心内容。
四、共现语义网络:探索关键词间的关联关系
共现语义网络是一种用于分析文本中关键词之间关联关系的方法。通过构建共现矩阵并进行可视化分析,可以深入了解关键词之间的语义联系。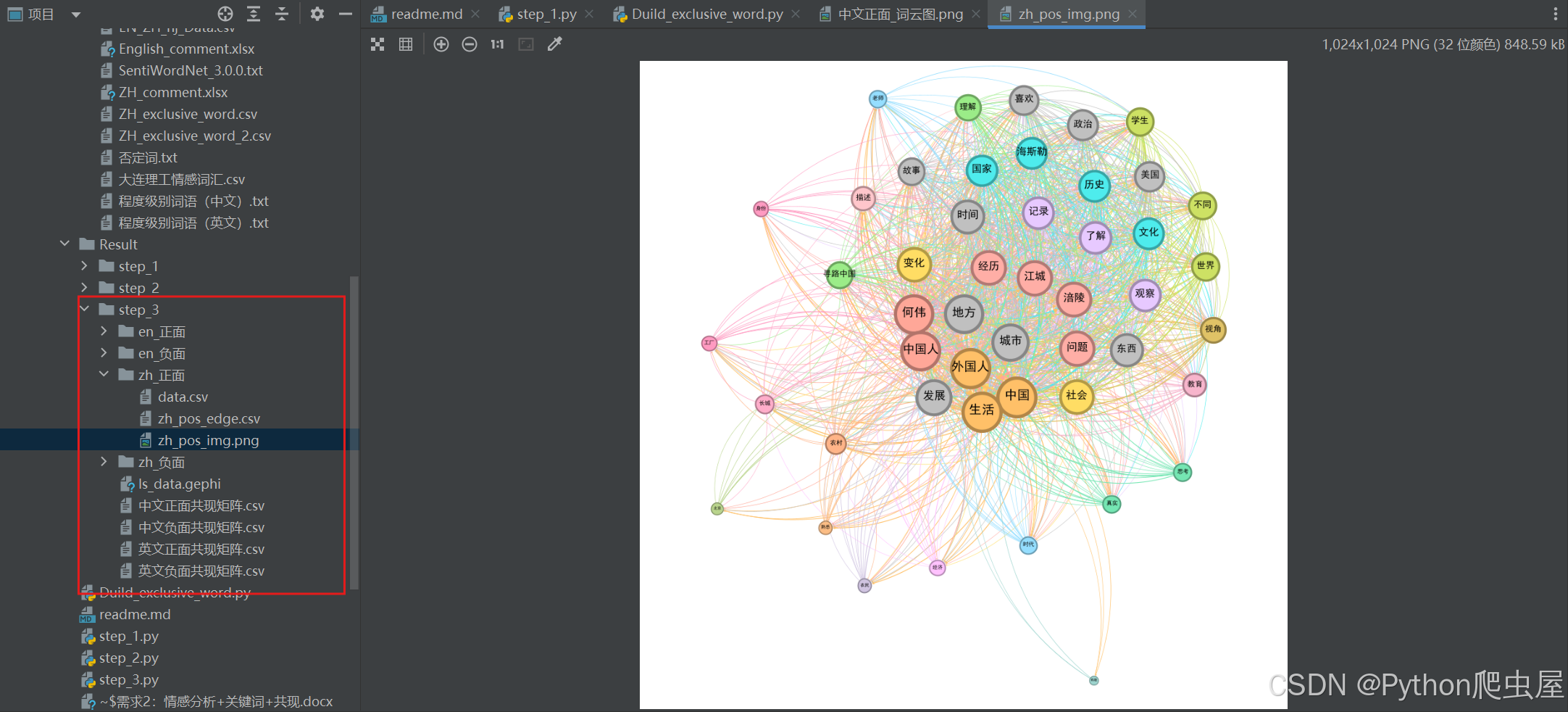
1. 共现矩阵构建
选择四组评论中的前 50 个高频关键词,再次遍历每组评论文本,分析文本以获取关键词对,并统计关键词对的共现频次。根据共现频次构建四组评论的共现矩阵。如果某一组评论数据量过少,可能导致共现矩阵稀疏,网络结构不稳定,此时可以适当降低过滤阈值。
2. 网络可视化与分析
将共现矩阵导入 Gephi 软件,使用 Fruchterman-Reingold 布局算法进行可视化分析。通过运行模块化算法,根据社区结果调整节点颜色,并优化布局。最后,导出以下参数指标:
- 整体参数:如网络的密度、直径、平均路径长度等。
- 关键节点的中心性度:如节点的度中心性、接近中心性、中介中心性等。
- 模块化(模块占比):分析网络的模块化结构,了解关键词之间的聚类情况。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)