大数据文件格式对比:Parquet 与ORC 对比
目前两者都作为Apache的顶级项目来进行维护,但是无论是设计的思路还是合理性都是ORCFile更为优秀.但是或许是因为背后所主导的力量不同,毕竟是出身名门,在各个存储系统的支持上,和实际的运用之中,Parquet还是占了很大的优势Apache ORCORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schem
目前两者都作为Apache的顶级项目来进行维护,但是无论是设计的思路还是合理性都是ORCFile更为优秀.
但是或许是因为背后所主导的力量不同,毕竟是出身名门,在各个存储系统的支持上,和实际的运用之中,Parquet还是占了很大的优势
1 大数据文件格式
1.1 Apache ORC
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
- 用于(在列中存储数据):用于数据存储是包含大量读取操作的优化分析工作负载
- 高压缩率(ZLIB)
- 支持Hive(datetime、小数和结构等复杂类型,列表,地图,和联盟)
- 元数据使用协议缓冲区存储,允许添加和删除字段
- HiveQL兼容
- 支持序列化
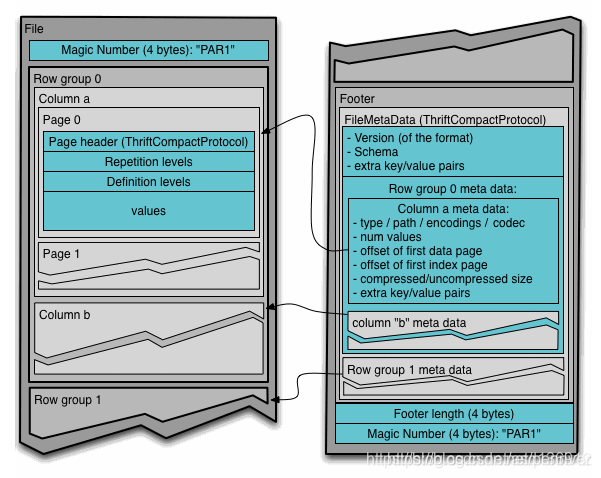
1.2 Apache Parquet
源自于google Dremel系统,Parquet相当于Google Dremel中的数据存储引擎,而Apache顶级开源项目Drill正是Dremel的开源实现。
Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等。
- 基于列(在列中存储数据):用于数据存储是包含大量读取操作的优化分析工作负载
- 与Snappy的压缩压缩率高(75%)
- 只需要列将获取/读(减少磁盘I / O)
- 可以使用Avro API和Avro读写模式
- 支持谓词下推(减少磁盘I / O的成本)
2 对比
2.1 相同点
- 基于Hadoop文件系统优化出的存储结构
- 提供高效的压缩
- 二进制存储格式
- 文件可分割,具有很强的伸缩性和并行处理能力
- 使用schema进行自我描述
- 属于线上格式,可以在Hadoop节点之间传递数据
2.2 不同点
| ORC FILE | Parquet | 备注 | |
|---|---|---|---|
| 存储格式 | 列式存储 | 列式存储 | 数据扫描时,只扫描涉及的列,不用扫描全部数据 |
| 支持的数据类型 | 支持复杂的数据类型 list map struct Union |
普通类型 对嵌套数据支持友好 |
嵌套数据能够单独读取列 |
| 兼容性 | hive presto | Impala、Drill、Spark、Arrow | orc与hive的兼容性更好 |
| 谓词下推 | 支持 | 支持 | 从物理上提前过滤掉一些不用的数据 |
| 压缩 | zlib | snappy | orc相比parquet的存储压缩率较高 |
| 事务 | 支持 | 不支持 | |
| 向量化Vectorized读取 | hive支持 | spark支持 |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)