特征选择-嵌入法、包装法 —— from 菜菜机器学习
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法类似,不同的是,包装法并不是自己输入某个评估指标或统计量的阈值。包装法在初始特征平台上训练评估器,并且通过coef_ 属性或feature_importances_属性获得每个特征的重要性。然后从当前的一组特征中修剪掉最不重要的特征,在修剪的集合上递归重复该过程,直到最终到达所需数量的要选择的特征。
1.Embedded嵌入法
1.1嵌入法简介
嵌入法是一种让算法自己决定使用那些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小排列选择权值系数大的特征,这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和随机森林中的feature_importances返回各个特征对树的建立的贡献,因此我们可以基于这种贡献的评估,找出对模型建立最有用的特征。相比于过滤法,嵌入法的结果会更加精确到模型的效用本身,对于提高模型效力有更好的结果。
过滤法中使用的统计量可以使用统计知识和常识来查找范围(如p值应当低于显著性水平0.05),而嵌入法中使用的权值系数却没有这样的范围可找。当大量特征都对模型有贡献且贡献不一时,我们就很难去界定一个有效的临界值。这种情况下,模型权值系数就是我们的超参数,根据学习曲线或模型本身的某些性质去判断这个超参数的最佳值。
1.2 feature_selection.SelectFromModel
sklearn.feature_selection.SelectFromModel(estimator,threshold=None,prefit=False,norm_order=1,max_features=None) 对于有feature_importances_的模型来说,若重要性低于提供的阈值参数,则认为这些特征不重要并被移除。feature_importances_的取值范围是[0,1],如果设置阈值很小,比如0.001,就可以删除那些对标签预测完全没有贡献的特征,如果设置得很接近1,可能只有一两个特征能够被留下。
| 参数 | 说明 |
|---|---|
| estimator | 使用的模型评估器,只要是带feature_importances_或者coef_属性,或带有l1和l2惩罚项的模型都可以使用 |
| threshold | 特征重要性的阈值,重要性低于这个阈值的特征都将被删除 |
| prefit | 默认False,判断是否将实例化后的模型直接传递给构造函数,如果为True,则必须直接调用fit和transform,不能使用fit_transform,并且使用SelectFromModel不能与cross_val_score,GridSearchCV和克隆估计器的类似实用程序一起使用。 |
| norm_order | k可输入非零整数,默认值为1,在评估期的coef_属性高于一维的情况下,用于过滤低于阈值的系统的向量的范数的阶数 |
| max_features | 在阈值设定下,要选择的最大特征数 |
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
import pandas as pd
data=pd.read_csv(r"F:\sklearn文档\digit recognizor.csv")
x=data.iloc[:,1:]
y=data.iloc[:,0]
x.shape #(42000, 784)
RFC_=RFC(n_estimators=10,random_state=0) #随机森林的实例化
x_embedded=SelectFromModel(RFC_,threshold=0.005).fit_transform(x,y)
x_embedded.shape #(42000, 47)
#画学习曲线来找最佳阈值
import numpy as np
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
threshold=np.linspace(0,(RFC_.fit(x,y).feature_importances_).max(),20) #linspace选取两者之间有限个数
# threshold
score=[]
for i in threshold:
x_embedded=SelectFromModel(RFC_,threshold=i).fit_transform(x,y)
once=cross_val_score(RFC_,x_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
print(score)
print(threshold)
------------------------------------代码分割线-----------------------------------------
score: [0.9373571428571429, 0.9391190476190475, 0.9363571428571429, 0.9322619047619047, 0.9274761904761905, 0.9215, 0.9178809523809524, 0.9004761904761904, 0.8911904761904761, 0.8540952380952381, 0.825952380952381, 0.732142857142857, 0.6951428571428572, 0.6951428571428572, 0.6667142857142858, 0.5254285714285715, 0.26502380952380955, 0.18942857142857142, 0.18942857142857142, 0.18942857142857142]
threshold: [0. 0.00067177 0.00134354 0.00201531 0.00268707 0.00335884
0.00403061 0.00470238 0.00537415 0.00604592 0.00671769 0.00738945
0.00806122 0.00873299 0.00940476 0.01007653 0.0107483 0.01142007
0.01209183 0.0127636 ]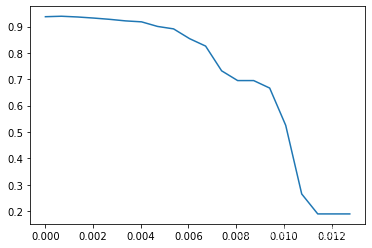
根据图像可得,随着阈值的增加,模型的效果降低,被删除的特征越来越多,信息损失越来越大。当阈值在0.0134之前,模型的效果可以维持在0.93以上,因此我们可以在[0,0.0134]之间挑选一个数值验证模型效果。
x_embedded=SelectFromModel(RFC_,threshold=0.00067).fit_transform(x,y)
x_embedded.shape #(42000, 324)
cross_val_score(RFC_,x_embedded,y,cv=5).mean()
-----------------------------代码分割线---------------------------------
0.9391190476190475可以看出,特征个数瞬间缩小到324,小于特征个数的一半,且模型效果达到0.939。在第一条学习曲线后选定一个范围 [0,0.0134],在[0,0.0134]使用细化的学习来找到最佳值:
score2=[]
for i in np.linspace(0,0.00134,20):
x_embedded=SelectFromModel(RFC_,threshold=i).fit_transform(x,y)
once=cross_val_score(RFC_,x_embedded,y,cv=5).mean()
score2.append(once)
plt.figure(figsize=[20,5])
plt.plot(np.linspace(0,0.00134,20),score2)
plt.xticks(np.linspace(0,0.00134,20))
plt.show()
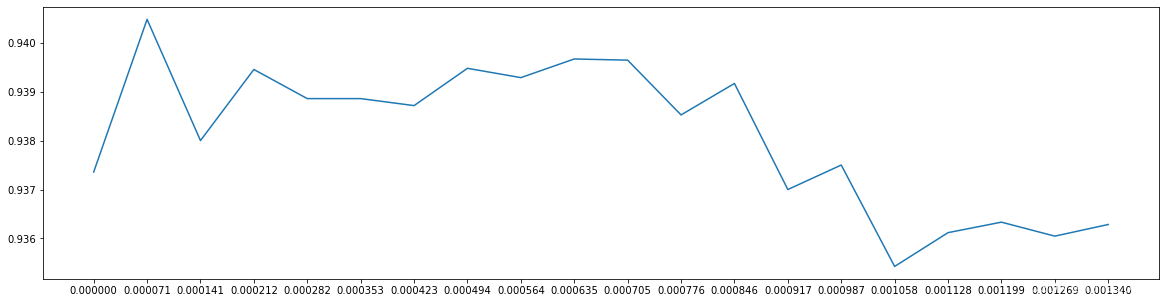
在0.00007左右,模型的效果超过0.94
x_embedded=SelectFromModel(RFC_,threshold=0.000060).fit_transform(x,y)
x_embedded.shape
cross_val_score(RFC_,x_embedded,y,cv=5).mean()
-----------------------------代码分割段------------------------------------
0.9412142857142858我们可能已经找到了现有模型下的最佳结果,再调整随机森林的参数
cross_val_score(RFC(n_estimators=100,random_state=0),x_embedded,y,cv=5).mean()
-------------------------------代码分割线--------------------------------
0.96497619047619042.Wrapper包装法
2.1 Wrapper简介
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法类似,不同的是,包装法并不是自己输入某个评估指标或统计量的阈值。包装法在初始特征平台上训练评估器,并且通过coef_ 属性或feature_importances_属性获得每个特征的重要性。然后从当前的一组特征中修剪掉最不重要的特征,在修剪的集合上递归重复该过程,直到最终到达所需数量的要选择的特征。
2.2 feature_selection.RFE
最典型的目标函数是递归特征消除法(Recursive feature elimination,简写为RFE)。它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。然后,它根据保留或剔除特征的顺序进行排名,最终选出一个最佳子集。包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。
sklearn.feature_selection.RFE(estimator,n_features_to_select=None,step=1,verbose=0)
参数estimator是需要填写的实例化后的评估器,n_features_to_select的特征个数,step表示每次迭代中希望移除的特征个数。除此之外,RFE类有两个很重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,.ranking_:返回特征的按数次迭代中综合重要性的排名。
#包装法
from sklearn.feature_selection import RFE
RFC_=RFC(n_estimators=10,random_state=0)
selector=RFE(RFC_,n_features_to_select=467,step=50).fit(x,y)
selector.support_
selector.ranking_
selector.support_.sum()
selector.ranking_
x_wrapper=selector.transform(x)
cross_val_score(RFC_,x_wrapper,y,cv=5).mean()
---------------------------代码分割线----------------------------
0.9390952380952381同样对包装法画学习曲线找到最佳的特征个数:
score3=[]
for i in range(1,751,50):
x_wrapper=RFE(RFC_,n_features_to_select=i,step=50).fit_transform(x,y)
once=cross_val_score(RFC_,x_wrapper,y,cv=5).mean()
score3.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score3)
plt.xticks(range(1,751,50))
plt.show()
明显看出,在包装法应用50个特征时,模型的表现就可以达到90%以上,比嵌入法、过滤法高效。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)