如何提高神经网络的泛化能力?
详细内容及解决办法请见:神经网络模型如何改进模型拟合?-CSDN博客在解决完上述问题之后,你再需要考虑如何提高模型的泛化能力。以下提高神经网络的方法与改进模型拟合的有明显的先后顺序不同,提高神经网络的泛化能力的方法是并行的,并没有前后关系,但是有使用效果的倾向。
0 前提条件
你在想要提高模型的泛化能力之前,你需要先保证:
- 模型能够正常开始训练,并且其性能要好于基线模型
- 模型在训练过程中性能随epoch的推进而改进
- 模型能够实现过拟合
详细内容及解决办法请见:
神经网络模型如何改进模型拟合?-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/145791879在解决完上述问题之后,你再需要考虑如何提高模型的泛化能力。以下提高神经网络的方法与改进模型拟合的有明显的先后顺序不同,提高神经网络的泛化能力的方法是并行的,并没有前后关系,但是有使用效果的倾向。
https://blog.csdn.net/weixin_65259109/article/details/145791879在解决完上述问题之后,你再需要考虑如何提高模型的泛化能力。以下提高神经网络的方法与改进模型拟合的有明显的先后顺序不同,提高神经网络的泛化能力的方法是并行的,并没有前后关系,但是有使用效果的倾向。
1 数据收集——数据集管理
在收集数据上花费更多精力和金钱,几乎总是比在开发更好的模型上花费同样的精力和金钱产生更大的投资回报。
你一般需要进行如下的检查和操作:
- 确保拥有足够的数据。这个数据量不是绝对的,适合的才是最好的。每个问题的数据的流形都不一样,能够具有较为完全的信息从而能够描述精确的数据流形所需要的数据量也是不同的。你的评价标准应该是能够实现模型密集采样的数据量就是好的数据量。
- 需要深入了解数据集的分布情况。你需要进行数据透视从而得到对特征和标签的认识,并且对其进行一定的处理。你可以参考以下博客来了解数据透视的有关操作:
机器学习中如何对数据集进行数据透视和预处理?-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/145806790
https://blog.csdn.net/weixin_65259109/article/details/145806790
2 数据增强——特征工程
提高数据泛化潜力的一个特别重要的方法就是特征工程。对于大多数机器学习问题,特征工程是成功的关键因素。
特征工程是指将数据输入模型之前,利用自己关于数据和机器学习算法的只是对数据进行硬编码的变换(这种变换不是模型学到的),以改善算法的效果。
特征工程的本质是用更简单的方式表述问题,从而使问题更容易解决。特征工程可以让潜在流形变得更平滑、更简单、更有条理。
特征工程通常需要深入理解问题。
对于神经网络而言,你可能会有下面的问题:既然神经网络能学习到数据的潜在流形,特征工程的意义何在?原因在于构建良好的特征工程,能够使得模型运用更小的数据、更少的资源解决问题。你可以参考如下文章了解特征工程:
什么是特征工程?如何进行特征工程?-CSDN博客![]() https://blog.csdn.net/qq_39521554/article/details/78877505这篇文章介绍了在数据数据进行透视和预处理之后,如何选择最适合的模型的特征?在确定好输入特征之后,如何进行降维从而使得模型训练更加节约成本?
https://blog.csdn.net/qq_39521554/article/details/78877505这篇文章介绍了在数据数据进行透视和预处理之后,如何选择最适合的模型的特征?在确定好输入特征之后,如何进行降维从而使得模型训练更加节约成本?
3 节省训练资源——提前终止
神经网络在训练时,总是从欠拟合到稳健拟合再到过拟合。但是,从目的上讲,我们只需要稳健拟合中间的那个最优的模型,找到这个最优的模型后你再进行训练就多余了。
其核心是EarlyStopping函数,其核心思想就是在模型训练时,你检测某个指标,如果这个指标在多少个训练次数中没有改善,训练将会停止。最后将这个参数添加到fit过程中的callback参数中:
# 早停回调函数
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)我们使用boston_housing举个完整的例子:
from tensorflow.keras.datasets import boston_housing
(train_data,train_targets),(test_data,test_targets) = boston_housing.load_data()#回归问题目标值记为target,分类问题记为label
#数据标准化,包括训练集和测试集,不包括标签(预测值)
#先计算均值和方差
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
#对训练集、测试集进行标准化,减去均值除以标准差
train_data -= mean
train_data /= std
test_data -= mean
test_data /= std
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.callbacks import EarlyStopping
# 早停回调函数
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
model = keras.Sequential([
layers.Dense(64,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(1)
])
model.compile(
optimizer="rmsprop",
loss="mse",
metrics=['mae']
)
history=model.fit(
train_data,train_targets,
epochs=50,
batch_size=16,
callbacks=early_stopping,
validation_split=0.2
)
import matplotlib.pyplot as plt
x=range(1,32)
y=history.history['val_loss']
plt.plot(
x,y,
'b-',
label='val_loss with EarlyStopping'
)
plt.xlabel('epochs')
plt.ylabel('val_loss')
plt.legend()
plt.show()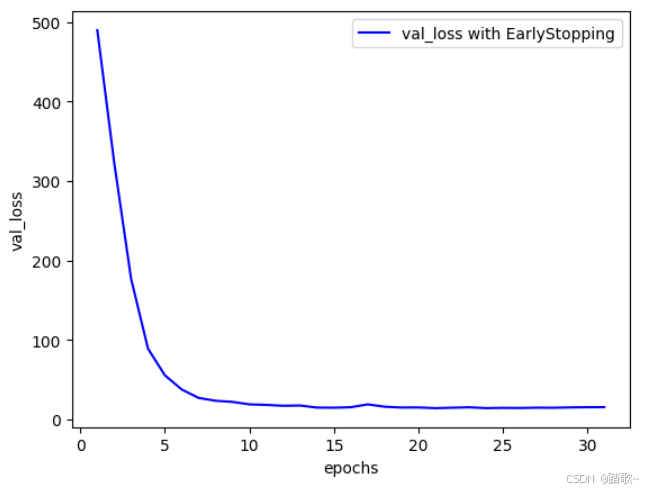
4 简化模型——模型正则化
模型正则化可以使模型变得更简单、更规则,曲线更平滑,更通用。从而用一个简单的模型来解决实际问题。
4.1 控制模型架构
模型架构主要指的是模型的层的大小和数量。
模型的容量过大可以实现拟合,但是会出现指标方差不稳定的情况。模型的容量过小,可能无法实现拟合。你需要在容量过大和容量不足之间找到一个平衡点。
目前没有一个具体的理论告诉我们对于什么样的问题我们应该架构什么样容量的模型。我们一般的做法是开始选择相对较小的层和参数,然后逐渐增加层的大小或者添加新层,直到这种增加对验证指标的影响很小。
以下通过IMDB数据集进行举例,对比模型架构大小之间的区别。
你需要先知道的是如何让模型拟合。让模型拟合之后才能进行过拟合的优化。简单来说,如果模型没有办法进行训练,说明是模型的配置问题,一般更改optimizer或者batchsize即可;如果模型在验证集上的指标得不到优化或者性能不如随机器,可能需要修改模型的架构从而适应该具体问题;如果模型不能实现过拟合,那么你需要扩大模型容量。详细请见:
神经网络模型如何改进模型拟合?-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/145791879
https://blog.csdn.net/weixin_65259109/article/details/145791879
4.1.1数据准备
from tensorflow.keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=1000)
import numpy as np
def vectorize_sequences(sequences,dimension=10000):#我的词表的长度是10000
results = np.zeros(shape=(len(sequences),dimension))#这里生成的是张量,形状是(sequences,dimension),dimension是一个dimension列的一维列表
for i, sequence in enumerate(sequences):#enumerate函数将传入的sequences前面再加上了一个传入序号形成了一个对应的元组:(i,sequence),i代表句子序号,sequence代表这个句子的词列表
for j in sequence:#对于每个词的索引位置,将results的每一行的对应位置的词的的0变为1
results[i,j] = 1#i代表样本序号,j代表词索引位置
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#标签也应该进行向量化,这段代码的目的是将训练标签(train_labels)转换为NumPy数组,并将其数据类型转换为float32
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
4.1.2 模型配置
4.1.2.1 小模型
from tensorflow import keras
from tensorflow.keras import layers
def get_model():
model=keras.Sequential([
layers.Dense(5,activation='relu'),
layers.Dense(5,activation='relu'),
layers.Dense(1,activation='sigmoid'),
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
model_small=get_model()
history_small=model_small.fit(
x_train,y_train,
epochs=50,
batch_size=500,
validation_split=0.4
)4.1.2.2 中等模型
def get_model():
model=keras.Sequential([
layers.Dense(16,activation='relu'),
layers.Dense(16,activation='relu'),
layers.Dense(1,activation='sigmoid'),
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
model_large=get_model()
history_large=model_large.fit(
x_train,y_train,
epochs=50,
batch_size=500,
validation_split=0.4
)4.1.2.3 大模型
def get_model():
model=keras.Sequential([
layers.Dense(512,activation='relu'),
layers.Dense(512,activation='relu'),
layers.Dense(1,activation='sigmoid'),
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
model_largest=get_model()
history_largest=model_largest.fit(
x_train,y_train,
epochs=50,
batch_size=500,
validation_split=0.4
)你可以看到我增大模型容量只是通过控制每一层的大小实现,实际上你也可以通过控制层数来实现。
4.1.3 可视化
4.1.3.1 三个模型比较
x=range(1,50+1)
y_largest=history_largest.history['val_loss']
plt.plot(x,y_large,
'r-',
label='model_large'
)
plt.plot(x,y,
'b-',
label='model_small'
)
plt.plot(x,y_largest,
'g-',
label='model_lagest'
)
plt.xlabel('epochs')
plt.ylabel('val_loss')
plt.title('val_loss of Large VS Small VS Largest')
plt.legend()
plt.show()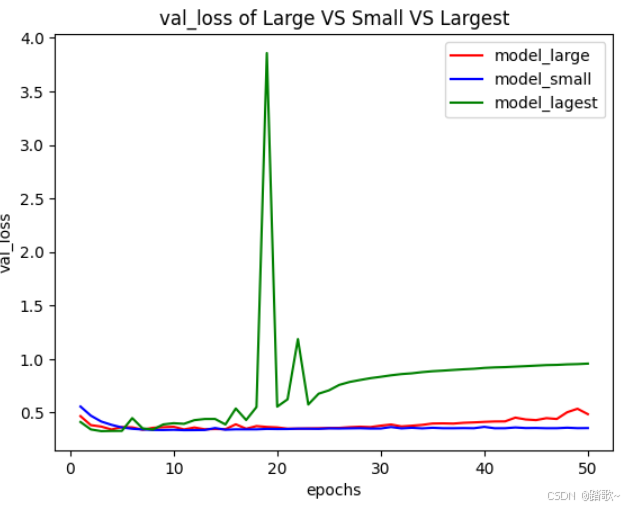
可以看到最大的模型出现较大的方差!如果模型的记忆容量过大,那么其会立刻开始过拟合(训练集上),并且其验证损失曲线看起来很不稳定、方差很大!其在验证集上可能会经过一两轮验证损失就会降得很低。
当然,如果你遇到验证集上的方差很大,那么你可以通过进行如下操作来优化验证集的指标:
- 将模型的容量调小
- 将验证过程变得可靠,比如扩大验证集
4.1.3.2 较小的两个模型比较
x=range(1,50+1)
y_large=history_large.history['val_loss']
plt.plot(x,y_large,
'r-',
label='model_large'
)
plt.plot(x,y,
'b-',
label='model_small'
)
plt.xlabel('epochs')
plt.ylabel('val_loss')
plt.title('val_loss of Large VS Small')
plt.legend()
plt.show()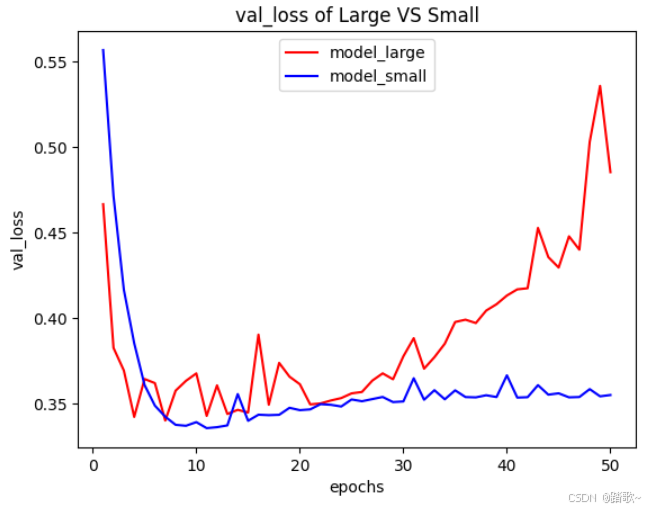
可以看到中等模型的过拟合程度要比小模型要显著,小模型的过拟合的方差要比中等模型要好。
4.1.4 建议
你需要先保证模型能够正常训练,然后你要保证模型在验证集上的指标能够得到优化,接着你要保证模型能够过拟合,最后你才去考虑模型提高泛化能力。
4.2 添加权重正则化
简单的模型比复杂的模型更不容易过拟合!那么,如何才能让模型在训练的过程中朝着更简单的方向进行训练呢?
一个很简单的道理,如果你想让一只小狗认识到乱爬桌子是不对的,你可以在它爬上桌子的每一次都给它一巴掌,这样在小狗一次次趴桌的实验中,小狗就会意识到这样是不对的。简单来说,你要让模型知道把模型变得复杂会受到惩罚。
神经网络在训练时以loss的降低作为目的,那么你只需要让模型在变得复杂的时候增加loss就可以让模型认识到这样子做是代价很大的。
这种方法叫做权重正则化,实现方法是向模型损失函数中添加与权重值相关的成本,这种成本有两种形式:
- L1正则化:添加的成本与权重系数的绝对值成正比。计算过程是原有计算损失值+L1正则化系数*权重协方差矩阵的绝对值
- L2正则化:添加的成本与权重系数的平方成正比。原有计算损失值+L1正则化系数*权重协方差矩阵的平方
你可以理解为在计算损失时,对张量中的具体数字添加了一个权重的计算。
但是!这种方法只适用于小模型!因为大模型一般是过度参数化的,在训练计算损失时添加正则化项对损失的大小几乎产生不了什么影响!
此外,你还需要认识到,因为改变了计算损失的方式,在训练时Loss要比没有天机模型正则化的模型Loss要大。并且,模型更难实现明显的过拟合!
从实现的角度讲,你需要在构建model时在每一层中传入权重正则化项实例(注意,单独的添加L1或者L2正则化项是可行的,你也可以同时做L1正则化和L2正则化)。以下是代码展示,仍然使用IMDB作为数据集:
4.2.1 数据准备
from tensorflow.keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=1000)
import numpy as np
def vectorize_sequences(sequences,dimension=10000):#我的词表的长度是10000
results = np.zeros(shape=(len(sequences),dimension))#这里生成的是张量,形状是(sequences,dimension),dimension是一个dimension列的一维列表
for i, sequence in enumerate(sequences):#enumerate函数将传入的sequences前面再加上了一个传入序号形成了一个对应的元组:(i,sequence),i代表句子序号,sequence代表这个句子的词列表
for j in sequence:#对于每个词的索引位置,将results的每一行的对应位置的词的的0变为1
results[i,j] = 1#i代表样本序号,j代表词索引位置
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#标签也应该进行向量化,这段代码的目的是将训练标签(train_labels)转换为NumPy数组,并将其数据类型转换为float32
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')4.2.2 模型配置
4.2.2.1 基线模型
model=keras.Sequential([
layers.Dense(16,activation='relu'),
layers.Dense(16,activation='relu'),
layers.Dense(1,activation='sigmoid'),
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
history_oringin=model.fit(
x_train,y_train,
epochs=50,
batch_size=512,
validation_split=0.4
)4.2.2.2 带有正则化的模型
from tensorflow.keras import regularizers
model=keras.Sequential([
layers.Dense(16,kernel_regularizer=regularizers.l2(0.002),activation='relu'),
layers.Dense(16,kernel_regularizer=regularizers.l2(0.002),activation='relu'),
layers.Dense(1,activation='sigmoid')
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
history_regularizer=model.fit(
x_train,y_train,
epochs=50,
batch_size=512,
validation_split=0.4
)4.2.3 可视化
4.2.3.1 训练过程对比
import matplotlib.pyplot as plt
x=range(1,50+1)
y_oringin=history_oringin.history['loss']
y_regularizer=history_regularizer.history['loss']
plt.plot(x,y_oringin,
'r-',
label='model_oringin'
)
plt.plot(x,y_regularizer,
'b-',
label='model_regularizer'
)
plt.xlabel('epochs')
plt.ylabel('loss')
plt.title('loss of oringin VS regularizer')
plt.legend()
plt.show()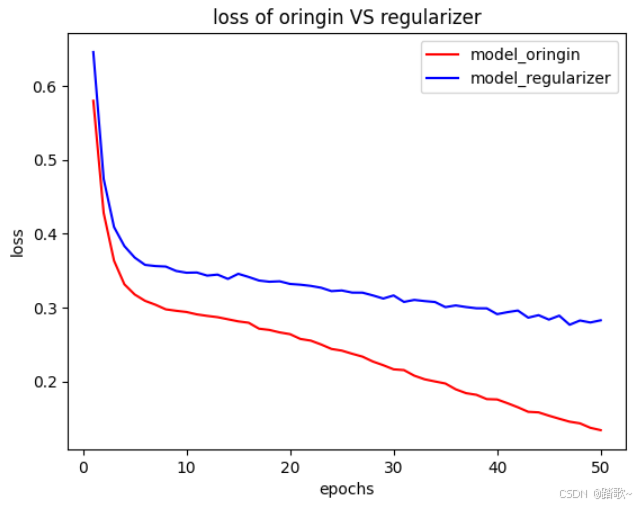
可以看到,添加了正则化项的模型在训练过程中loss值明显偏高。
4.2.3.2 验证分数对比
import matplotlib.pyplot as plt
x=range(1,50+1)
y_oringin=history_oringin.history['val_loss']
y_regularizer=history_regularizer.history['val_loss']
plt.plot(x,y_oringin,
'r-',
label='model_oringin'
)
plt.plot(x,y_regularizer,
'b-',
label='model_regularizer'
)
plt.xlabel('epochs')
plt.ylabel('val_loss')
plt.title('val_loss of oringin VS regularizer')
plt.legend()
plt.show()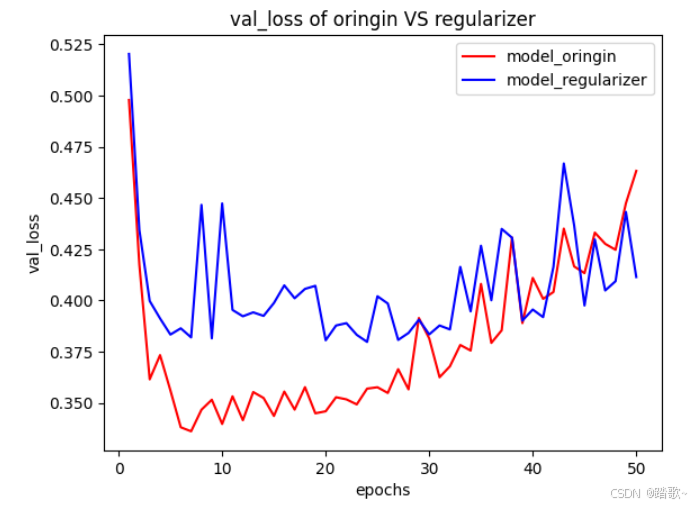
可以看到带有正则化项的模型更不容易出现过拟合,并且其分数的方差要大一些。
4.3 使用dropout
4.3.1 缘起
dropout是神经网络中最常用、最有效的正则化方法之一!它有多伦多大学的Geoffrey Hinton和他的学生开发。他的灵感是银行的防欺诈机制。银行在大多业务条线中不停的换人,其原因是可以阻止银行人员之间的合作而产生的欺诈。运用到神经网络中,其可以通过对层中的任意位置的向量置为0来打断矩阵中不同位置的数值之间的合作关系。其核心思想是在层的输出值中引入噪声,打破不重要的偶然模式。如果没有噪声,那么神经网络讲记住这些偶然模型。
4.3.2 内部原理
请注意dropout比例只在训练时起作用,测试时没有单元被舍弃。dropout比率是指被设为0的特征所占的比例,其通常介于0.2-0.5之间。由于你在层输出时将dropout比率的元素设为0,而将这个矩阵流向下一层时需要再将没有变换的输出值单招dropout的比率缩小,从而使得整体矩阵按照基本一致的数据进行操作,以便下一层能够正常进行激活。
调用时,只需要在某一层的后面添加:
layers.Dropout(0.5)4.3.3 实现
4.3.3.1 数据准备
from tensorflow.keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=1000)
import numpy as np
def vectorize_sequences(sequences,dimension=10000):#我的词表的长度是10000
results = np.zeros(shape=(len(sequences),dimension))#这里生成的是张量,形状是(sequences,dimension),dimension是一个dimension列的一维列表
for i, sequence in enumerate(sequences):#enumerate函数将传入的sequences前面再加上了一个传入序号形成了一个对应的元组:(i,sequence),i代表句子序号,sequence代表这个句子的词列表
for j in sequence:#对于每个词的索引位置,将results的每一行的对应位置的词的的0变为1
results[i,j] = 1#i代表样本序号,j代表词索引位置
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#标签也应该进行向量化,这段代码的目的是将训练标签(train_labels)转换为NumPy数组,并将其数据类型转换为float32
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')4.3.3.2 模型配置
基线模型:
model=keras.Sequential([
layers.Dense(16,activation='relu'),
layers.Dense(16,activation='relu'),
layers.Dense(1,activation='sigmoid'),
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
history_oringin=model.fit(
x_train,y_train,
epochs=50,
batch_size=512,
validation_split=0.4
)带有dropout的模型:
model=keras.Sequential([
layers.Dense(16,activation='relu'),
layers.Dropout(0.5),
layers.Dense(16,activation='relu'),
layers.Dropout(0.5),
layers.Dense(1,activation='sigmoid')
])
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
history_dropout=model.fit(
x_train,y_train,
epochs=50,
batch_size=512,
validation_split=0.4
)4.3.3.3 可视化
import matplotlib.pyplot as plt
x=range(1,50+1)
y_oringin=history_oringin.history['val_loss']
y_dropout=history_dropout.history['val_loss']
plt.plot(x,y_oringin,
'r-',
label='model_oringin'
)
plt.plot(x,y_dropout,
'b-',
label='model_dropout'
)
plt.xlabel('epochs')
plt.ylabel('val_loss')
plt.title('val_loss of oringin VS dropout')
plt.legend()
plt.show()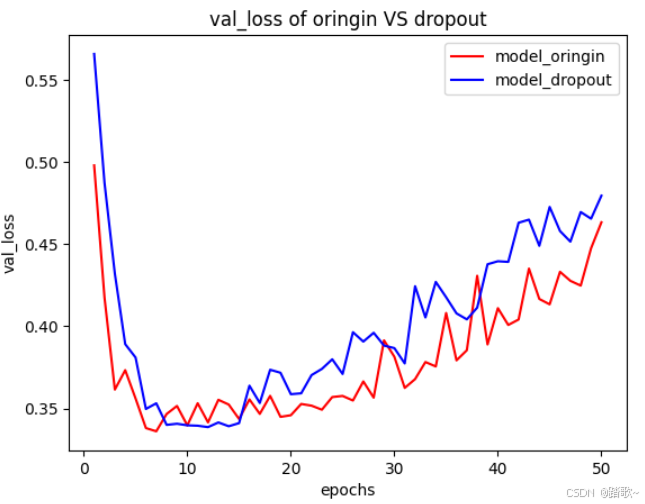
可以看到带有dropout的模型更容易实现明显的过拟合,并且稳健拟合的区间比较明显。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)