神经网络代码注意点
用python写AI代码需要注意的坑
总结
- 文章来源:CSDN_LawsonAbs
- LawsonAbs的认知与思考,望各位读者审慎阅读。
- 持续更新~
本文详细介绍在写神经网络+模型训练代码时会遇到的一些问题,零散总结。
1.注意细节
注意细节,一定要注意细节,代码是一个逻辑性极强的活儿,只有当每行代码逻辑都成立时,才能生效,否则就是报错,而且一定要从报错信息中找出些什么!
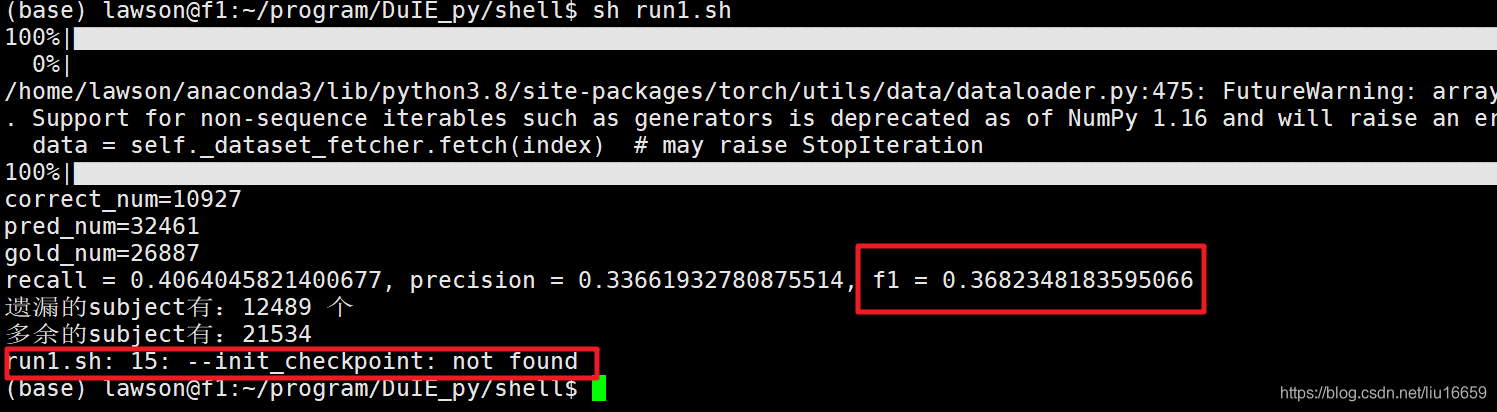
我在使用某个训练好的模型进行预测时,发现f1值特别的差,但代码都是完好的啊,怎么就有问题呢?后来经过查找才知道原来是shell脚本中的加载模型的那行参数没有生效,如下图所示: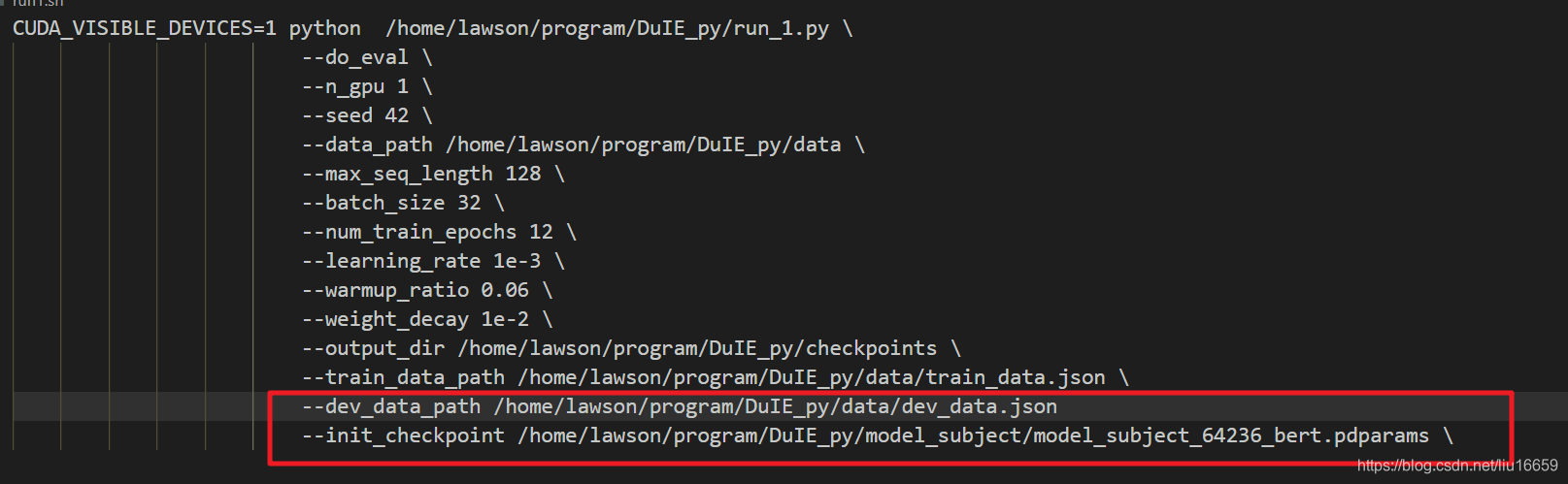
就导致预测效果极差。
其实这个问题也在上面的日志中体现出来了: run1.sh: 15: --init_chechpoint: not found,但是我却鲁莽地直接忽视了这个报错,却去查找代码的问题,简直可笑!
2 类设计
训练集,验证集,测试集三者的任务都是不同的,你是否想好它们的数据集是否共用同一个Dataset?还是为不同的数据集提供一个实现?
2.1 训练集
- 需要label,用于计算损失
2.2 验证集
- 需要label,可视化最后的损失情况
- 如果是一个NER问题,则需要原文本信息,因为需要可视化最后抽取出来的具体是什么数据。
…
2.3 测试集
- 没有label
- 如果是一个NER问题,那么仍然需要原文本信息
经过上面这些分析,就可以知道这些数据集包含的数据项是不完全相同的。
3 方法设计
-
是将一个方法设计的复杂,还是共用同一个方法?
这也是需要回答的问题 -
不要在模型中计算loss,而应该在train()函数中计算loss。但无论如何,请确保在evaluate的时候,模型的logtis是可以被传递回来的。
-
通常在验证模型时,也需要打出loss 和 f1 值,因为你需要查看验证集loss的情况,f1值那是更自然的需求了。
-
最好把参数全写成配置参数,这样launch.json 和shell 脚本就不会因为参数而冲突了
-
参数调整后,要跑整个模型时,请用shell脚本运行,而不是在vscode中用调试窗口跑。因为这样无法方便你对其它的代码调试,从而耽误进度。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)