大数据Hadoop之——部署hadoop+hive+Mysql环境(Linux)
目录
前期准备
查看网卡:
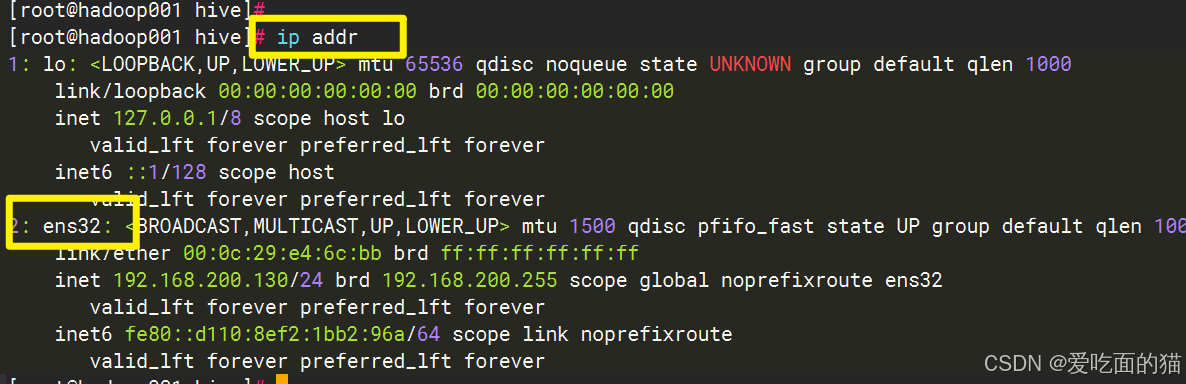
配置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-ens32 ---- 根据自己网卡设置。

设置主机名
hostnamectl --static set-hostname 主机名
例如:
hostnamectl --static set-hostname hadoop001
配置IP与主机名映射
vi /etc/hosts

关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置免密登录
一、JDK的安装
1、安装jdk
在/opt/model中上传jdk包并解压
tar -zxvf jdk-8u151-linux-x64.tar.gz
重命名,方便配置环境变量,避免更换jdk版本修改配置文件

2、配置Java环境变量
|
系统级(全局) |
|
对所有用户生效 |
|
用户级(个人) |
|
只对当前用户生效 |
|
|
✅ 几乎所有 Linux/Unix 系统都有 |
Ubuntu、CentOS、macOS 等 |
|
|
✅ CentOS/RHEL 系统使用 |
CentOS、RHEL、Fedora |
|
|
✅ Ubuntu 使用 |
Ubuntu、Debian |
|
|
✅ 用户可创建 |
所有支持 Bash 的系统 |
|
|
✅ Ubuntu 默认生成 |
Ubuntu、Debian |
|
|
✅ 用户级 shell 配置 |
所有支持 Bash 的系统 |
vi /etc/profile
export JAVA_HOME=/opt/module/java #此处是自己实际的Java安装路径
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3、加载环境变量
source /etc/profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
4、进行校验

二、hadoop的环境搭建
1、hadoop的下载安装
1.1. 下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/
下载 hadoop-3.2.2.tar.gz 安装包1.2 上传
使用xshell上传到指定安装路径此处是安装路径是 /opt/module
1.3 解压重命名
tar -xzvf hadoop-3.2.2.tar.gz
mv hadoop-3.2.2 hadoop
1.4 配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/module/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.5 加载环境变量
source /etc/profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
1.6检验安装
hadoop version
出现下图说明安装成功
2、配置文件设置
2.1. 配置 hadoop-env.sh
hadoop伪分布式配置
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/opt/module/java
2.2. 配置 core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 默认 9000端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
<description>配置NameNode的URL</description>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>配置hive内容(下面要安装hive,因此需要增加下面内容,否则不添加)
<!-- 配置允许哪些主机上的程序可以以root身份发起代理请求 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property><!-- 配置允许哪些组的用户可以以root身份发起代理请求 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property><!-- 配置允许哪些具体用户可以以root身份发起代理请求-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
2.3. 配置 hdfs-site.xml
<configuration>
<!-- 数据的副本数量 如果是完全分布式的集群模式,则改为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/data/datanode</value>
</property>
<!--设置权限为false-->
<property>
<name>dfs.permissions.enabled </name>
<value>false</value>
</property>
<!-- hdfs的web管理页面的端口 -->
<property>
<name>dfs.http.address</name>
<value>hadoop001:9870</value>
</property>
<!-- 设置secondname的端口,如果是完全分布式的集群模式,则改为hadoop003 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop001:6002</value>
</property>
</configuration>
2.4. 配置 yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<!-- NodeManager 上运行的辅助服务(auxiliary services),用于支持 MapReduce 的 shuffle 阶段 -->
<!-- 必须启用才能让 YARN 支持 MapReduce 的 shuffle 功能 -->
<!-- 如果你使用的是 Spark 或其他框架,可能不需要这个配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<!-- NodeManager 和 ApplicationMaster 会通过该主机名连接到 ResourceManager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
<!-- 环境变量的继承 -->
<!-- 允许传递给容器的环境变量白名单 -->
<!-- 设置哪些环境变量可以从 NodeManager 传递给启动的应用程序容器(Container) -->
<!-- 默认情况下,YARN 容器不会继承所有的系统环境变量 -->
<!-- 为了保证任务能正常运行,需要将必要的环境变量加入白名单 -->
<!-- 常见如 JAVA_HOME、Hadoop 相关路径等,都是应用程序运行所必需的 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<!--如果应用请求的内存小于这个值,YARN 会自动将其提升为这个最小值 -->
<!--示例:如果某个任务只申请 100 MB,但设置了最小为 512,则实际分配 512 MB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!--如果应用请求的内存超过这个值,YARN 会拒绝该请求 -->
<!--这个值不能超过 NodeManager 的总内存容量-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<!-- 指定当前 NodeManager 节点可提供给容器使用的最大物理内存总量(单位:MB)-->
<!-- 这个值决定了该节点最多能运行多少个容器,取决于每个容器的内存需求。-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<!-- 是否启用对容器使用的物理内存 进行检查 -->
<!-- 设为 true,YARN 会在容器超出其申请的物理内存时终止它 -->
<!-- 防止某些任务占用过多内存导致整个节点崩溃。 -->
<!-- 推荐生产环境中保持为 true。 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<!-- 是否开启虚拟内存检查 -->
<!-- 若设为 true,YARN 会检查虚拟内存使用情况并可能杀掉超限任务 -->
<!-- 有时虚拟内存使用较高是正常的(例如 JVM),所以部分场景下建议关闭此功能 设为Flase -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
2.5. 配置 mapred-site.xml
<configuration>
<!-- mr程序默认运行方式。yarn集群模式 local本地模式--><!-- 设置 MapReduce 应用程序的执行框架为 YARN 即 MR运行的资源调度模式--->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property><!-- 以下可以不用配置,作为了解内容
当 YARN 启动 MapReduce (ApplicationMaster、MapTask、ReduceTask)进程提供一致的环境变量,确保找到 MapReduce 的依赖库和资源路径。-->
<!-- MR App Master环境变量。用于告诉 ApplicationMaster 去哪里找 MapReduce 相关的 JAR 包或脚本-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 为每个 MR 的 MapTask 设置环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 为每个 MR 的 ReduceTask 设置环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
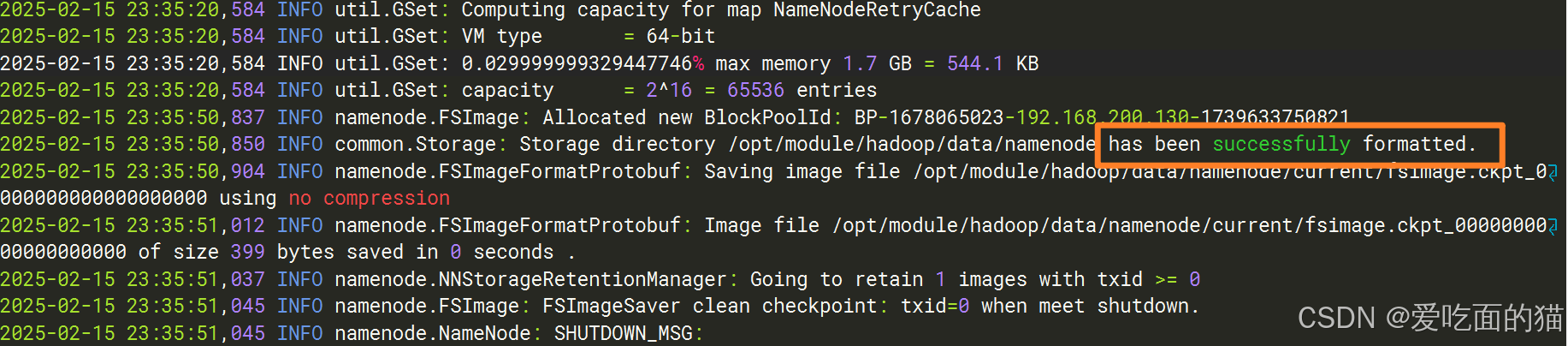
3、Hdfs格式化
cd /opt/module/hadoop/
bin/hdfs namenode -format
下图表示初始化成功
4、启动hdfs
启动hdfs分布式文件系统
cd /opt/module//hadoop/sbin
>> start-dfs.sh
使用 jps 查看启动进程

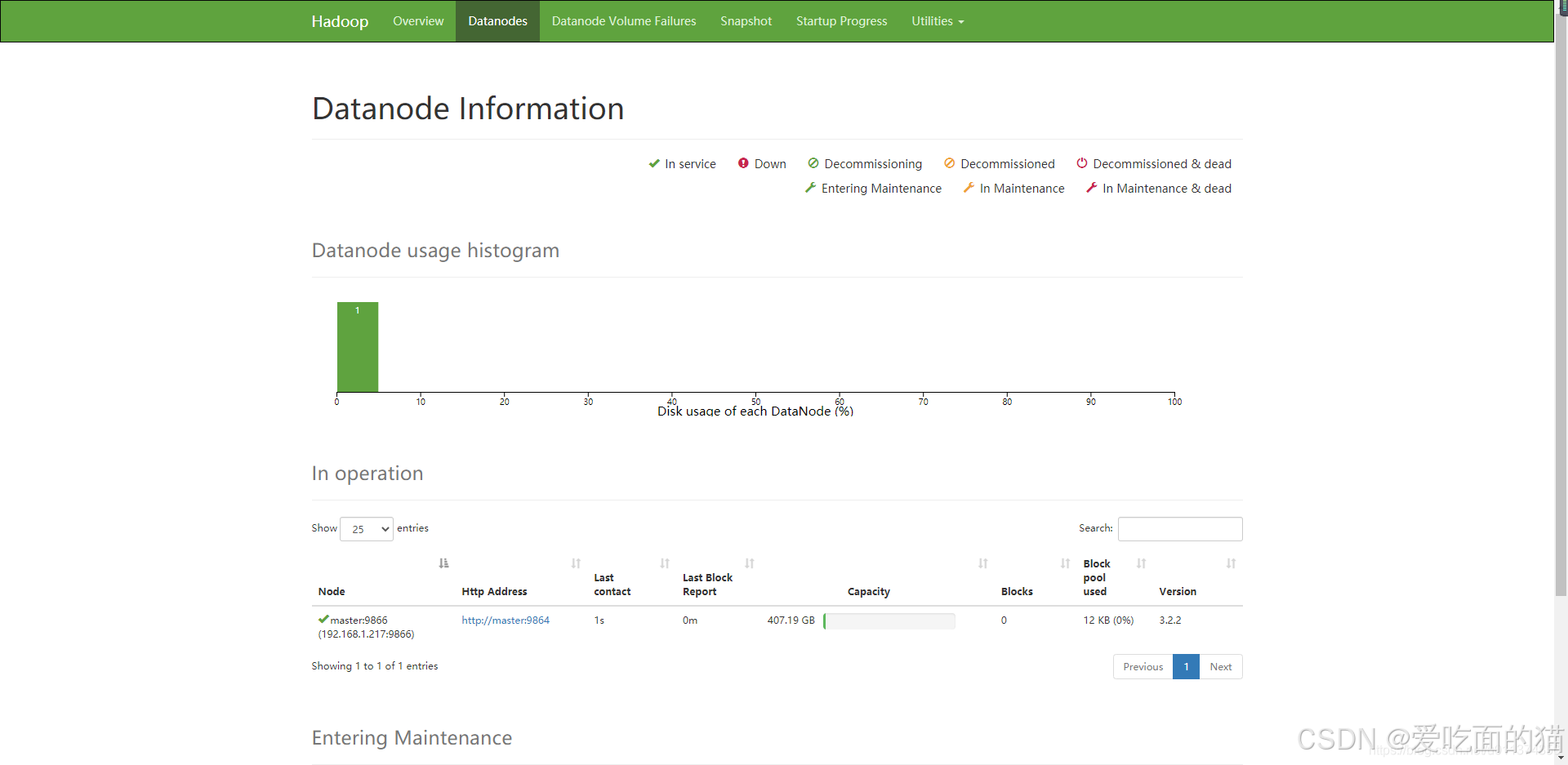
5、访问HDFS系统
访问HDFS分布式文件系统的web页面,如:http://192.168.200.130:9870/
6、启动yarn
启动Yarn进程。
cd /opt/module/hadoop/sbin
>> start-yarn.sh
使用 jps 查看启动进程
7、访问Yarn平台页面
访问hadoop分布式yarn页面,如:http://192.168.200.130:8088/
8、Hadoop的集群模式(伪分布式省略)
如果是伪分布式模式,此过程可以省略。
8.1.集群规划
|
模块 |
hadoop001 |
hadoop002 |
hadoop003 |
|
HDFS子进程 |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN子进程 |
NodeManager |
ResourceManager NodeManager |
NodeManager |
8.2.设置免密登陆
配置集群免密登录
8.3.修改hdfs-site.xml
修改数据的副本数量
secondname的主机设置(可选)
<!-- 数据的副本数量 改为3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property><!--可选 对于学习来说,可以不改。但实际生产过时会将其规划到 hadoop003 -->
<!-- 设置secondname的端口,完全分布式的集群模式,改为hadoop003 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:6002</value>
</property>
8.4.修改workers
将原来的localhost改为节点主机名
hadoop001
hadoop002
hadoop003
8.5.修改mapred-site.xml
配置历史服务器(可选)
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
8.6.修改yarn-site.xml
指定ResourceManager的地址:对于目前学习来说不改也可以,但在实际生产过程中 resourcemanager 和 namenode是在不同主机上,避免生产过程中资源不足导致内存溢出情况。
指定ResourceManager的地址(可选)
配置日志的聚集(可选)
<!-- 可选 指定ResourceManager的地址-->
<!-- NodeManager 和 ApplicationMaster 会通过该主机名连接到 ResourceManager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property><!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
8.7.分发文件
注意:在分发文件前要做好三台机器的IP与主机名映射 /etc/hosts
进行分发文件
scp -r /opt/module/hadoop root@hadoop002:/opt/module/hadoop
scp -r /opt/module/hadoop root@hadoop003:/opt/module/hadoop
scp -r /opt/module/java root@hadoop002:/opt/module/java
scp -r /opt/module/java root@hadoop003:/opt/module/java
scp -r /etc/profile root@hadoop002:/etc/profile
scp -r /etc/profile root@hadoop003:/etc/profile
让三台机器文件生效
ssh hadoop001;source /etcprofile;
ssh hadoop002;source /etcprofile;
ssh hadoop003;source /etcprofile;ssh hadoop001;

8.8.停止服务删除目录
停止服务
cd /opt/module/hadoop/sbin
>> stop-all.sh
删除格式化后的目录重新格式化
rm -rf /opt/module/hadoop/data
rm -rf /opt/module/hadoop/logs/*
/opt/module/hadoop/bin/hdfs namenode -format
8.9.重启服务
在hadoop001 上启动HDFS
cd /opt/module/hadoop/sbin
>> start-dfs.sh
在hadoop002 上启动YARN
cd /opt/module/hadoop/sbin
>> start-yarn.sh
群起脚本:
touch /usr/bin/hdall.sh
chmod 777 /usr/bin/hdall.sh
vi /usr/bin/hdall.sh
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop001 "/opt/module/hadoop/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop002 "/opt/module/hadoop/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop001 "/opt/module/hadoop/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop001 "/opt/module/hadoop/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop002 "/opt/module/hadoop/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop001 "/opt/module/hadoop/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac群起:/usr/bin/hdall.sh start
群停:/usr/bin/hdall.sh stop
如果:ResourceManager的地址和secondname的地址都是hadoop001,则在hadoop001 上启动HDFS和YARN
cd /opt/module/hadoop/sbin
>> start-all.sh
三、msyql安装
1、卸载旧MySQL文件
若之前安装过其他的sql执行这个步骤。
执行命令
# yum remove mysql mysql-server mysql-lib mysql-server
•再查看当前安装mysql的情况看卸载情况:
# rpm -qa|grep -i mysql
可以看到之前安装的包,然后执行删除命令,全部删除
# rpm -ev MySQL-devel--5.1.52-1.el6.i686 --nodeps
•查找之前老版本MySQL的目录,并删除老版本的MySQL的文件和库
# find / -name mysql
删除查找到的所有目录
#例如:rm -rf /run/lock/subsys/mysql
#例如: rm -rf /etc/selinux/targeted/active/modules/100/mysql # rm -rf /var/lib/mysql
•手动删除/etc/my.cnf
# rm -rf /etc/my.cnf
•再次查询如果无,则删除干净
# rpm -qa|grep -i mysql删除 mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs
rpm -e --nodeps mysql-libs-5.1.52-1.el6_0.1.x86_64
2、Mysql下载安装
1.1 下载
官网网址:MySQL :: Download MySQL Community Server
在这里下载的是如下版本的mysql
https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz1.2 上传
使用xshell上传到到linux服务器指定安装路径
此处是安装路径是 /usr/local
1.3 解压重命名
cd /usr/local/
# 如果是xz结尾压缩包用 tar -xvJf,如 tar -xvJf mysql-8.0.30-linux-glibc2.12-x86_64.tar.xz
重命令
tar -xzvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.26-linux-glibc2.12-x86_64 mysql
3、配置环境变量
vim /etc/profile
export MYSQL_HOME=/usr/local/mysql
export PATH=$PATH:$MYSQL_HOME/bin使环境生效
source /etc/profile
4、删除用户组
删除用户组
cat /etc/group|grep mysqluserdel mysql
groupdel mysql
5、创建用户和组
groupadd mysql
useradd -r -g mysql mysql
6、创建文件夹
mkdir /usr/local/mysql/data
7、更改权限
更改mysql目录下所有的目录及文件夹所属的用户组和用户,以及赋予可执行权限
chown -R mysql:mysql /usr/local/mysql/data/
chmod -R 755 /usr/local/mysql/data/
chown -R mysql:mysql /usr/local/mysql/
chmod -R 755 /usr/local/mysql/
8、安装依赖包
安装mysql的依赖包
yum install libaio
或者
yum install -y mariadb-server 安装mariadb-server 5.X版本使用
9、初始化
执行初始化命令:
/usr/local/mysql/bin/mysqld --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ --initialize
#说明
–initialize 初始化(真正开始干活)
–user=mysql 以mysql用户的身份初始化数据库,产生文件都是mysql作为拥有者
–basedir=xxx mysql其安装目录,非常重要
–lower_case_table_names=1 不区分大小写,如果初始化不指定,必须重装才能解决,非常重要
10、记住初始密码

11、将mysql加入到服务中
复制
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql#注意:默认情况下,GBLIC版本的数据库要求安装到/usr/local/mysql目录,其mysql.server脚本中对应的目录也是/usr/local/mysql,这会导致mysql无法启动。所以可以更改其basedir以及datadir两个变量,我们后面在 my.cnf 中配置。
#赋予可执行权限
chmod +x /etc/init.d/mysql
#添加服务
chkconfig --add mysql
#显示服务列表
chkconfig --list mysql
12、配置文件
(1)Mysql5.X版本配置
Mysql是5.x版本使用此配置
vi /etc/my.cnf
[mysqld]
port=3306
user=mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/tmp/mysqld.sock
#character config
character_set_server=utf8mb4
explicit_defaults_for_timestamp=true
(2)Mysql8.X版本配置
Mysql是8.x版本使用此配置
8.0版
注意:使用配置前一定要创建好目录
mkdir /usr/local/mysql/tmp
mkdir /usr/local/mysql/log
touch /usr/local/mysql/log/mysqld_safe.err
chown -R mysql:mysql /usr/local/mysql/tmp
chown -R mysql:mysql /usr/local/mysql/log
chown -R mysql:mysql /usr/local/mysql/log/mysqld_safe.err
简单配置(推荐)
vi /etc/my.cnf
[mysql]
user=mysql
default-character-set=utf8
socket=/usr/local/mysql/tmp/mysql.sock[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
user=mysql
log_timestamps=SYSTEM
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin= mysql_native_password[mysqld_safe]
log-error=/usr/local/mysql/log/mysqld_safe.err
pid-file=/usr/local/mysql/tmp/mysqld.pid
13、设置开机启动
设置开机启动:chkconfig mysql on
启动mysql :service mysql start
如果碰到下面问题可以进行参考
问题报错解决方案
启动报错:
Starting MySQL.2023-06-25T04:58:08.333370Z mysqld_safe error: log-error set to ‘/usr/local/mysql/log/mysqld_safe.err’, however file don’t exists. Create writable for user ‘mysql’.
ERROR! The server quit without updating PID file (/usr/local/mysql/pid/mysqld.pid).解决方案
[root@mysql]# touch /usr/local/mysql/log/mysqld_safe.err
[root@mysql]# chown -R mysql:mysql /usr/local/mysql/log/mysqld_safe.err启动报错:
my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
Starting MySQL.my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
ERROR! The server quit without updating PID file (/usr/local/mysql/data/localhost.localdomain.pid).解决方案
/etc/my.cnf 权限给的是 777,需要改成644,再次重新启动即可。
14、并查看进程
查看进程与状态:
ps -ef|grep mysql;
service mysql status;

15、创建软连接
ln -s /usr/local/mysql/bin/mysql /usr/bin
16、登录 Mysql
mysql -uroot -p
输入密码(初始化时候的密码)
注意:如果输入密码报错
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
解决方案
修改配置文件my.cnf 中 socket = /usr/local/mysql/tmp/mysql.sock,并重启mysql:service mysql restart;
17、修改密码
(1)Mysql5.X版本修改密码
Mysql是5.x版本使用此方式修改密码
8.0以下修改密码
修改密码
use mysql;
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('newpassword');
flush privileges;
(2)Mysql8.X版本修改密码
Mysql是8.x版本使用此方式修改密码
8.0以上修改密码
alter user "root"@"localhost" identified by "root";
use mysql;
UPDATE user SET authentication_string="" WHERE user="root";
FLUSH PRIVILEGES;
update user set Host="%" where User="root";
flush privileges;
alter user "root"@"%" identified by "root";
flush privileges;说明:
- UPDATE user SET authentication_string="" WHERE user="root"; 更新user表,将用户名为root的用户的authentication_string字段设置为空字符串。实际上是在清空root用户的密码。
- update user set Host="%" where User="root"; 更新user表,它将用户名为root的用户的Host字段设置为%。即root用户可以从任何主机进行连接。默认情况下,root用户可能只能从localhost进行连接。
- alter user "root"@"%" identified by "root"; 更改用户的认证信息。它指定了用户名为root且来源主机为任意主机(%)的用户,并将其密码设置为root。这是在新版本的MySQL中设置或更改用户密码的推荐方式。
18、授权
(1)Mysql5.X版本授权
Mysql是5.x版本使用此方式授权
授权
8.0以下授权:登录后执行下面命令
grant all privileges on *.* to 'root'@'%' identified by '密码123456' with grant option;
flush privileges;说明:
- all privileges:表示将所有权限授予给用户。也可指定具体的权限,如:SELECT、CREATE、DROP等。
- on:表示这些权限对哪些数据库和表生效,格式:数据库名.表名,这里写“*”表示所有数据库,所有表。如果我要指定将权限应用到test库的user表中,可以这么写:test.user
- to:将权限授予哪个用户。格式:”用户名”@”登录IP或域名”。%表示没有限制,在任何主机都可以登录。比如:”yangxin”@”192.168.0.%”,表示yangxin这个用户只能在192.168.0IP段登录
- identified by:指定用户的登录密码
(2)Mysql8.X版本授权
Mysql是8.x版本使用此方式授权
8.0以上授权
为了用 navicate工具 访问数据库,进行以下设置进行授权:
use mysql;
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root';
flush privileges;
说明:
- ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root'; #还原密码验证插件,将MySQL8的密码认证插件由caching_sha2_password更换成mysql_native_password
四、HIve安装
1、下载安装
1.1下载
下载地址:http://archive.apache.org/dist/hive/
我们选择apache-hive-3.1.3-bin.tar.gz版本学习
1.2 上传
1.3 解压重命名
2、配置环境变量
vi /etc/profile
export HIVE_HOME=/opt/lmodule/hiveexport PATH=$PATH:$HIVE_HOME/bin
刷新配置
source /etc/profile
3、配置文件
配置hive-env.sh (位置:/opt/mudule/hive/conf)
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/module/hadoop# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/hive/conf#Folder containing extra libraries required for hive compilation/execution can be controlled:
export HIVE_AUX_JARS_PATH=/opt/module/hive/lib
配置hive-site.xml (位置:/opt/mudule/hive/conf) (直连模式配置)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--MySQL信息-->
<!--数据库连接地址配置-->
<property>
<name>javax.jdo.option.ConnectionURL</name>注意:下面的&要变为“&加上amp;” 形式
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true</value>
</property>
<!--数据库驱动配置注意:mysql5.x与mysql8.x不同-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!--Hive表数据存储在HDFS路径-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--hive的临时数据目录,指定的位置在hdfs上的目录可以不指定有默认目录-->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
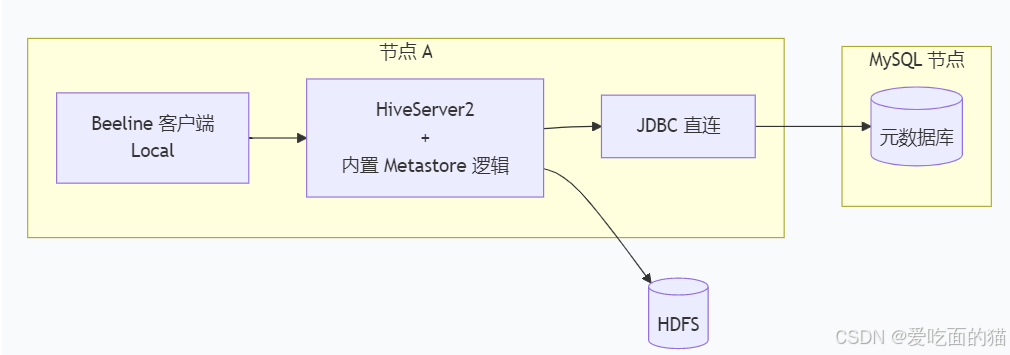
</property><!-- 直接连接模式使用下面配置,初学者推荐-->
<!--指定HiveServer2所在的host,改为自己主机名-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop001</value>
</property>
<!--指定HiveServer2所在的端口hs2端口默认是10000-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--指定HDFS系统-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property>
<!--不强制执行Metastore模式版本的一致性检查,默认值是true-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property><!-- 启用本地模式自动切换 -->
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Whether to automatically switch to local mode if the input file size is below threshold.</description>
</property>
<!-- 启用本地模式自动切换 -->
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>50000000</value>
<description>Maximum input size (in bytes) for auto-local mode.</description>
</property>
<!-- 设置最大输入文件数量(5个) -->
<property>
<name>hive.exec.mode.local.auto.input.files.max</name>
<value>5</value>
<description>Maximum number of input files for auto-local mode.</description>
</property>
</configuration>
说明:
当执行一些复杂sql会报错,下面是问题和解决方案
问题:
Query ID = root_20230914161708_a293bd1f-62bb-4a28-a477-97f71fc745b4
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
前面配置的一下几项是解决问题的配置;
<!-- 启用本地模式自动切换 -->
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Whether to automatically switch to local mode if the input file size is below threshold.</description>
</property>
<!-- 设置输入数据量最大字节数(50MB) -->
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>50000000</value>
<description>Maximum input size (in bytes) for auto-local mode.</description>
</property>
<!-- 设置最大输入文件数量(5个) -->
<property>
<name>hive.exec.mode.local.auto.input.files.max</name>
<value>5</value>
<description>Maximum number of input files for auto-local mode.</description>
</property>
配置hive-log4j2.properties (位置:/opt/mudule/hive/conf)
此步骤可以跳过,不配置也可以。
cd /opt/mudule/hive/conf
cp hive-log4j2.properties.template hive-log4j2.properties
vi hive-log4j2.properties
property.hive.log.dir = /opt/module/hive/logs
4、拷贝jar包
4.1 解压驱动(如果有jar包,直接上传此步省略)
需要提前现在对应的驱动包,并解压
4.2 拷贝mysql驱动
cp mysql-connector-java-8.0.30.jar /opt/module/hive/lib/
4.2 拷贝guava包
#hadoop和hive里面的guava包版本可能不一致,那么用hadoop里面的覆盖掉hive里面的
cp /opt/module/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive/lib/#删除hive的旧依赖包:
rm -rf /opt/module/hive/lib/guava-19.0.jar
4.3 删除 hive中的 log4j
删除 Hive 的lib目录中包含log4j-slf4j-impl-2.17.1.jar
rm -rf /opt/module/hive/lib/log4j-slf4j-impl-2.17.1.jar
5、初始化
5.1 启动msyql
# 先查看mysql是否启动
sudo systemctl status mysql
#未启动则进行启动
service mysql start
5.2 启动hadoop
#进入hadoop安装目录启动hadoop
cd /opt/module/hadoop/
sbin/start-all.sh
5.3 初始化hive
#进入hive安装目录
cd /opt/module/hive
#执行初始化命令,#初始化Hive
bin/schematool -dbType mysql -initSchema
初始化成功

6、启动hive
启动hive
# 启动HiveServer2(直连模式只需启动这一个服务,无需启动MetaStore)
hive --service hiveserver2 > $HIVE_HOME/hiveserver2.log 2>&1 &验证测试:
jps | grep HiveServer2
netstat -nlp | grep 10000测试连接:
# 方式1:直接进入beeline#进入hive安装目录
cd /opt/module/hive
#使用命令验证hive是否安装成功
bin/hive
#进入hive shell,使用 show databases; 查看数据,说明安装成功!
# 方式2:手动连接
beeline
beeline> !connect jdbc:hive://hadoop001:10000
# 用户名输入 root,密码直接回车(留空)# 测试命令 show databases; create table remote_test (id int, name string) row format delimited fields terminated by '\t'; insert into remote_test values (1, 'remote'), (2, 'mode'); select * from remote_test;

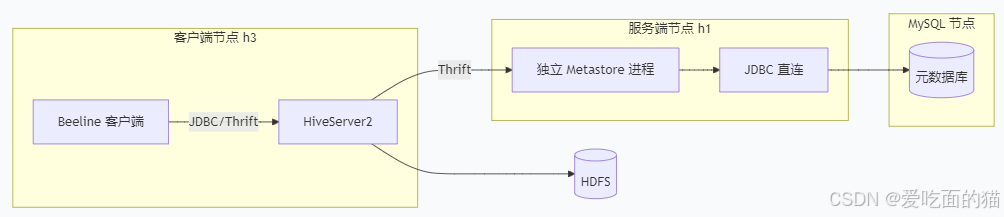
五、远程服务模式配置(初学者忽略)
与 上面 Hive安装 所有安装步骤相同, 不同的是配置文件。
1、服务端hive-site.xml配置
在服务端例如是 hadoop001 上。hive-site.xml配置如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--MySQL信息-->
<!--数据库连接地址配置-->
<property>
<name>javax.jdo.option.ConnectionURL</name>注意:下面的&要变为“&加上amp;” 形式
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true</value>
</property>
<!--数据库驱动配置注意:mysql5.x与mysql8.x不同-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!--Hive表数据存储在HDFS路径-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--hive的临时数据目录,指定的位置在hdfs上的目录可以不指定有默认目录-->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property><!-- 远程服务模式 开始-->
<!-- MetaStore服务绑定地址和端口(客户端通过此地址连接) --> <property> <name>hive.metastore.uris</name> <value>thrift://h1:9083</value> </property> <!-- HiveServer2绑定地址和端口 --> <property> <name>hive.server2.thrift.bind.host</name> <value>h1</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property><!-- 远程服务模式 结束-->
<!--不强制执行Metastore模式版本的一致性检查,默认值是true-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property><!-- 启用本地模式自动切换 -->
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Whether to automatically switch to local mode if the input file size is below threshold.</description>
</property>
<!-- 启用本地模式自动切换 -->
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>50000000</value>
<description>Maximum input size (in bytes) for auto-local mode.</description>
</property>
<!-- 设置最大输入文件数量(5个) -->
<property>
<name>hive.exec.mode.local.auto.input.files.max</name>
<value>5</value>
<description>Maximum number of input files for auto-local mode.</description>
</property>
</configuration>
2、服务端启动
在服务端例如是 hadoop001 上。hive-site.xml配置如下
# 启动MetaStore服务(关键!远程模式必须启动)
hive --service metastore > $HIVE_HOME/metastore.log 2>&1 &# 启动HiveServer2服务
hive --service hiveserver2 > $HIVE_HOME/hiveserver2.log 2>&1 &# 验证进程
jps | grep -E "MetaStore|HiveServer2"
# 应看到 MetaStore 和 HiveServer2 两个进程
3、客户端hive-site.xml配置
拷贝Hive的安装目录到客户端 hadoop002 节点上的同目录下,并配置环境变量。
在客户务端例如是 hadoop002 上。hive-site.xml配置如下:
<configuration>
<!-- 客户端只需配置MetaStore服务地址,无需任何MySQL信息! -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop001:9083</value>
</property>
<!-- 可选:如果客户端也需要提交作业,配置HiveServer2地址 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop001</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
4、客户端测试
在客户务端例如是 hadoop002 上。hive-site.xml配置如下:
# 在hadoop002节点执行
# 方式1:直接进入beeline
hive# 方式2:手动连接
beeline
beeline> !connect jdbc:hive://hadoop001:10000
# 用户名:root,密码:直接回车# 测试命令
show databases;
create table remote_test (id int, name string) row format delimited fields terminated by '\t';
insert into remote_test values (1, 'remote'), (2, 'mode');
select * from remote_test;
六、问题与说明:
安装 apache-hive-3.1.3-bin.tar.gz 配套 hadoop-3.2.2.tar.gz 可能会卡顿。如果卡顿,将 hadoop-3.2.2.tar.gz 换为 hadoop-3.0.0 或 hadoop-3.2.1 测试一下。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 32
32 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)