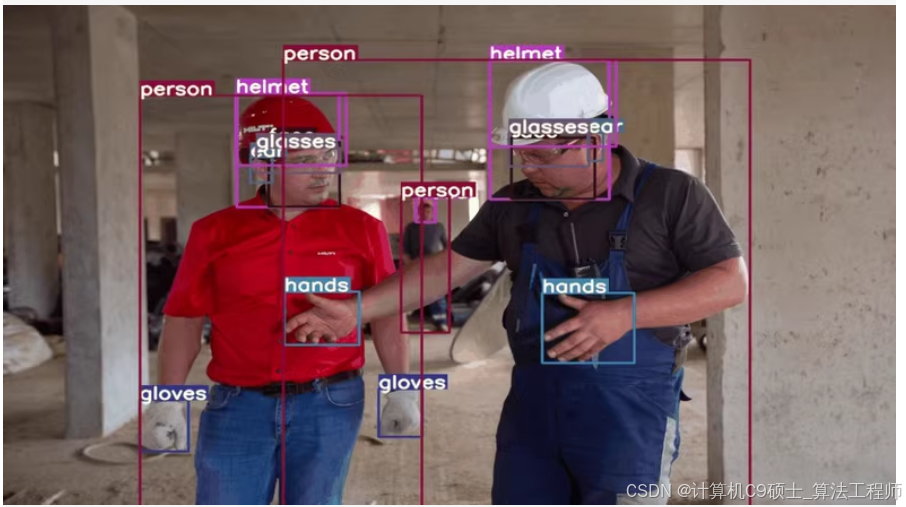
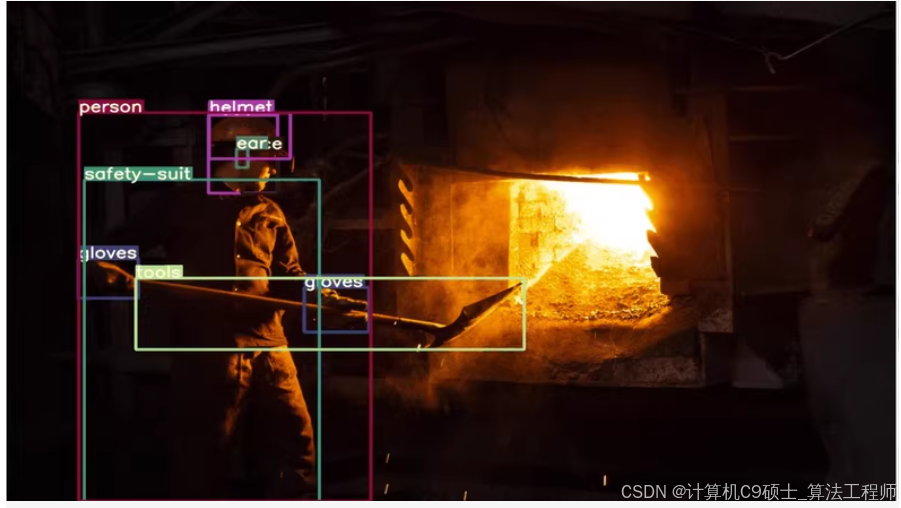
工地篇——使用YOLOv8来训练一个包含超过8000张高质量图像的智慧工业防护数据集。这个数据集包含17个类别,已标注为VOC和YOLO格式,可以直接用于模型训练。
如何训练智慧工业防护数据集,收集各种工业环境,高质量图像(超过8000张最低1080p)丰富的标注实例(超过7万个标注),标注类型包括人,头,脸,眼镜,医用口罩,面罩,耳朵,耳罩,手部,手套,脚,鞋,安全马甲,工具,安全帽,医用服装,安全服共17类别,基本涵盖所有工业场景下搜集的图像,共14GB数据量,voc和yolo格式都有
使用YOLOv8来训练一个包含超过8000张高质量图像的智慧工业防护数据集。这个数据集包含17个类别,已标注为VOC和YOLO格式,可以直接用于模型训练。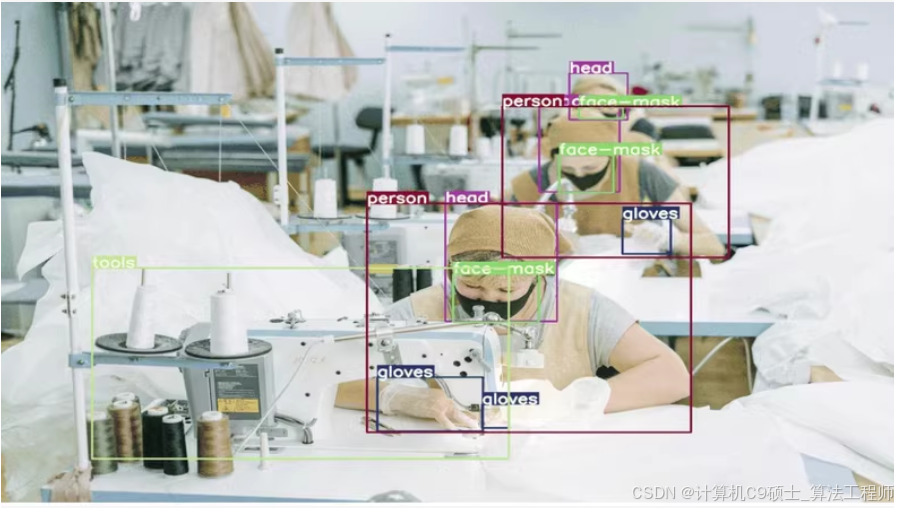
数据集描述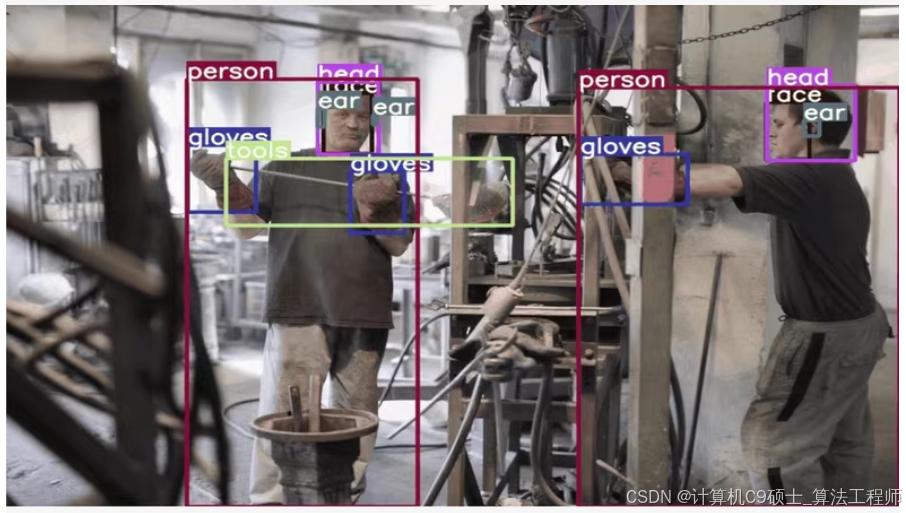
数据量:超过8000张图像,每张图像至少1080p分辨率
标注实例:超过7万个标注实例
类别:
0: 人(Person)
1: 头(Head)
2: 脸(Face)
3: 眼镜(Glasses)
4: 医用口罩(Medical Mask)
5: 面罩(Face Shield)
6: 耳朵(Ear)
7: 耳罩(Ear Muffs)
8: 手部(Hand)
9: 手套(Gloves)
10: 脚(Foot)
11: 鞋(Shoes)
12: 安全马甲(Safety Vest)
13: 工具(Tool)
14: 安全帽(Safety Helmet)
15: 医用服装(Medical Clothing)
16: 安全服(Safety Suit)
标注格式:VOC和YOLO格式
应用场景:智慧工业防护
数据集组织
假设你的数据集目录结构如下:
industrial_protection_dataset/
├── images/
│ ├── train/
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── …
│ ├── val/
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── …
│ └── test/
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── …
├── labels_voc/
│ ├── train/
│ │ ├── 000001.xml
│ │ ├── 000002.xml
│ │ └── …
│ ├── val/
│ │ ├── 000001.xml
│ │ ├── 000002.xml
│ │ └── …
│ └── test/
│ ├── 000001.xml
│ ├── 000002.xml
│ └── …
├── labels_yolo/
│ ├── train/
│ │ ├── 000001.txt
│ │ ├── 000002.txt
│ │ └── …
│ ├── val/
│ │ ├── 000001.txt
│ │ ├── 000002.txt
│ │ └── …
│ └── test/
│ ├── 000001.txt
│ ├── 000002.txt
│ └── …
└── data.yaml # 数据配置文件
数据配置文件
创建或确认data.yaml文件是否正确配置了数据集路径和类别信息:
train: ./images/train/ # 训练集图像路径
val: ./images/val/ # 验证集图像路径
test: ./images/test/ # 测试集图像路径
Classes
nc: 17 # 类别数量
names:
- Person
- Head
- Face
- Glasses
- Medical Mask
- Face Shield
- Ear
- Ear Muffs
- Hand
- Gloves
- Foot
- Shoes
- Safety Vest
- Tool
- Safety Helmet
- Medical Clothing
- Safety Suit # 类别名称列表
安装YOLOv8
如果你还没有安装YOLOv8,可以使用以下命令安装:
bash
深色版本
pip install ultralytics
训练模型
使用YOLOv8训练模型的命令非常简单,你可以直接使用以下命令开始训练:
cd path/to/industrial_protection_dataset/
克隆YOLOv8仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
开始训练
python yolo.py detect train data=…/data.yaml model=yolov8n.pt epochs=100 imgsz=1080 batch=16
在这个命令中:
data=…/data.yaml:指定数据配置文件。
model=yolov8n.pt:指定预训练权重,这里使用的是YOLOv8的小模型。
epochs=100:训练轮数。
imgsz=1080:输入图像的大小(由于图像分辨率较高,建议设置为1080)。
batch=16:批量大小。
模型评估
训练完成后,可以使用以下命令评估模型在验证集上的表现:
python yolo.py detect val data=…/data.yaml model=runs/detect/train/weights/best.pt imgsz=1080
这里的runs/detect/train/weights/best.pt是训练过程中产生的最佳模型权重文件。
模型预测
你可以使用训练好的模型对新图像进行预测:
python yolo.py detect predict source=path/to/your/image.jpg model=runs/detect/train/weights/best.pt imgsz=1080 conf=0.4 iou=0.5
查看训练结果
训练过程中的日志和结果会保存在runs/detect/目录下,你可以查看训练过程中的损失、精度等信息。
数据增强
为了进一步提高模型性能,可以使用数据增强技术。以下是一个简单的数据增强示例:
安装albumentations库:
pip install -U albumentations
在yolo.py中添加数据增强:
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
定义数据增强
transform = A.Compose([
A.RandomSizedBBoxSafeCrop(width=1080, height=1080, erosion_rate=0.2),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Rotate(limit=10, p=0.5, border_mode=cv2.BORDER_CONSTANT),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, p=0.5),
A.GaussNoise(var_limit=(10.0, 50.0), p=0.5),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2()
], bbox_params=A.BboxParams(format=‘yolo’, label_fields=[‘class_labels’]))
在数据加载器中应用数据增强
def collate_fn(batch):
images, targets = zip(*batch)
transformed_images = []
transformed_targets = []
for img, target in zip(images, targets):
bboxes = target['bboxes']
class_labels = target['labels']
augmented = transform(image=img, bboxes=bboxes, class_labels=class_labels)
transformed_images.append(augmented['image'])
transformed_targets.append({
'bboxes': augmented['bboxes'],
'labels': augmented['class_labels']
})
return torch.stack(transformed_images), transformed_targets
注意事项
数据集质量:确保数据集的质量,包括清晰度、标注准确性等。
模型选择:可以选择更强大的模型版本(如YOLOv8m、YOLOv8l等)以提高性能。
超参数调整:根据实际情况调整超参数,如批量大小(batch)、图像大小(imgsz)等。
监控性能:训练过程中监控损失函数和mAP指标,确保模型收敛。
通过上述步骤,你可以使用YOLOv8来训练一个智慧工业防护数据集,并使用训练好的模型进行预测。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 10
10 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)