吴恩达机器学习-支持向量机
优化目标支持向量机也被称为大间距分类器,因为他会以最大间距分隔样本我们可以从优化目标来一步步认识支持向量机sigmoid函数:在逻辑回归中,一个样本的代价函数的形式为:根据y的值不同,我们分别画出不同的函数图像当y = 1 时,函数只剩下左边部分,可得到左图形式的函数图像,右边同理我们用近似的折线来代替这个函数(即一条水平线加一条斜线),先不用管这个斜线的斜率是多少我们将左图蓝色的函数记为cost
优化目标
支持向量机也被称为大间距分类器,因为他会以最大间距分隔样本
我们可以从优化目标来一步步认识支持向量机
sigmoid函数: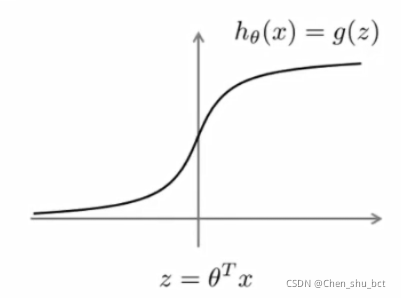
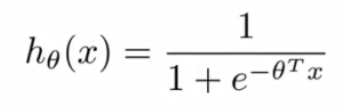
在逻辑回归中,一个样本的代价函数的形式为:
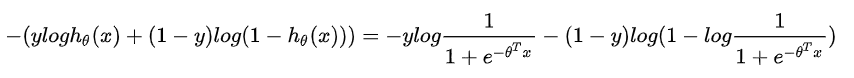
根据y的值不同,我们分别画出不同的函数图像
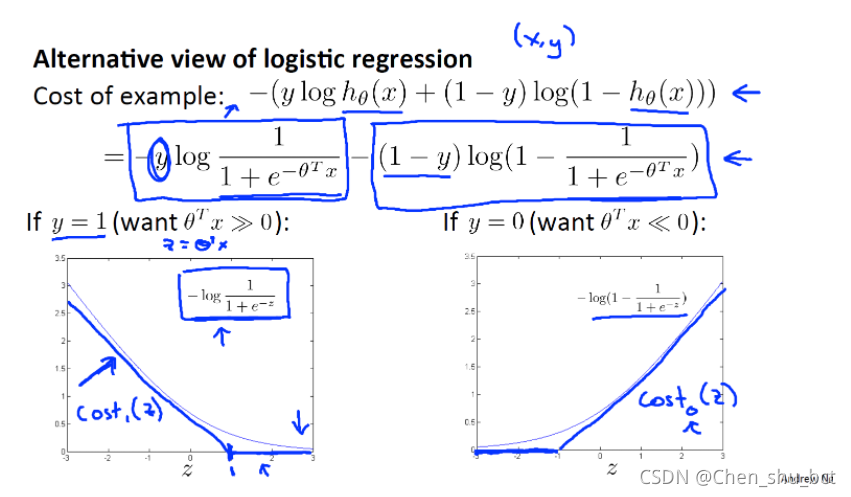
当y = 1 时,函数只剩下左边部分,可得到左图形式的函数图像,右边同理
我们用近似的折线来代替这个函数(即一条水平线加一条斜线),先不用管这个斜线的斜率是多少
我们将左图蓝色的函数记为cost1(z),将右边蓝色的函数记为cost0(z),下标表示的是y的值不同的
接下来我们就可以构造支持向量机了
代价函数
首先,对逻辑回归中的代价函数进行一点改造

如图所示,我们将逻辑回归的代价函数前面的参数进行一点改造,
由于m对于数据集是个常数,所以前后的1/m都约去,最后得到的θ是一样的
另外,我们将 -log(hθ(x(i)))用cost1(θTx(i))代替,后面的同理
在支持向量机中,我们引入一个C = 1/ λ ,从而得到最后的支持向量机的代价函数的形式
C便是代价函数的权重,如果C取到了很大的值,那么就相当于给了代价函数一个很高的权重,则容易过拟合
相反,如果C取到了特别小的值,就等于给了代价函数一个很低的权重
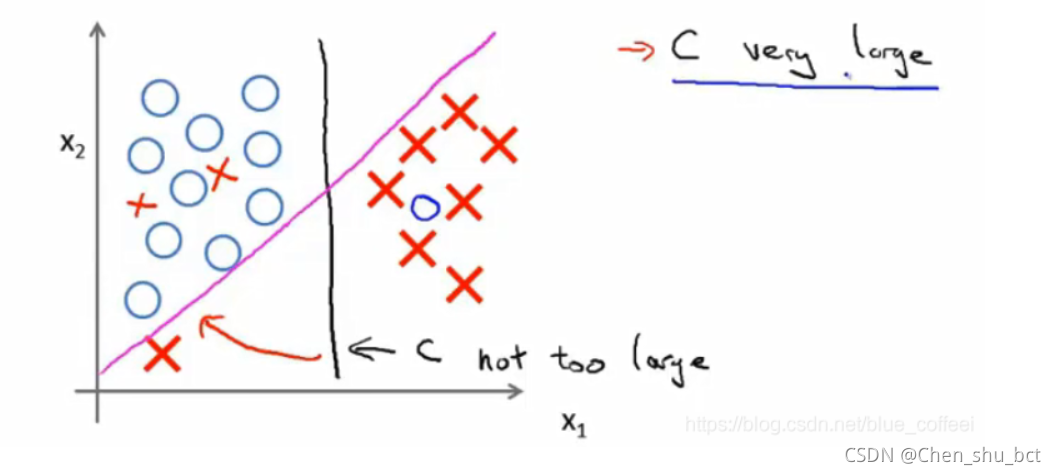
如图,如果C特别大,则会拟合的非常好,但容易被异常点给影响
如果给C一个合适的值,便仍然能得到图中黑色的判定边界
最大间距分类器
现在我们来观察一下我们的优化函数的后半部分
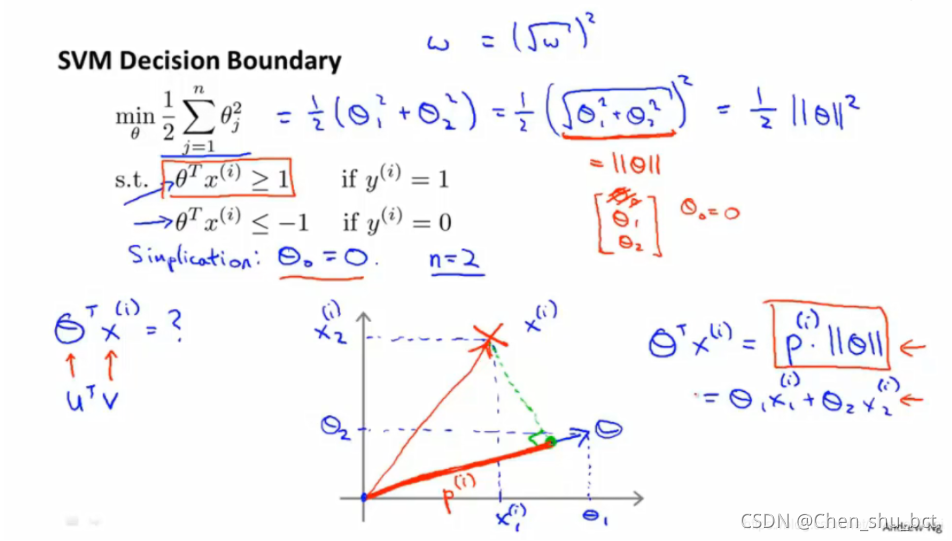
如图,我们可以将优化目标看为向量Θ的范式,而由向量的内积知识可得,θTx(i)等于x在θ上的投影p乘以Θ的范式
我们要降低θ的范式,又要保证等式的成立,则会选择范式最小的情况,同时,p则会变大
也就是说,支持向量机会选择整体来说投影长度最长的那个θ
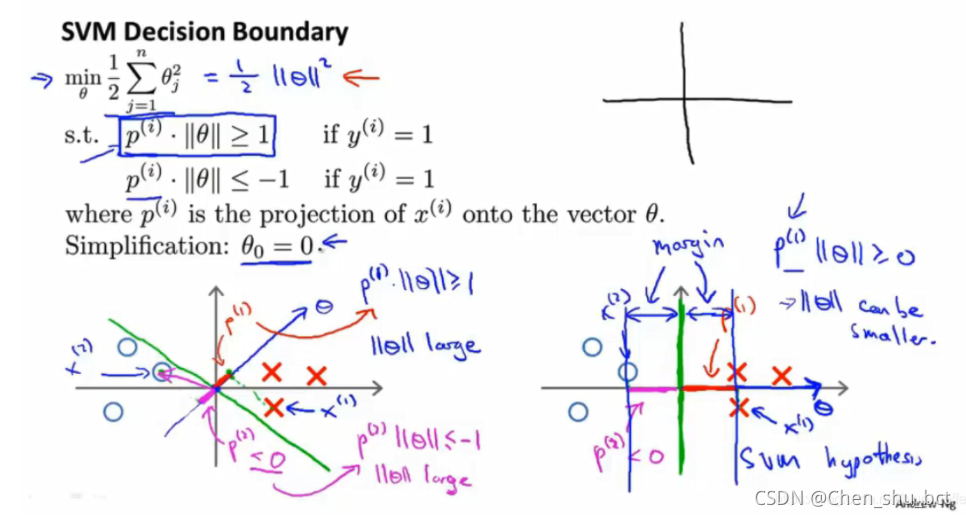
如图这种情况,θ会更加倾向于水平的情况
同时,我们知道,决策边界与θ是垂直的,所以就能得到右图中绿色的决策边界了
核函数
但是,如果样本是线性不可分的,我们则需要构造一些特征来拟合样本
形如: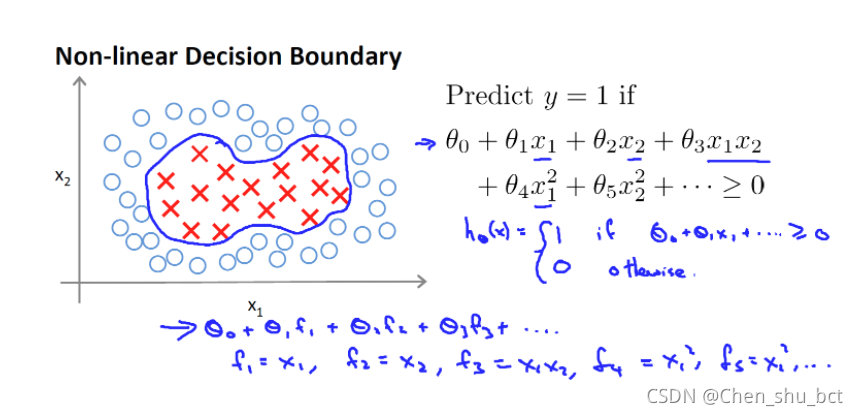
但是,我们构造的各种特征,我们也无法确定他们是不是我们真正需要的,因此,我们引入核函数的概念来解决这个问题
首先,人为的选定几个点,以这几个点为基础,给定 x ,构造函数 f ,用来衡量x与这几个点l的相似性
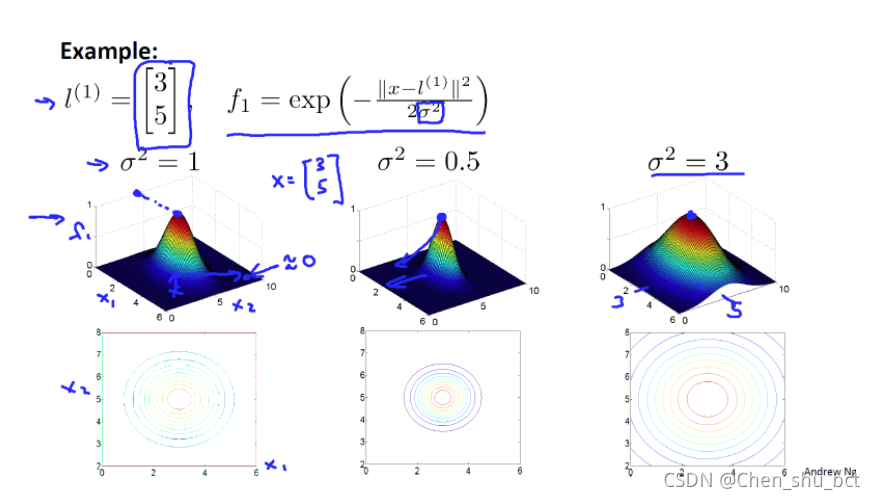
由上图可看出,σ越大收敛越慢,变化也越平滑,反之收敛越快
那么问题来了,上面所说的点都是手动选的,但是我们该如何选择这些点呢?
每个数据集中的数据正样本x(i),我们都取一个对应的点 l(i)

对任意一个x,我们依次计算x与l的各个分量的相似程度,
f(i)应当为一个向量,记录了x(i)对应各个l(i)的核函数的值,
然后将f(i)与θT相乘得到一个值,从而判断x(i)对应的标签是0还是1
如果 θT f(i) >= 0 ,那么 x(i)对应的标签就为 1
如果用了核函数的话,对应的代价函数也要相应的改变

此处,将最后的n改为了m,其实在这里两者是等价的,因为有m个样本,我们就会手动取m个点,从而构造m个核函数对应的特征 f ,从而 θ也就变成了 m + 1 维
实际应用
如何选择逻辑回归与支持向量机呢?
如果n很大,接近m,那么使用Logistic回归或者线性SVM;
如果n很小,m大小适中,使用高斯核函数;
如果n很小,m很大,则可以创建新的特征然后使用logistic回归或者线性SVM
神经网络在上面几种情况下都可能有较好的表现,但训练神经网络非常慢。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)