一区Top8.5分杂志发表中国学者机器学习论文,用“森林之神”方法筛选变量
引言“森林之神”——Boruta算法,是基于随机森林的一种特征选择方法,可以从众多特征中筛选出最重要的部分。今天分享的这篇一区top(IF 8.5)文章,学者就通过Boruta算法筛选变量,并通过四种机器学习算法构建了预测模型!慢性心力衰竭(CHF)是导致心血管相关死亡的主要原因之一,对人类健康构成重大威胁。应激性高血糖比(SHR)作为一种评估患者在急性医疗事件中体内血糖水平变化的指标,与多种重

引言
“森林之神”——Boruta算法,是基于随机森林的一种特征选择方法,可以从众多特征中筛选出最重要的部分。今天分享的这篇一区top(IF 8.5)文章,学者就通过Boruta算法筛选变量,并通过四种机器学习算法构建了预测模型!
慢性心力衰竭(CHF)是导致心血管相关死亡的主要原因之一,对人类健康构成重大威胁。应激性高血糖比(SHR)作为一种评估患者在急性医疗事件中体内血糖水平变化的指标,与多种重症疾病的不良结局相关。
然而,目前尚不清楚SHR是否与先前患有CHF且入住重症监护病房(ICU)患者的死亡风险相关。
2024年12月7日,中国学者用MIMIC-IV 数据库,在期刊《Cardiovascular Diabetology》(医学top一区,IF=8.5)发表题为:“Predicting 28-day all-cause mortality in patients admitted to intensive care units with pre-existing chronic heart failure using the stress hyperglycemia ratio: a machine learning-driven retrospective cohort analysis”的研究论文,旨在探究SHR水平与先前患有CHF的ICU患者的28天住院死亡率的关联,并通过四种机器学习算法(ML)构建预测模型。
研究结果表明,对于先前患有慢性心力衰竭的ICU患者,SHR可作为预测其28天住院死亡的独立因素。此外,在构建的四种预测模型中,神经网络算法的预测性能最佳。

本公号回复“ 原文”即可获得文献PDF等资料
研究团队基于MIMIC-IV数据库2008年~2019年的数据,经过纳排,最终纳入了913名年龄≥18岁患有CHF且入住ICU的患者,59%为男性。并且在28天的随访中,有488名患者在住院期间死亡。
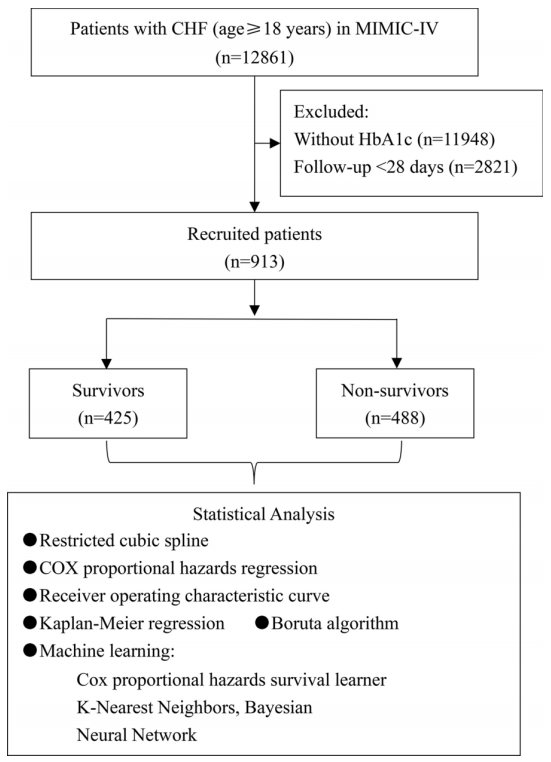
图1 研究流程
SHR可有效预测患者28天住院死亡率
首先,研究团队通过RCS曲线探究SHR水平与患者28天住院死亡率的关联,结果显示,患者28天死亡风险随着SHR水平的升高而增加。
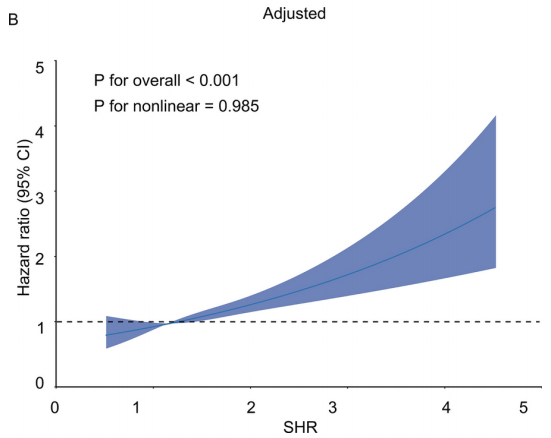
图2 SHR水平与患者28天住院死亡率关联的RCS
调整了年龄、合并症败血症、肺炎和充血性心力衰竭、生命体征、OASIS评分、实验室检测指标和药物等
同时,Cox比例风险回归模型结果表明,SHR与28天住院死亡率独立相关。并且,亚组分析结果与其一致。
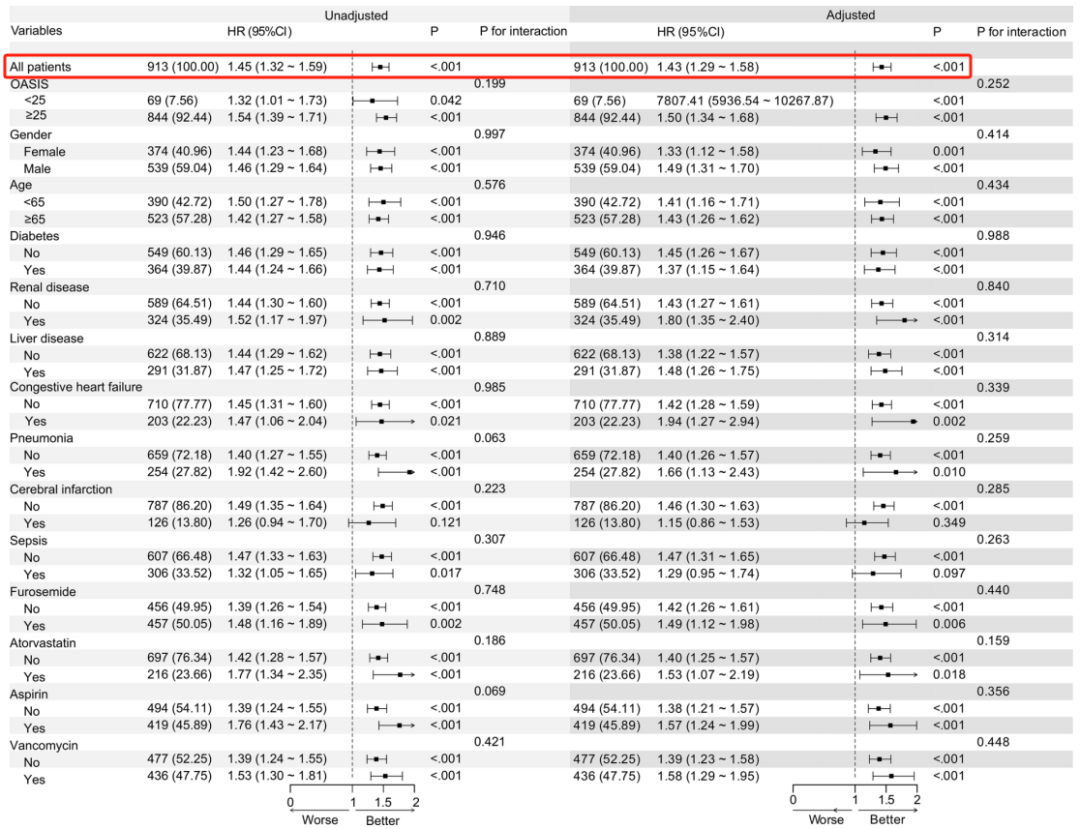
表1 COX比例风险回归和亚组分析
研究团队还通过绘制SHR、入院血糖(ABG)和糖化血红蛋白(HbA1c)的ROC曲线来预测患者28天的住院死亡率。结果表明,SHR(AUC=0.924)的预测能力优于ABG(AUC=0.910)和HbA1c(AUC=0.917 ),其截断值为0.57。
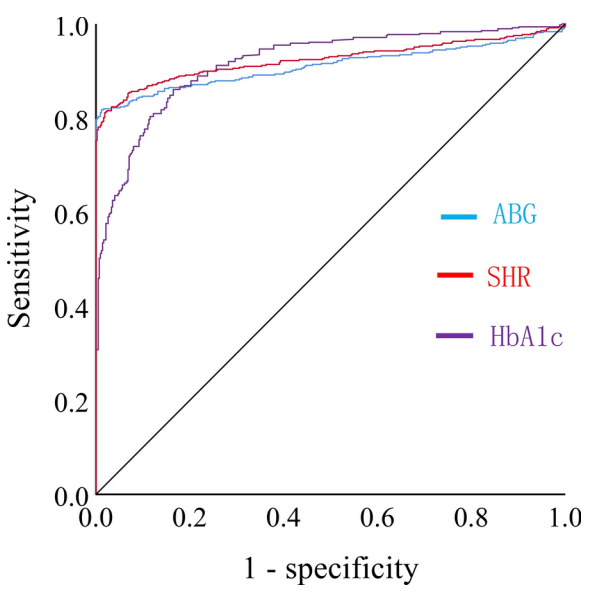
图3 ROC曲线
此外,研究团队根据SHR的截断值(0.57)将所有患者分为两组,并绘制了两组的Kaplan-Meier生存曲线。
结果表明,与SHR<0.57组相比,SHR≥0.57组患者的28天住院生存率显著降低。
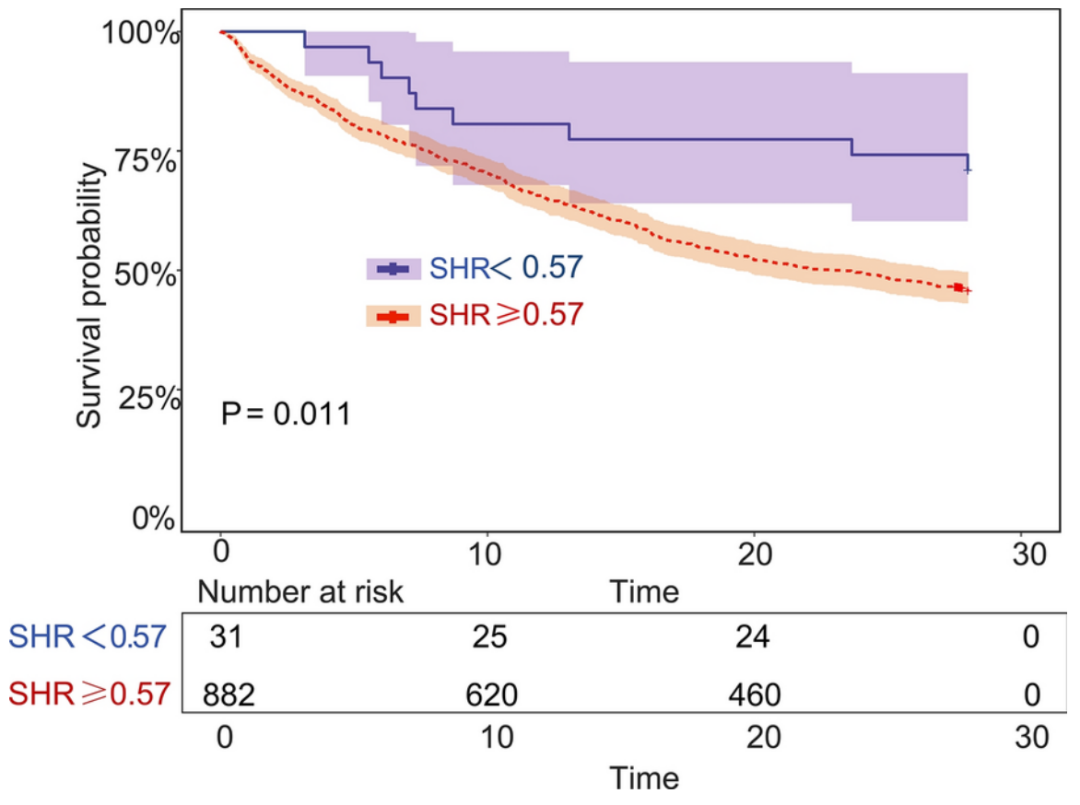
图4 Kaplan-Meier生存曲线
预测模型的构建与评估
√变量筛选
研究团队通过“森林之神”—Boruta算法,筛选出15个重要预测因子。其中,SHR是预测患者28天住院死亡率的关键预测因子之一。
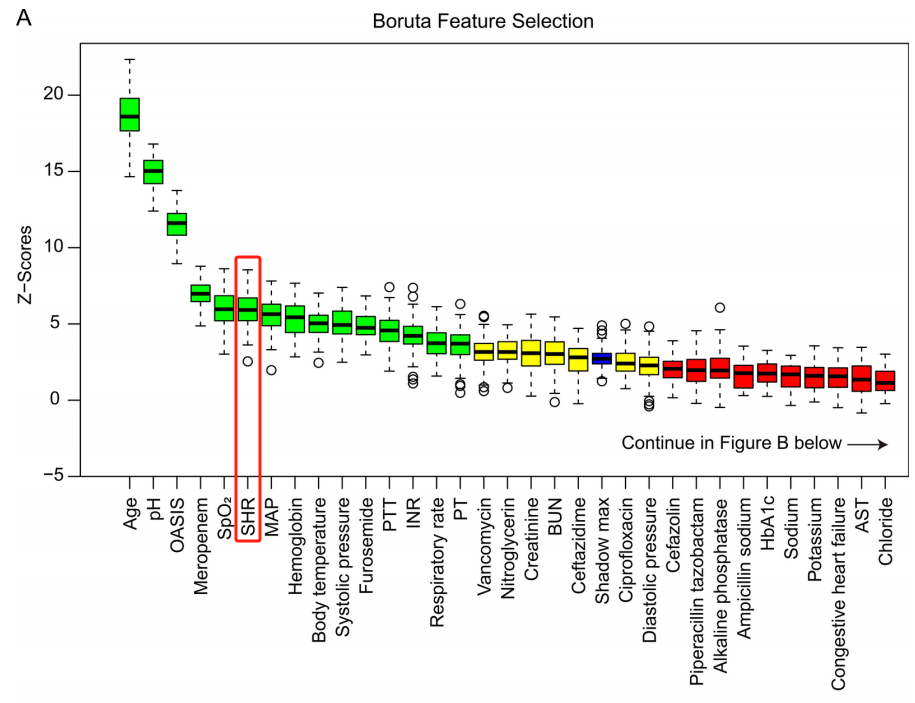
图5 Boruta算法
绿色框表示重要变量,红色框表示不重要的变量,黄色框表示可能重要的变量
√数据处理
研究团队将从MIMIC-IV数据库收集的数据以7:3的比例随机分为训练集(n=640)和验证集(n=273)。
√模型构建和评估
团队通过四种机器学习算法预测患者的28天住院死亡率,包括Coxph 、K-最近邻算法(KNN)、朴素贝叶斯(Bayes)和神经网络算法。
同时,通过ROC曲线、决策曲线(DCA)和校准曲线评估模型的预测性能。结果表明,神经网络算法模型的预测性能最佳。
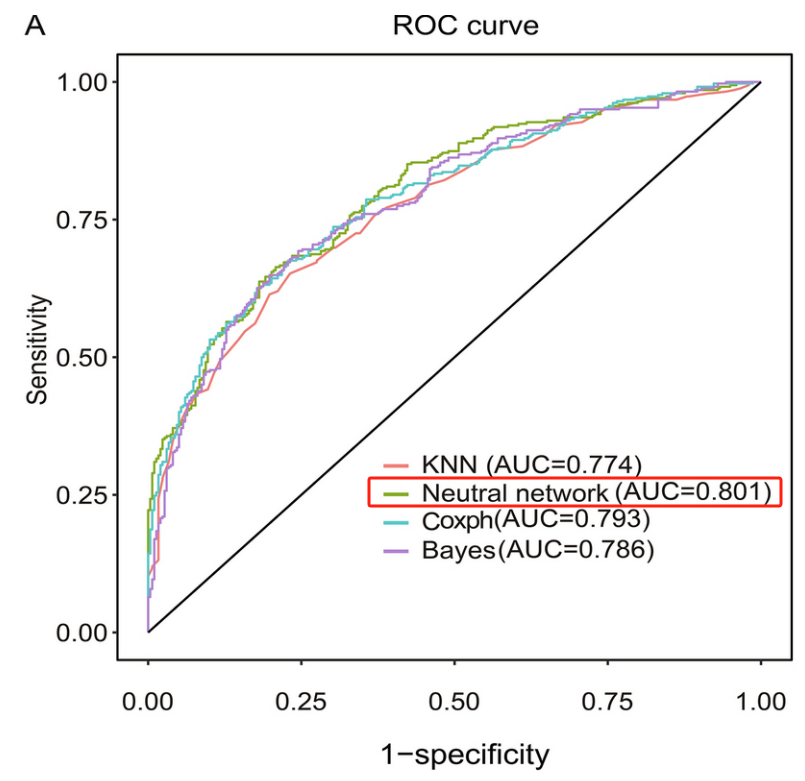
图6 机器学习模型的ROC曲线
综上所述,研究团队认为,对于先前患有慢性心力衰竭的ICU患者,SHR是预测其28天住院死亡率的独立因素,且其性能优于HbA1c和血糖。此外,在基于机器学习算法构建的预测模型中,神经网络算法预测性能最佳。
亮点小结
其实基于机器学习构建预测模型的套路非常类似,基本上都是数据收集、特征筛选、模型构建以及模型评估。
想要在常规思路上有所亮点,不如尝试本文用“森林之神”—Boruta算法筛选变量的思路,让研究的统计方法更加高级。
如果你想在其他公共数据库尝试,可以看看郑老师的NHANES和GBD一对一课程!数据库挖掘教学+文章复现+选题建议+R代码报错指导,从零到一,足以满足你的发文需求, 让你不再为SCI文章焦头烂额!
请关注“公共数据库与孟德尔随机化”公众号,今后我们也会分享更多公共数据库联合机器学习发高分的优秀文章,大家敬请期待!
关于郑老师团队及公众号
大型医学统计公众号平台,专注于医学生、医护工作者学术研究统计支持,我们是你们统计助理
郑老师团队开设的医学统计培训课程,各类发文需求都可以满足:
GBD公共数据库挖掘、NHANES公共数据库挖掘、孟德尔随机化方法
(目前购买统计课程还可参与发表SCI注明我们平台退课程费用的活动,详情扫描下方二维码添加助教微信咨询详情)
郑老师开发的超便捷免费统计工具了解一下:
www.medsta.cn/software(详情介绍)
详情联系助教小董咨询(微信号aq566665)


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)