深度学习--tensorflow 识别自己手写数字
model.add(Convolution2D(input_shape=(28, 28, 1), filters=32, kernel_size=5, strides=1, padding='same', activation='relu')) 注: 卷积层 对应: 输入数据 滤波器个数 卷积核个数 步长 数据填充(padding same) 激活函数。model.add(Flatten()) #
大体分两步 第一步训练cnn卷积神经网络 第二步识别自己手写数字(图像)
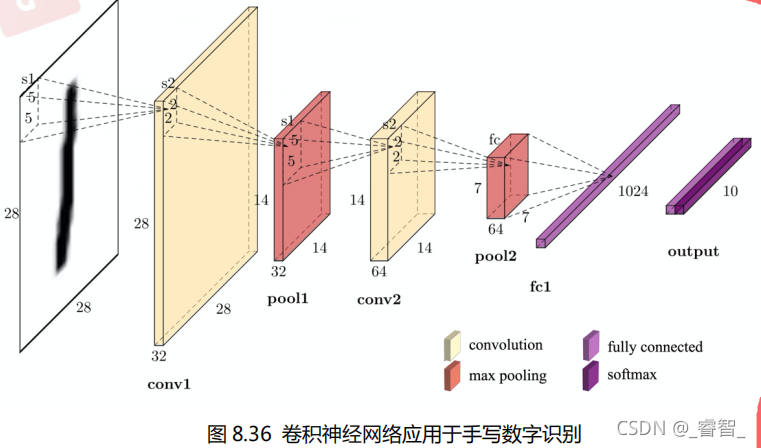
第一层:卷积层 第二层:卷积层 第三层:全连接层 第四层:输出层

一 训练CNN卷积神经网络
1. 用于载入数据
mnist = tf.keras.datasets.mnist (train_data, train_target), (test_data, test_target) = mnist.load_data()
#tf.keras.datasets模块是Tensorflow中Keras API的一部分,用来提供一些常见的公开数据集,数据集涵盖图像分类、自然语言处理多个领域,其中包括本项目所用到的MNIST手写数字图像数据集
调用load_data方法会返回两个元组,一个训练集,一个测试集。一个元组内分别对应数据和标签两部分。
2. 改变数据维度
train_data = train_data.reshape(-1, 28, 28, 1) test_data = test_data.reshape(-1, 28, 28, 1)
# reshape是NumPy数组的一个方法,在不改变数组数据的前提下,对数组的形状进行调整,其中-1自动计算样本数量 1图片通道数 MNIST数据集的图像都是灰度图 仅有一个通道
注:四个维度对应:数据数量 图片高度 图片宽度 图片通道数
3. 归一化用于提升速度
train_data = train_data / 255.0 test_data = test_data / 255.0
#原理:像素值一般是在0-255区间内,0表示黑色,255表示黑色,将像素值除以255.0能将范围归一化至0到1之间,作用可以提高模型的稳定性。
4. 独热编码用于将原始的整数类别标签转换为独热编码形式,以适应深度学习分类模型的训练需求
train_target = tf.keras.utils.to_categorical(train_target, num_classes=10) test_target = tf.keras.utils.to_categorical(test_target, num_classes=10)
#标签的值是0-9有10个,用Keras提供的方法将整数标签转换为独热编码向量
5. 搭建CNN卷积神经网络
model = Sequential()
#Sequential是一个类,用来构建顺序模型,这行代码作用是建了一个空的顺序模型,后续可以在这个模型中添加不同类型的层。
5-1 第一层:卷积层+池化层
model.add(Convolution2D(input_shape=(28, 28, 1), filters=32, kernel_size=5, strides=1, padding='same', activation='relu')) 注: model.add( )是往模型中添加一个新的层,Convolution2D表明添加的是二维卷积层,第一个参数是输入数据的形状 高28 * 宽28 *通道数1,第二个参数是滤波器的个数即不同卷积核的数量,第三个参数即卷积核的大小即卷积窗口的大小,第四个参数对应滑动步长,第五个参数表示在边界周围填充适当数量的0,第六个参数是指定该层使用激活函数。
model.add(MaxPooling2D(pool_size=2, strides=2, padding='same' )) 注: MaxPooling2D表示添加的是池化层
5-2 第二层: 卷积层+池化层
model.add(Convolution2D(64, 5, strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(2, 2, 'same'))
5-3 扁平化
model.add(Flatten()) #把(64, 7, 7, 64)数据变成: (64, 7*7*64) 64代表一次处理的样本数量 7 7 64分别代表 高 宽 通道数
#Flatten()层将来自卷积层输出的多维输入数据变为一维向量以便用于全连接层的输入,方便后续进行的矩阵乘法和进行非线性变换
5-4 第三层: 全连接层
model.add(Dense(1024, activation='relu')) # Dense 添加全连接层 1024表示全连接层的神经元数量 activation='relu'表示使用的激活函数是relu,其可以引入非线性因素,增强模型的表达能力。
5-5 第四层: 输出层
model.add(Dense(10, activation='softmax')) #此层为全连接层同样为输出层包含10个神经元,输出10个预测值 对应0-9的10个数字,使用softmax函数是将输入的数值转换为概率分布,在最后的分类决策当中,选择概率最大的类别作为最终的预测结果。
6 设置 (设置优化器 损失函数 标签)
model.compile(optimizer=Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
#对Keras模型进行编译,第一个参数是所用到Adam优化器(能够自适应地调整每个参数的学习率)
并且学习率是1×10−4 第二个参数是损失函数用于衡量模型预测结果与真是标签之间的差异,目标是最小化损失函数的值,其中categorical_crossentropy是适用于多分类问题的损失函数,第三个参数是评估指标用准确率体现。
7 训练
model.fit(train_data, train_target, batch_size=32, epochs=10, validation_data=(test_data, test_target)) #每组测32个小样本 进行10次测验,validation_data用于验证模型性能的数据集,及时去发现问题。
8 保存模型
model.save('mnist.h5')
Epoch 1/10
1875/1875 [==============================] - 11s 5ms/step - loss: 0.2528 - accuracy: 0.9248 - val_loss: 0.0666 - val_accuracy: 0.9780
Epoch 2/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0723 - accuracy: 0.9777 - val_loss: 0.0465 - val_accuracy: 0.9836
Epoch 3/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0516 - accuracy: 0.9841 - val_loss: 0.0323 - val_accuracy: 0.9891
Epoch 4/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0410 - accuracy: 0.9876 - val_loss: 0.0337 - val_accuracy: 0.9887
Epoch 5/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0336 - accuracy: 0.9898 - val_loss: 0.0239 - val_accuracy: 0.9922
Epoch 6/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0277 - accuracy: 0.9914 - val_loss: 0.0274 - val_accuracy: 0.9905
Epoch 7/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0238 - accuracy: 0.9919 - val_loss: 0.0233 - val_accuracy: 0.9922
Epoch 8/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0202 - accuracy: 0.9935 - val_loss: 0.0215 - val_accuracy: 0.9927
Epoch 9/10
1875/1875 [==============================] - 9s 5ms/step - loss: 0.0180 - accuracy: 0.9945 - val_loss: 0.0271 - val_accuracy: 0.9914
Epoch 10/10
1875/1875 [==============================] - 10s 5ms/step - loss: 0.0141 - accuracy: 0.9954 - val_loss: 0.0239 - val_accuracy: 0.9922
综上来看,训练10次基本可以达到%99的效果
二 识别自己的手写数字(图像)
1 载入数据
mnist = tf.keras.datasets.mnist #mnist成为一个数据加载器对象,借助它能加载MNIST数据集 (x_train, y_train), (x_test, y_test) = mnist.load_data() #加载的数据集分为训练集和测试集
2 载入训练好的模型
model = load_model('mnist.h5')
3 载入自己手写图片的地址并且设置大小
img = Image.open('C:\\Users\\Administrator\\Desktop\\3.png')
img = img.resize((28, 28)) #大小要和数据集中的图片保持一致

4 转灰度图
gray = np.array(img.convert('L')) #convert('L')转灰度 np.array( )将其转换为NumPy数组方便后续计算
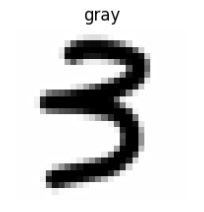
5 转黑底白字并数据归一化
gray_inv = (255 - gray) / 255.0 #255 - gray 进行的反色操作

6 转四维数据
image = gray_inv.reshape((1, 28, 28, 1)) #对 gray_inv 转变成四维数据来符合CNN的输入格式 #第一个1表示每次处理一个样本
7 预测
prediction = model.predict(image) # 预测
prediction = np.argmax(prediction, axis=1) #np.argmax( )是NumPy中的一个函数,用于返回数组中的最大值索引,括号中第一个参数是一个NumPy数组,通常表示深度学习的输出结果,axis = 0表示按列操作 axis = 1表示按行操作
print('预测结果:', prediction)
![]()
8 显示图像
# 设置plt图表
f, ax = plt.subplots(2, 2, figsize=(5, 5)) #plt.subplots用于创建一个包含多个子图的图形对象,f表示整个图形对象,ax代表子图对象数组,(2, 2)表示2行2列的子图布局,figsize=(5, 5)表示宽和高均为5英寸
# 显示数据集图像
ax[0][0].set_title('train_model')
ax[0][0].axis('off') #关闭第一行第一列子图的坐标显示,使得图像更加简洁
ax[0][0].imshow(x_train[800], 'gray') #x_train[800]表示取第800张训练图像 gray适合展示灰度图像
# 显示原图
ax[0][1].set_title('img')
ax[0][1].axis('off')
ax[0][1].imshow(img, 'gray')
# 显示灰度图(白底黑字)
ax[1][0].set_title('gray')
ax[1][0].axis('off')
ax[1][0].imshow(gray, 'gray')
# 显示灰度图(黑底白字)
ax[1][1].set_title(f'predict:{prediction}')
ax[1][1].axis('off')
ax[1][1].imshow(gray_inv, 'gray')
plt.show()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)