scitable包+sciml包手把手带你复现一篇8.5分charls机器学习文章
这是一篇去年的比较新的文章,我查了下大概8.5分,文章大概就是介绍一种指数,叫做:甘油三酯葡萄糖-腰身高比指数(cumulative_TyG_WHtR),研究甘油三酯葡萄糖-腰身高比指数和新发心血管疾病的关系,作者搞了个K值聚类分析来把cumulative_TyG_WHtR指数分类,研究分类后指标和心血管疾病关系,这样类似的指数还有很多,比如TYG,WHtR,TyG_WHtR,目前这是一个发文的方
本次复现一篇charls的文章名字《甘油三酯葡萄糖-腰身高比指数与中国中老年人心血管疾病的关系: 一项全国性队列研究》(Association between triglyceride glucose-waist height ratio index and cardiovascular disease in middle-aged and older Chinese individuals: a nationwide cohort study (CHARLS)),

这是一篇去年的比较新的文章,我查了下大概8.5分,文章大概就是介绍一种指数,叫做:甘油三酯葡萄糖-腰身高比指数(cumulative_TyG_WHtR),研究甘油三酯葡萄糖-腰身高比指数和新发心血管疾病的关系,作者搞了个K值聚类分析来把cumulative_TyG_WHtR指数分类,研究分类后指标和心血管疾病关系,
这样类似的指数还有很多,比如TYG,WHtR,TyG_WHtR,目前这是一个发文的方向,这样的指数,变一个结局变量,又可以继续搞一篇文章,很多类似文章层出不穷,nhanes也有很多,
比如下面这篇就是介绍甘油三酯葡萄糖-腰身高比指数和高血压病的关系,就是换了个结局,心血管换成高血压,方法几乎一模一样。

我在合集系列文章《R语言手把手带你复现一篇8.5分的charls机器学习文章》中已经介绍了,怎么手动制作图片,但是对于新手来说,还是相对有点麻烦的。目前我将文章中机器学习部分进行了整合,编写了sciml包(machine learning),大大降低了上手难度,加上scitable包,可以轻松复现上述文章。
sciml包目前只有scikmean这个函数,专门用于K均值聚类分析,后期看需要再增加一些其他机器学习内容。
下面我来演示一下,假设好你已经收集整理好了数据,准备分析,我先导入数据和R包
library(haven)
library(scitable)
library(sciml)
setwd("E:/公众号文章2025年/复现一篇8.5分机器学习的charls文章")
data<-read_dta('datafinal311.dta')
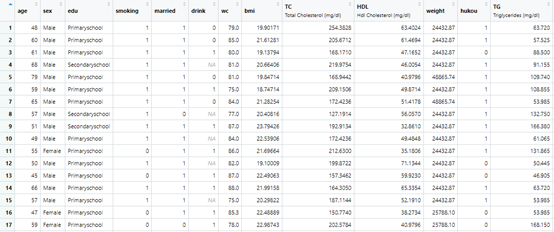
上图是我自己收集的数据,我就不对文章进行分析了,在文章《R语言手把手带你复现一篇8.5分的charls机器学习文章》我已经分析很多了,有兴趣的可以看下。
这里就直接开始做表了,其中cumulative_TyG_WHtR这个复合指数是文章研究的X,第一步咱们就是做出文章中的表一,基线表基线表就由有cumulative_TyG_WHtR和一些相关指标进行K值聚类分析,得到的分类人群作为基线分类指标。
有多人问怎么选K均值聚类的纳入指标,这里我说下,目前没有明确的标准,一般都是选和结局变量相关的指标,因为你要对人群进行分类嘛,目前我看见大部分都是选连续指标,如果你一定要选分类的,最好先转成哑变量矩阵。在这篇文章中,因为作者文章没有提到纳入了什么指标,我选了几个和结局相关的连续变量
names(data)
allvars<-c("wc","bmi", "TC", "HDL", "TG", "FBG", "LDL", "cumulative_TyG_WHtR")
指标选好后就可以开始进行K值聚类分析了,目前我们还不懂分层几类,可以像文章那样通过肘部法来选
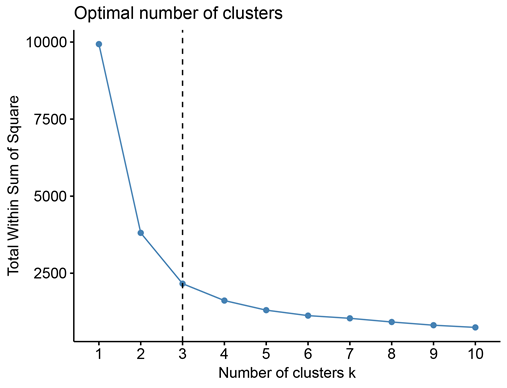
一般就是曲线突然变缓就是肘部,假设咱们不知道怎么选。可以先做一个这样的曲线
####不知道分类
out<-scikmean(data=data,allvars=allvars,username=username,token=token)
out
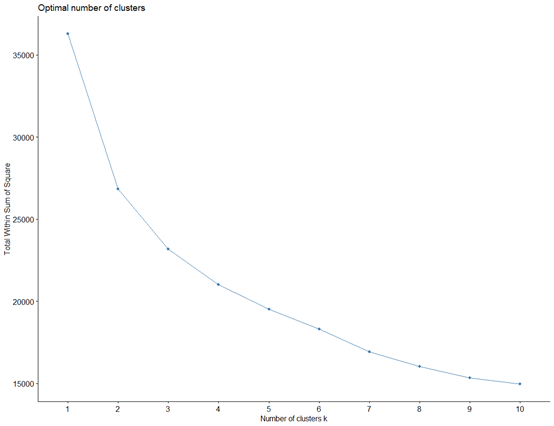
但是这样看有点难以区分几类,还可以选择自动投票,这个需要时间长一点,我这个电脑需要7分钟左右。
###自动投票
out<-scikmean(data=data,allvars=allvars,eclust=T)
dt<-out[["data"]]
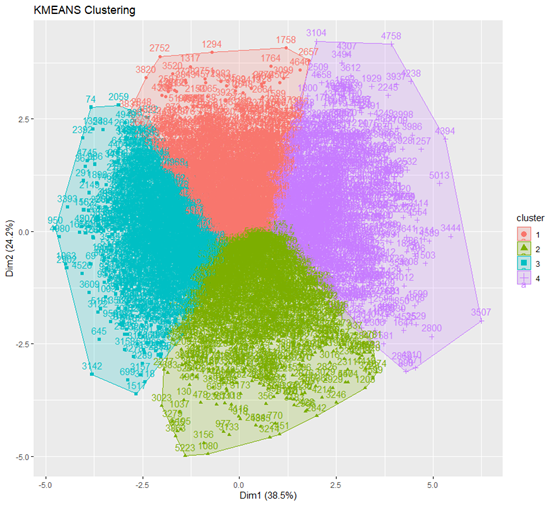
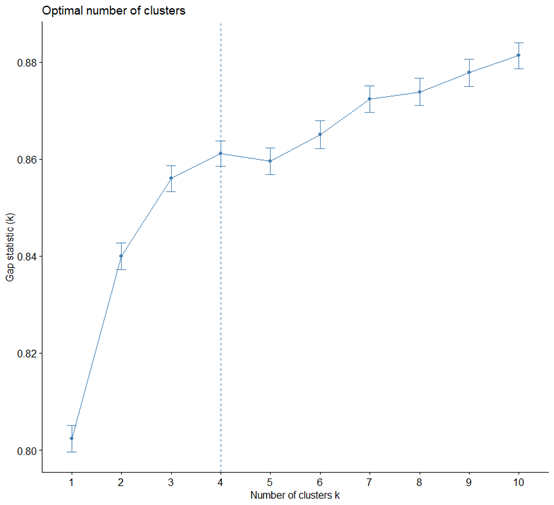
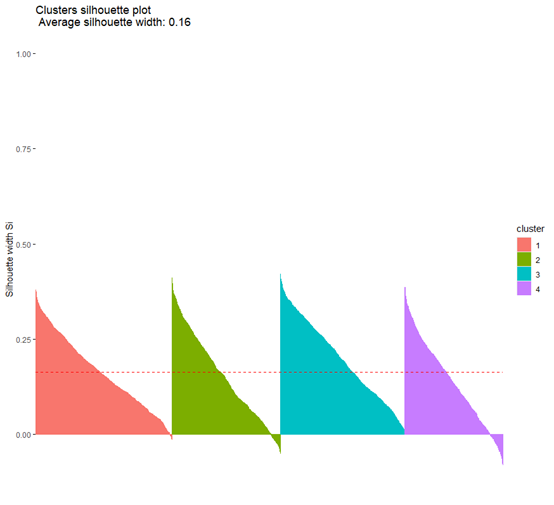
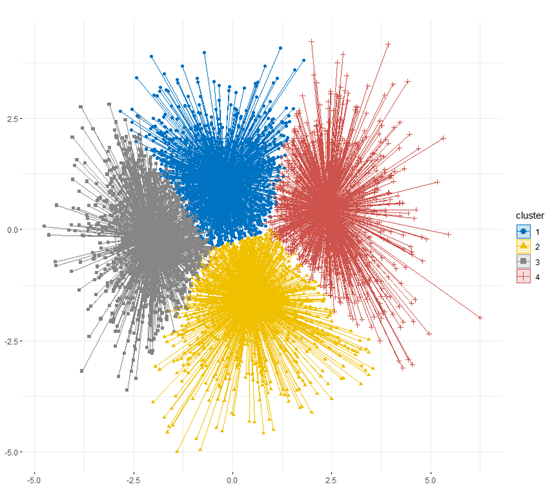
我们今天主要是复现文章,我们按作者的三类来跑
####有类别定义,默认删除法,正态分布和非正态分布去除方式不一样
out<-scikmean(data=data,allvars=allvars,nbclust = 3,username=username,token=token)
dt<-out[["data"]]
summary(dt)
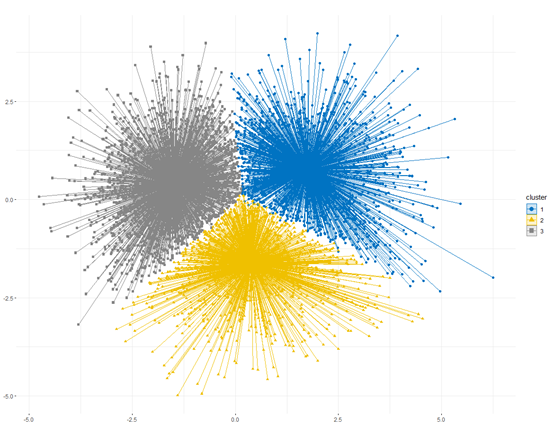
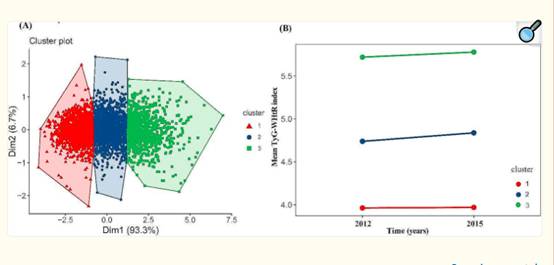
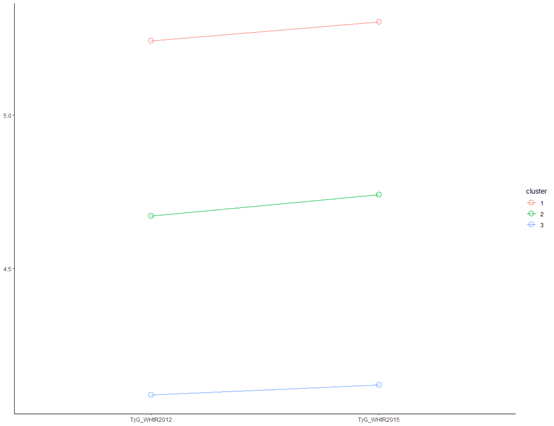
dt就是整理好的数据,咱们可以直接拿来用了,先做一个均值变化图
plotindchange(data=dt,x=c("TyG_WHtR2012","TyG_WHtR2015"),group = "cluster",plot = T)
接下来就是正式数据分析了,导入R包
library(scitable)
names(dt)
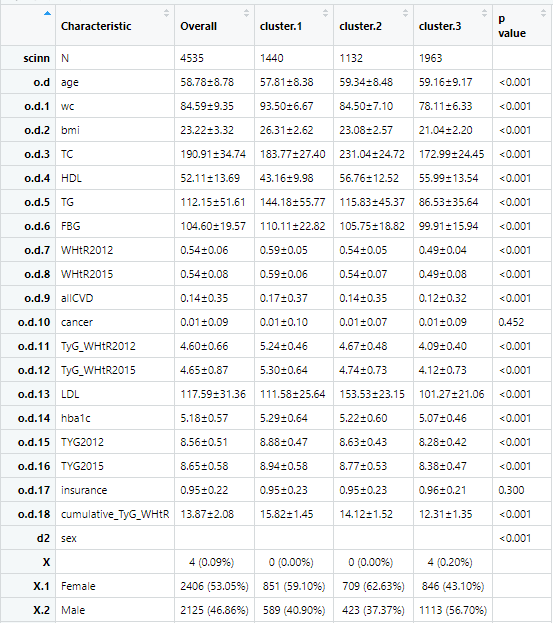
先做基线表,先对数据进行整理
out<-organizedata2(data = dt,username=username,token=token)
data<-out[["data"]]
定义所有变量,分类变量和分层变量
######表一
allVars <-c("age", "sex", "edu", "smoking", "married", "drink", "wc", "bmi",
"TC", "HDL", "hukou", "TG", "FBG", "WHtR2012", "WHtR2015",
"allCVD", "cancer", "TyG_WHtR2012", "TyG_WHtR2015",
"LDL", "hba1c", "TYG2012", "TYG2015", "Hypertension", "allHD", "allStroke",
"insurance","cumulative_TyG_WHtR")
fvars<-c("sex","edu","smoking","married", "drink","hukou","Hypertension", "allHD", "allStroke")
strata<-"cluster"
生成表格
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=dt,atotest=F,Overall=T)
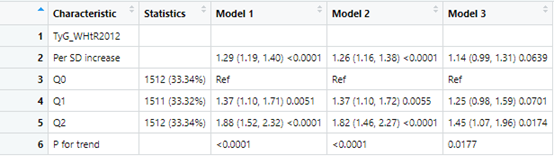
接下俩做表二,表二是两个表,主要是协变量不同
####表二
library(scitable)
cov2<-c("age","sex")
cov3<-c("age","sex","edu","bmi")
names(data)
out2<-scitb3a(data=data,x="TyG_WHtR2012",y="allCVD",cov2 = cov2,cov3=cov3,family = "glm",
username=username,token=token,num = 3)
out3<-scitb3a(data=data,x="cumulative_TyG_WHtR",y="allCVD",cov2 = cov2,cov3=cov3,family = "glm",
username=username,token=token)
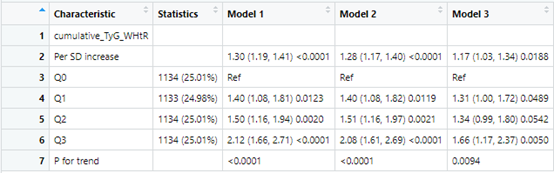
接下来就是RCS曲线,这里主要是观察变量不同
##############RCS
library(ggrcs)
library(rms)
library(ggplot2)
library(scales)
library(cowplot)
dd<-datadist(data)
options(datadist='dd')
str(data)
#dt<-convert_to_factor(data,fvars)
fit1<-lrm(allCVD~rcs(cumulative_TyG_WHtR,3),data=data)
ggrcs(data=data,fit=fit1,x="cumulative_TyG_WHtR")
singlercs(data=data,fit=fit1,x="cumulative_TyG_WHtR")
fit1<-lrm(allHD~rcs(cumulative_TyG_WHtR,3),data=data)
ggrcs(data=data,fit=fit1,x="cumulative_TyG_WHtR")
fit1<-lrm(allStroke~rcs(cumulative_TyG_WHtR,3),data=data)
ggrcs(data=data,fit=fit1,x="cumulative_TyG_WHtR")
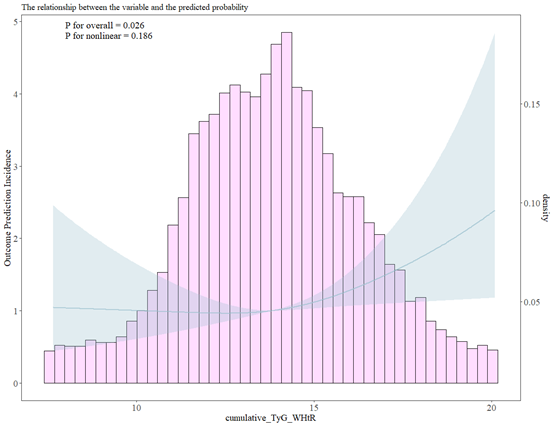
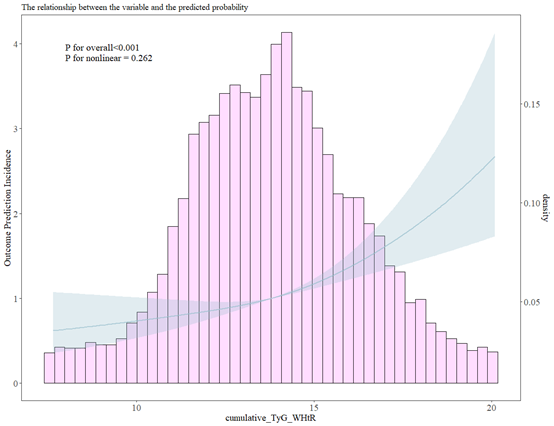
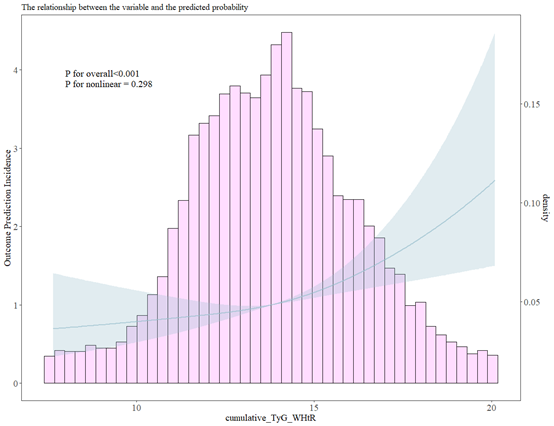
接下来是roc,这个按常规方法绘制就行
completedata <- data[complete.cases(data[, c("cumulative_TyG_WHtR", "WHtR2012", "TYG2012","age",
"sex","edu","bmi")]), ]
fit1<-glm(allCVD~cumulative_TyG_WHtR+age+sex+edu+bmi,family = binomial(link = "logit"),data=completedata)
fit2<-glm(allCVD~WHtR2012+age+sex+edu+bmi,family = binomial(link = "logit"),data=completedata)
fit3<-glm(allCVD~TYG2012+age+sex+edu+bmi,family = binomial(link = "logit"),data=completedata)
library(pROC)
roc1<- roc(completedata$allCVD, fit1[["linear.predictors"]])
roc2<- roc(completedata$allCVD, fit2[["linear.predictors"]])
roc3<- roc(completedata$allCVD, fit3[["linear.predictors"]])
plot(roc1,col="red",legacy.axes=T)
plot(roc2, add=TRUE, col="blue")
plot(roc3, add=TRUE, col="green")
legend("bottomright", legend=c("cumulative_TyG_WHtR","WHtR2012","TYG2012"),
col=c("red","blue","green"),lty=1,cex = 0.5)
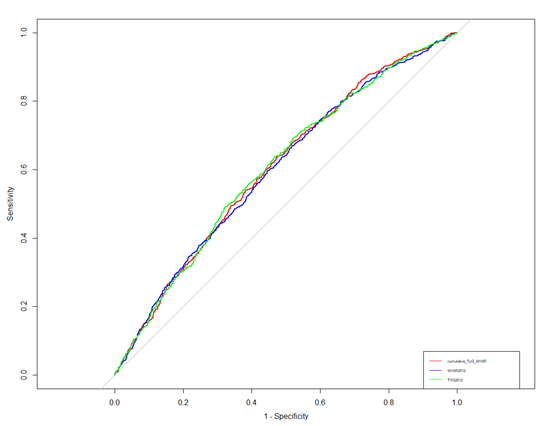
接下来做亚组分析,
处理分类变量
data$edu[data$edu == ""] <- NA
data$edu <- ifelse(data$edu == "Higher", 1,
ifelse(data$edu == "Primaryschool", 2,
ifelse(data$edu== "Secondaryschool", 3, NA)))
data$edu<-as.factor(data$edu)
####
data$sex<-ifelse(data$sex=="Female",1,ifelse(data$sex=="Male",2,NA))
data$sex<-as.factor(data$sex)
亚组分析,先做第一个
cov3<-cov3
Interaction<-c("sex","edu","smoking","married", "drink","hukou","Hypertension")
tb5.b<-scitb5b(data=data,x="cluster",y="allCVD",Interaction=Interaction,cov = cov3,family="glm",
username=username,token=token)
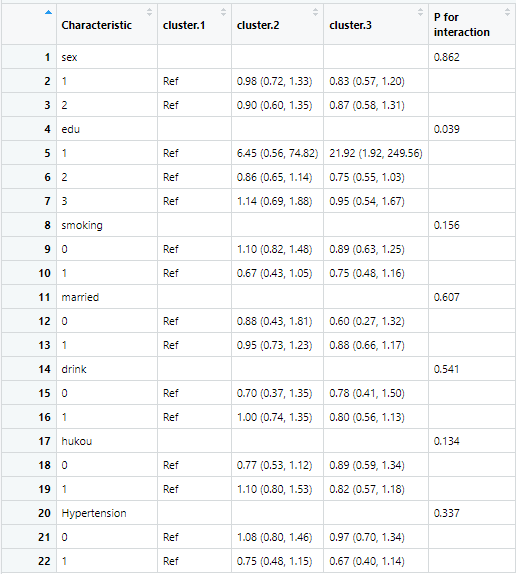
第二个
tb5.b2<-scitb5b(data=data,x="cumulative_TyG_WHtR",y="allCVD",Interaction=Interaction,cov = cov3,family="glm",
username=username,token=token)
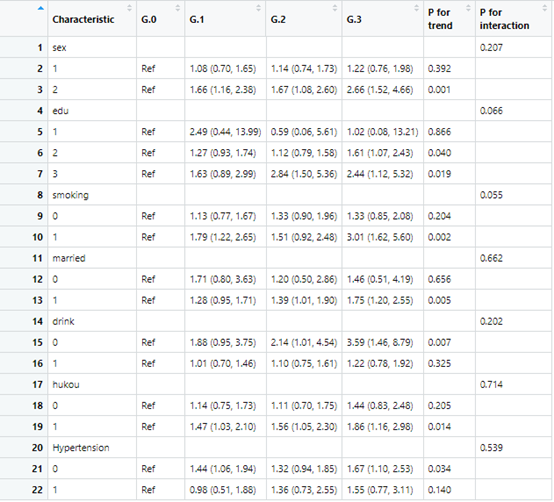
这样文章所有的图表都做出来了,非常快也非常简单把。文字介绍得有点快,详细得可以看下视频
scitable包+sciml包手把手带你复现一篇8.5分charls机器学习文章

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 25
25 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)