使用一个简单的神经网络实现路透社新闻数据集reuters数据分类
简单认识路透社数据集reuters-CSDN博客。
1 认识数据和业务
简单认识路透社数据集reuters-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/144958816我们好可以去实际调用以下去看一下数据到底是什么样子:
https://blog.csdn.net/weixin_65259109/article/details/144958816我们好可以去实际调用以下去看一下数据到底是什么样子:
from tensorflow.keras.datasets import reuters
(train_data,train_labels),(test_data,test_labels) = reuters.load_data(num_words=10000)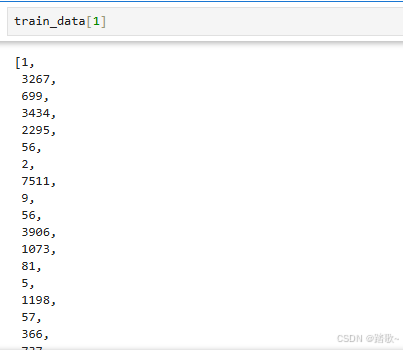
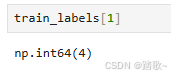

我也可以去看这个第二个列表到底代表什么文字:
word_index = reuters.get_word_index()
reverse_word_index = dict(
(value,key) for (key,value) in word_index.items()
)
decoded_review_train_data0 = ' '.join(
reverse_word_index.get(i-3,'?') for i in train_data[1]
)
2 数据准备
这一部分是为了将自己想要分析的数据转化为神经网络能够输入的格式。这个格式是张量。
2.1 导入数据
from tensorflow.keras.datasets import reuters
(train_data,train_labels),(test_data,test_labels) = reuters.load_data(num_words=10000)2.2 变换数据形状
2.2.1 改变输入特征的形状
每个样本的数据结构是列表,列表的长度不一,因为文本长度不一样。我的目标是这么多列表转化为张量。
方法有两种,请参考:
使用一个简单的神经网络实现IMDB影评数据分类-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/144949049我采用第二种multi-hot编码,使得列表能够转化为张量。
https://blog.csdn.net/weixin_65259109/article/details/144949049我采用第二种multi-hot编码,使得列表能够转化为张量。
def vectorize_sequences(sequences,dimension=10000):#我的词表的长度是10000
results = np.zeros(shape=(sequences,dimension))#这里生成的是张量,形状是(sequences,dimension),dimension是一个dimension列的一维列表
for i, sequence in enumerate(sequences):#enumerate函数将传入的sequences前面再加上了一个传入序号形成了一个对应的元组:(i,sequence),i代表句子序号,sequence代表这个句子的词列表
for j in sequence:#对于每个词的索引位置,将results的每一行的对应位置的词的的0变为1
results[i,j] = 1#i代表样本序号,j代表词索引位置
return resultsx_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
2.2.2 改变标签的形状
如果是二分类问题,那么没有必要进行形状的改变。因为是有限的数字,因为是有限的所以不用改变。二分类问题只设置一个区间,两个分类对应两端,接近哪个就判断为哪个。但是多分类这样的思维模型就不再适用。为此有两种主流的方法解决:
1、可以将标签转化为整数张量
2、可以使用one-hot编码
这里使用one-hot编码。其原理是构建一个列表,其索引对应着所有要分的类。对于每个样本,把其属于的类设置为1即可,其余都是0。把所有样本拼接起来就是一个one-hot矩阵。其是一个稀疏矩阵。
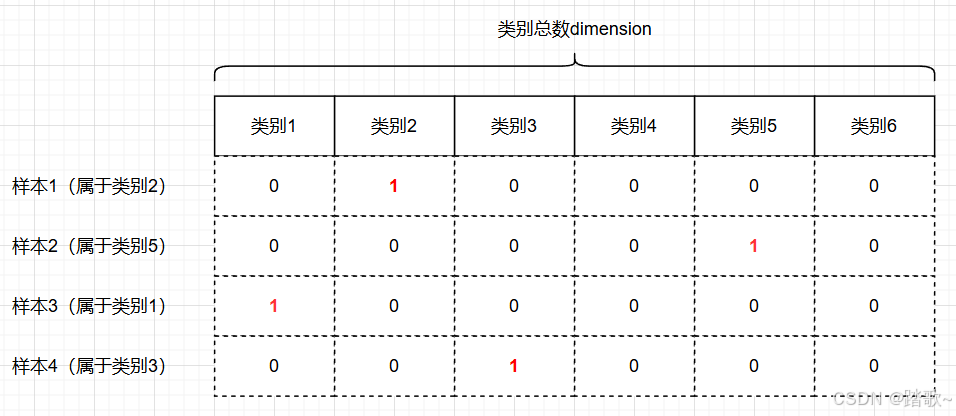
def to_one_hot(labels,dimension=46):#labels是每个元素存储着对应样本的数字类别
results = np.zeros(shape=(len(labels),dimension))
for i,label in enumerate(labels):#生成(索引,labels对应的元素)这么一个元组
results[i,label] = 1#更新这个位置,i对应应该是哪个样本,label对应这个样本应该是哪个类别
return resultsy_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
实际上,多分类问题非常常见。为此keras内置了这个方法:
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)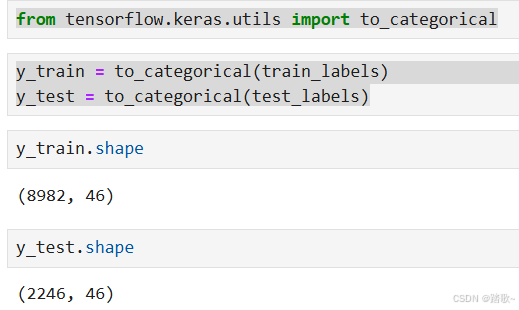
我后面使用的是内置方法。
3 构建模型
3.1 构建层和模型结构
选择的原则后面发出的博客可能会提及。这里输入的维度和输出的维度相较于IMDB二分类问题大很多,而神经网络中经过每一层都会筛选掉信息,并且筛选掉的信息是不可复原的。所以,要将层的自由度设置的大一点。最后一层是输出层,划分46个类别,所以要用softmax激活函数。对于每个样本,其会输出在46类上的概率。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64,activation="relu"),
layers.Dense(64,activation="relu"),
layers.Dense(46,activation="softmax"),
])3.2 编译模型
包括损失函数、优化器、监测指标。
损失函数:由于是多分类问题,所以采用categorial_crossentropy
优化器:没有特殊情况就选rmsprop
监测指标:现在只选择accuracy(传入的是一个列表)
model.compile(
optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['accuracy']
)4 训练模型调整参数
4.1 准备验证集
将验证集在训练集当中划分开,用于调整训练参数epochs。
x_val = x_train[:1000]#用于评估参数
partial_x_train = x_train[1000:]#剩下的用于训练
y_val = y_train[:1000]
partial_y_train = y_train[1000:]4.2 正式训练
包括训练特征、训练标签、训练轮数、批量、验证集
history = model.fit(
partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val)
)5 重新训练模型
5.1 观察模拟训练的结果
history这个变量是有一个history函数的,返回一个保存了模型训练过程的字典。

5.1.1 观察训练和验证的损失值变化
history_dict = history.history#引入字典
#先定义纵坐标再定义横坐标,可以使用做那个坐标列表的长度来定义横坐标
loss_values = history_dict['loss']#定义纵坐标1从字典中获得之
val_loss_values = history_dict['val_loss']#定义纵坐标2从字典中获得之
epochs = range(1,len(loss_values)+1)#定义横坐标
plt.plot(epochs,loss_values,'bo',label="Training loss")#'bo'表示蓝色圆点
plt.plot(epochs,val_loss_values,'r',label="Validation loss")#'r'表示红色实线
plt.title("Training loss & Validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()#用于在绘图中添加图例
plt.show()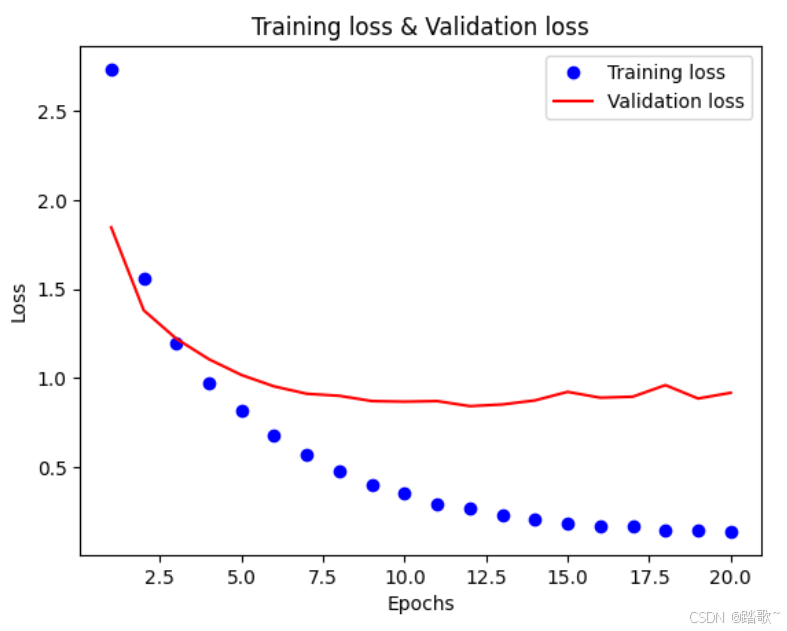
5.1.2 观察训练和验证的精度变化
plt.clf()#用于清空图像
#先定义纵坐标再定义横坐标,可以使用做那个坐标列表的长度来定义横坐标
acc = history_dict['accuracy']#定义纵坐标1从字典中获得之
val_acc = history_dict['val_accuracy']#定义纵坐标2从字典中获得之
epochs = range(1,len(acc)+1)#定义横坐标
plt.plot(epochs,acc,'bo',label="Training acc")#'bo'表示蓝色圆点
plt.plot(epochs,val_acc,'r',label="Validation acc")#'r'表示红色实线
plt.title("Training acc & Validation acc")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()#用于在绘图中添加图例
plt.show()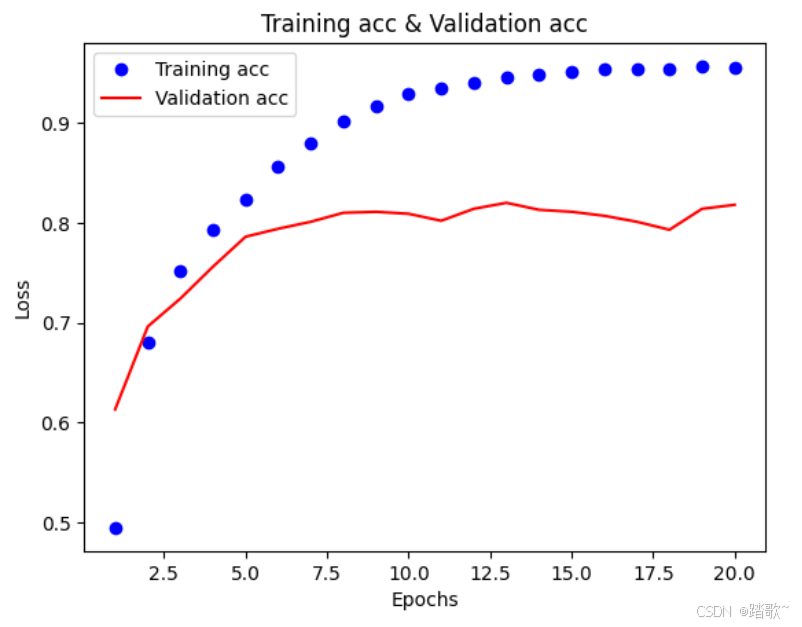
5.2 确定最佳epochs重新训练
从两张图可以看出在9轮训练之后损失值和精度趋于稳定,并且训练和验证的差距变得稳定,所以在9轮左右训练之后模型开始呈现出明显的过拟合。也就是说在9轮训练之后再多的训练变得没有意义。所以epochs设置为9。
重新训练:
model = keras.Sequential([
layers.Dense(64,activation="relu"),
layers.Dense(64,activation="relu"),
layers.Dense(46,activation="softmax"),
])
model.compile(
optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['accuracy']
)
model.fit(
x_train,#这里是所有的train
y_train,
epochs=9,
batch_size=512,
validation_data=(x_val,y_val)
)
5.3 评估模型
所有模型的评估都是使用测试集的数据。
5.3.1 自身评估的结果
result = model.evaluate(x_test,y_test)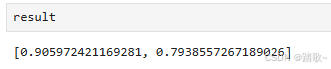
5.3.2 与其他模型进行比较
为凸显自己模型的优势,可以和随机划分分类和其他模型分类结果相比较发现自己模型的结果优势。
如果是随机分,拿二分类问题来举例,机器可以这样分,如果样本一半正例,一半负例,机器全是正,那么精度也能到达50%。但是,你训练的模型如果也是50%,那还不如机器这样分。
这里展现随机分类的分类精度是多少。
就是用测试集的标签随机打乱,然后和原来的标签列表对比,看有多少个相同的。
test_labels_copy = copy.copy(test_labels)#复制一份
np.random.shuffle(test_labels_copy)#将复制的打乱
hits_array = np.array(test_labels) == np.array(test_labels_copy)#先转换为元组,然后对比复制的和原先的,统计每一行是否相同
hits_array.mean()#统计为true的数量除以所有样本的数量,求平均值
可以得出随机分类精度在18%,而我们训练出的模型精度在80%。我们构建的模型是有效的。
6 推断
prediction = model.predict(x_test)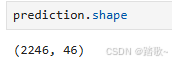
2246是测试集有2246个样本,46是代表其会返回46类判定为每类的概率。对于每个样本,其46列的概率和是1。
如果要是想得到最大概率的话,取概率最高的类别即可。
np.argmax(prediction[0])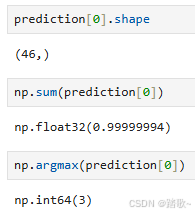
np.argmax是 NumPy 库中的一个函数,用于返回数组中最大值的索引。它可以用于多维数组,并且可以指定沿着哪个轴进行查找。以下是对np.argmax的详细介绍:函数签名
numpy.argmax(a, axis=None, out=None)参数说明
- a: 输入数组,可以是任意维度的 NumPy 数组。
- axis: 可选参数,指定沿着哪个轴查找最大值的索引。默认值为
None,表示查找整个数组的最大值索引。- out: 可选参数,指定输出数组。如果提供,结果将被放入该数组中。
返回值
返回一个整数或整数数组,表示最大值的索引。如果输入数组是多维的,返回的索引将根据指定的轴进行调整。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)