[深度学习] AutoDis --- KDD2021 连续特征的Embedding学习框架
论文名:An Embedding Learning Framework for Numerical Features in CTR Prediction开源代码:AutoDis1. 背景介绍在CTR预估模型中,大多数模型都遵守Embedding & Feature Interaction(FI)的范式。以往的大多数研究都聚焦于网络结构的设计,以更好的捕获显式或隐式的特征交互,如Wide&a
论文名:An Embedding Learning Framework for Numerical Features in CTR Prediction
开源代码:AutoDis
1. 背景介绍
在CTR预估模型中,大多数模型都遵守Embedding & Feature Interaction(FI)的范式。以往的大多数研究都聚焦于网络结构的设计,以更好的捕获显式或隐式的特征交互,如Wide&Deep的wide部分,DCN中的CrossNet, DeepFM的FM部分,DIN的注意力机制。然而却忽视了特征Embedding的重要性,尤其是忽视了连续型特征Embedding。
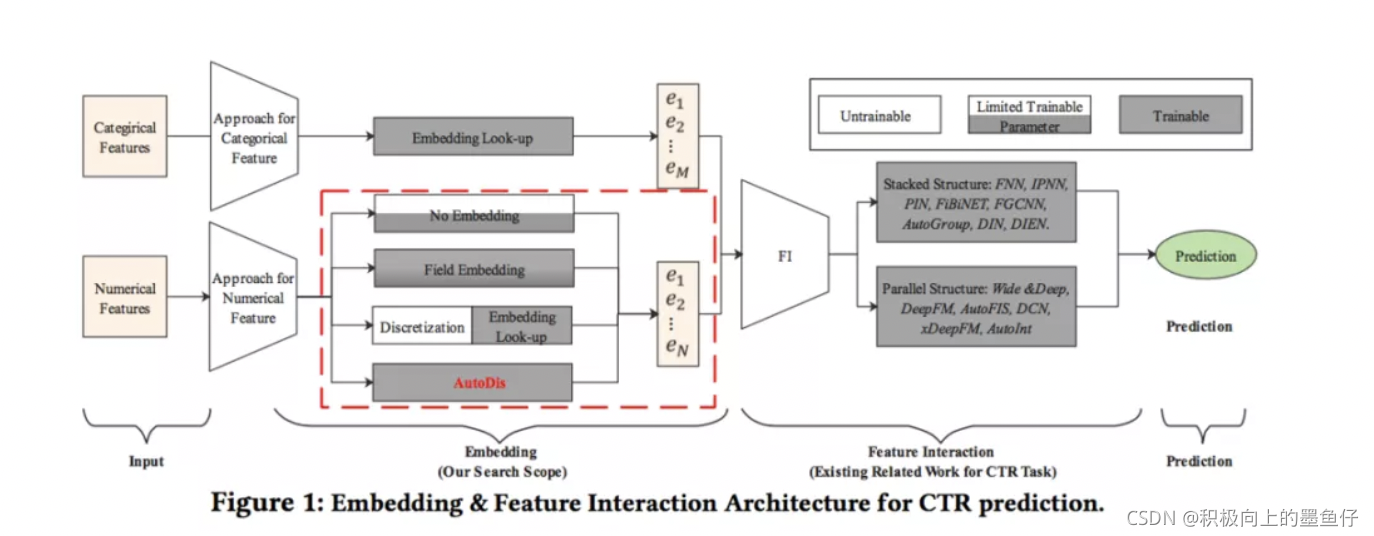
尽管很多文章中没有怎么研究,但Embedding模块是CTR预估模型的重要组成部分,有以下两个原因:
- Embedding模块是后续FI模块的基石,总结影响了FI模块的效果
- CTR模型的中大多数参数都在Embedding模块,所以很自然对模型效果有很大影响
但是Embedding模块少有深入研究的工作,特别是连续型特征Embedding的方面。
现有的处理方式由于其硬离散化(hard discretization)的方式,通常suffer from low model capacity。
接下来我将讲解Embedding模块的基本原理,以及CTR预估中数值特征的几种常见处理方式,然后对论文中所提出的AutoDis框架进行介绍。AutoDis框架具有high model capacity, end-to-end training, 以及unique representation.
2、连续特征处理
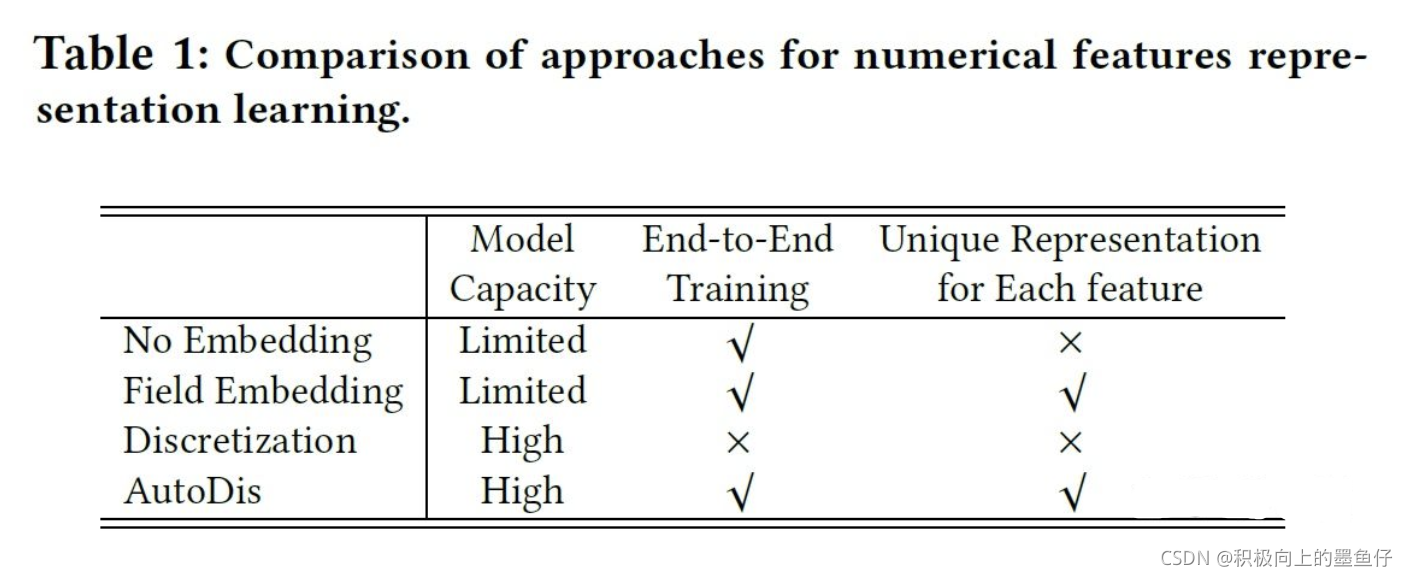
CTR预估模型的输入通常包含连续特征和离散特征两部分。对于离散特征,通常通过embedding look-up操作转换为对应的embedding (之后我会介绍谷歌对离散特征embedding的改进);而对于连续特征的处理,可以概括为三类:No Embedding, Field Embedding和Discretization(离散化)。


2.1 No Embedding
这类处理方法直接使用原始值或者转换后的值作为输入特征,没有学习Embedding。例如,Google发表的Wide & Deep模型,京东发表的DMT模型,分别使用了原始特征和归一化后特征。除此之外YouTube DNN使用了多种方法(平方,开根号等)对归一化特征进行转换
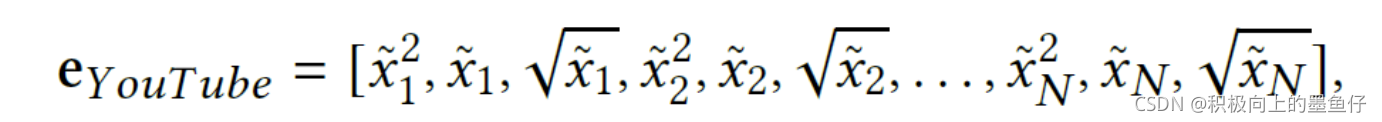
在Facebook发表的DLRM模型中,该模型使用了MLP(multi-lay perception)对所有连续型特征建模
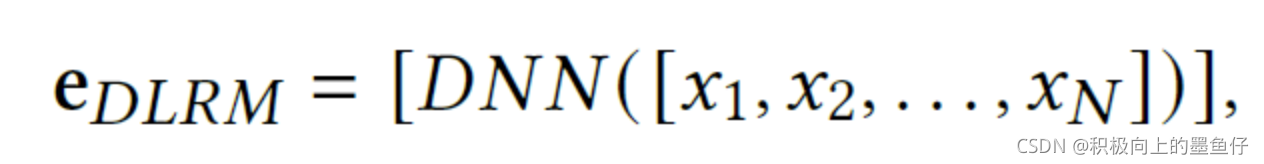
其中DNN的结构为 512--256--d, 这类对连续特征不进行embedding的方法,由于模型容量有限,通常难以有效捕获连续特征中信息。
2.2 Field Embedding
Field Embedding的处理方法为一个域中的所有特征中共享一个field embedding,计算时将field embedding乘以相应的特征值:
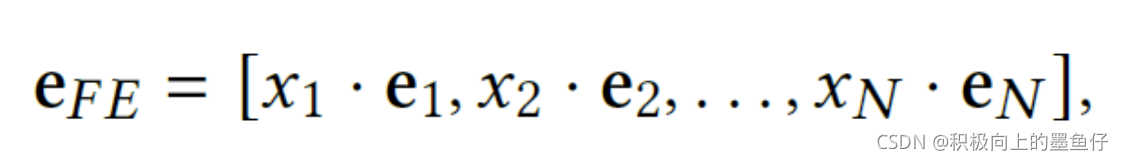
由于同一field的特征共享同一个embedding,并基于不同的取值对embedding进行缩放,这类方法的表达能力也是有限的。
2.3 Discretization
离散化(Discretization)方法将连续特征转换成类别特征。对于第j个数据域,其特征embedding可以使用两阶段(two-stage)方法获取:discretization(离散化) 和 embedding look-up(查表)
总的来说,将连续特征进行离散化给模型引入了非线性,能够提升模型表达能力,而对于离散化的方式,常用的有以下几种:
1) EDD/EFD (Equal Distance/Frequency Discretization):即等宽/等深分箱。

2)LD (Logarithm Discretization):对数离散化,其计算公式如下:
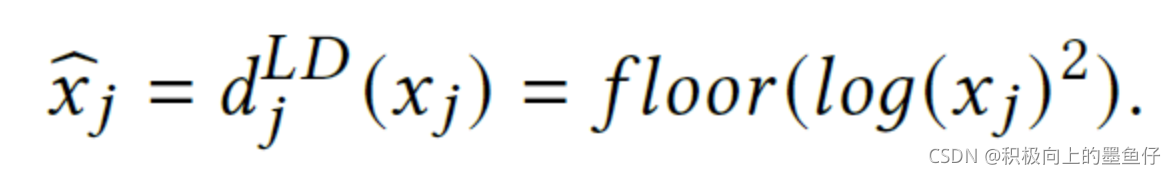
3)TD (Tree-based Discretization):基于树模型的离散化,如使用GBDT+LR来将连续特征分到不同的节点。这就完成了离散化。除深度学习模型外,树模型(例如GBDT)被广泛应用于推荐领域。其能高效的处理数值型特征。比如“Feature Selection with Decision Tree”、“Practical Lessons from Predicting Clicks on Ads at Facebook”、“Deep Learning Framework Distilled by GBDT for Online Prediction Tasks”使用了树模型对数值特征进行离散化。
2.4 当前离散化不足之处
尽管离散化在工业界广泛引用,但仍然有以下三方面的缺点:
1)TPP (Two-Phase Problem):将特征分桶的过程一般使用启发式的规则(如EDD、EFD)或者其他模型(如GBDT),无法与CTR模型进行一起优化,即无法做到端到端训练;
2)SBD (Similar value But Dis-similar embedding):对于边界值,两个相近的取值由于被分到了不同的桶中,导致其embedding可能相差很远;
3)DBS (Dis-similar value But Same embedding):对于同一个桶中的边界值,两边的取值可能相差很远,但由于在同一桶中,其对应的embedding是相同的。
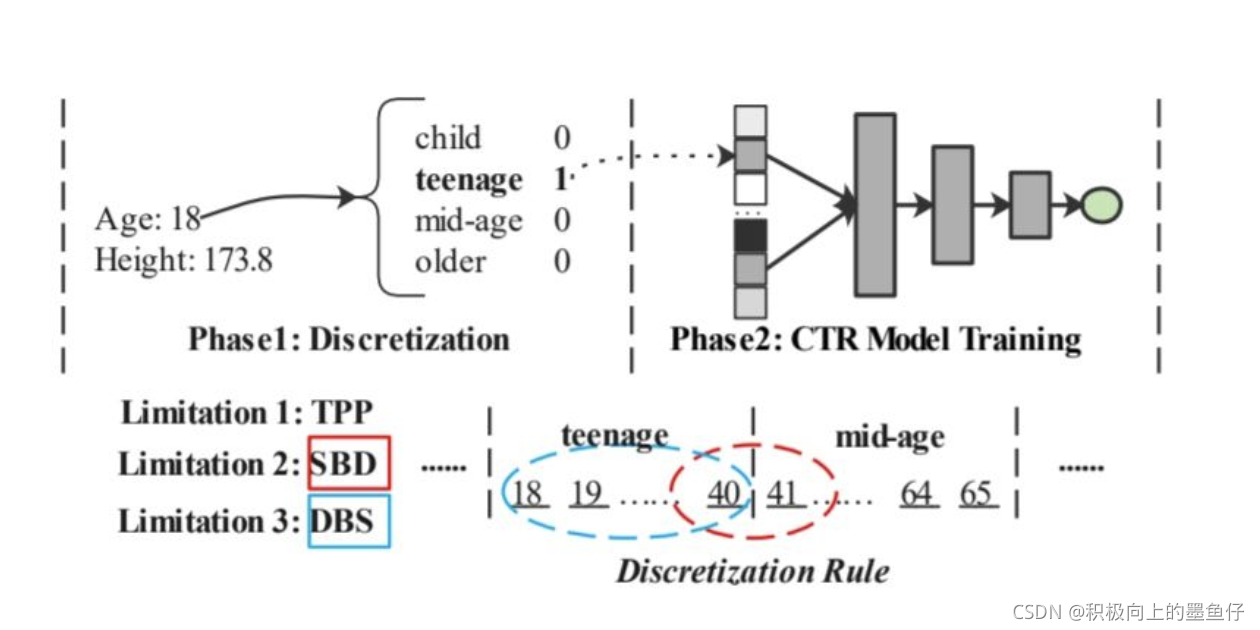
40和41岁没有多大区别,但是却有完全不同的embedding;DBS: 18和40岁差距甚远,但是embedding却一模一样!
表1为AutoDis和这三种方法的对比。可以看出这三种方法要么由于模型容量有限,通常难以有效捕获连续特征中信息,要么由于需要离线专门设计的特征工程,可能影响模型表现。因此,论文提出了AutoDis框架,它具有高模型容量,端到端的训练,每个特征独一的表示等优点。
3. AutoDis介绍
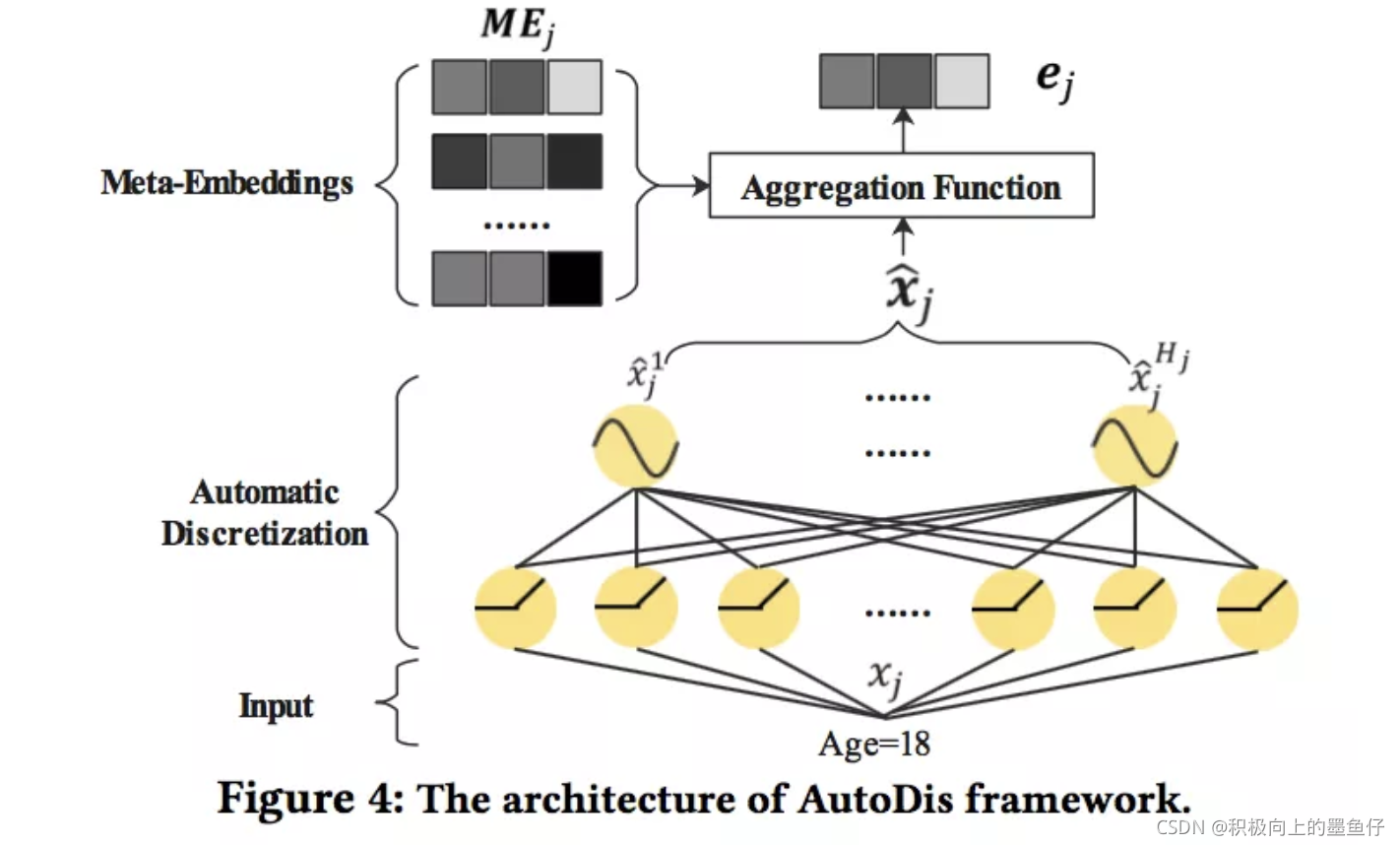
为了解决现有方法的不足之处,论文提出了AutoDis框架,其能学习为每个特征值学习独一的表示以端到端的方式训练。下图展示了AutoDis可以作为一个可插拔的Embedding框架,用于数值型特征处理,并且兼容现有的CTR预估模型。
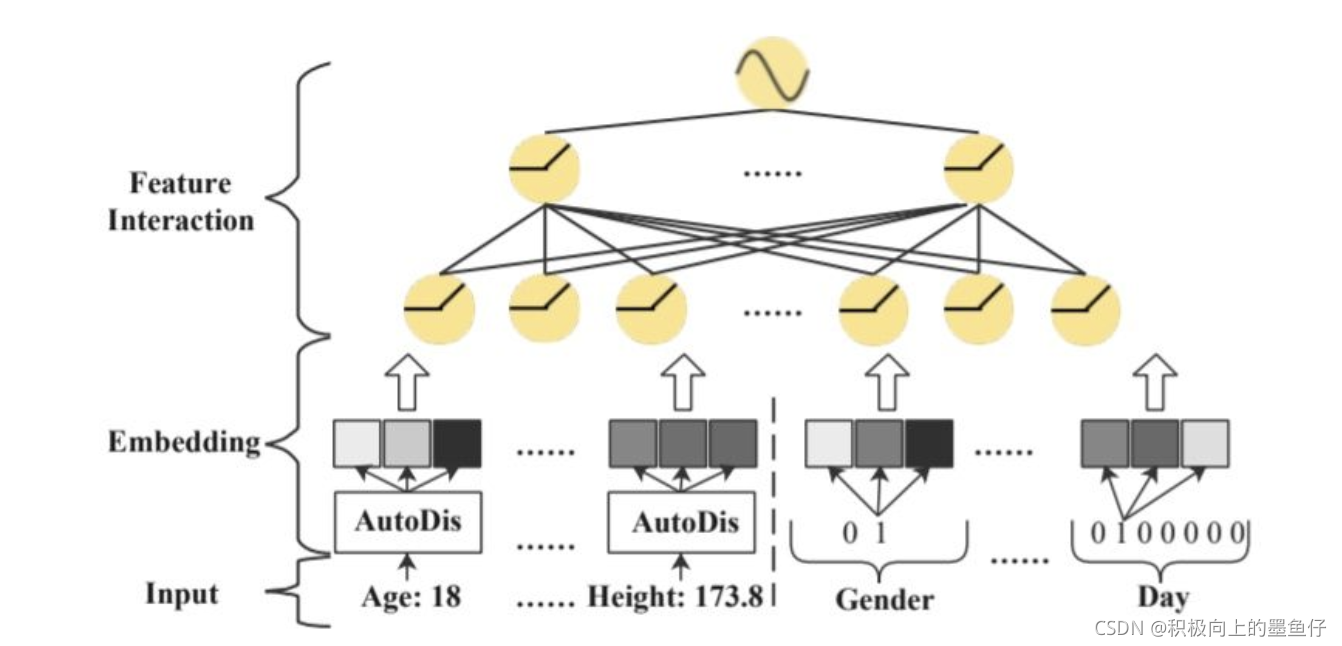
为了实现高模型容量、端到端训练,每个特征取值具有独立表示,AutoDis设计了三个核心的模块,分别是Meta-Embeddings、automatic Discretization和 Aggregation模块。
对于第j个特征域,AutoDis可以为每个特征值学习独一的表示:
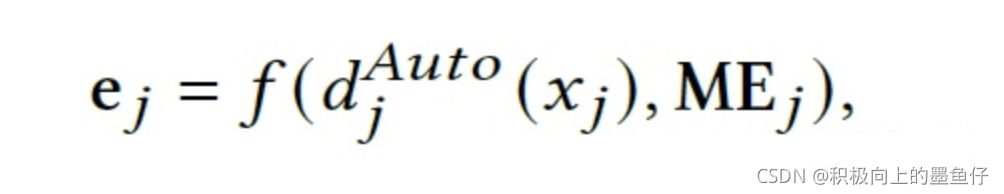

3.2 Meta-Embeddings
一种朴素的方法是将连续特征中的每个特征值赋予一个独一的embedding。但是这是不可行的,这将导致参数爆炸且对低频特征训练不足。Field Embedding对同一域内的特征赋予相同的embedding,尽管降低了参数数量,但模型容量也受到了一定的限制。为了平衡参数数量和模型容量,AutoDis设计了Meta-embeddings模块。
为了平衡参数数量和模型容量,AutoDis设计了Meta-embedding模块: 对于第 j 个连续特征,对应 个Meta-Embedding(可以看作是分 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/4fdb823ba55796e3d4095d72e380bf4b.png) 个桶,每一个桶对应一个embedding)。第j个特征的Meta-Embedding表示为:
个桶,每一个桶对应一个embedding)。第j个特征的Meta-Embedding表示为:
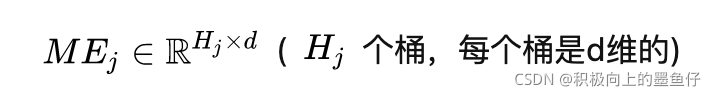
对于连续特征的一个具体取值,则是通过一定方式将这 Hj个embedding进行聚合。相较于Field Embedding这种每个field只对应一个embedding的方法,AutoDis中每一个field对应 Hj个embedding,提升了模型容量;同时,参数数量也可以通过 进行很好的控制。
3.3 Automatic Discretization
Automatic Discretization模块可以对连续特征进行自动的离散化,实现了离散化过程的端到端训练。具体来说,对于第j个连续特征的具体取值xj,首先通过两层神经网络进行转换,得到Hj长度的向量:

某种softmax变成概率分布:
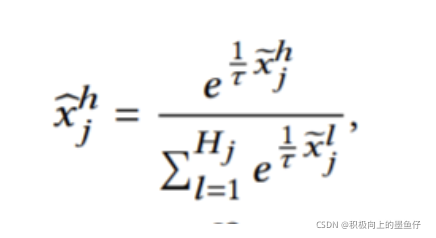
传统的离散化方式是将特征取值分到某一个具体的桶中,即对每个桶的概率进行argmax,但这是一种无法进行梯度回传的方式。而上式可以看作是一种soft discretization,通过调节温度系数𝜏,可以达到近似argmax的效果,同时也可以实现梯度回传,实现了离散化过程的端到端训练(这种方式也称为softargmax,最近工作中也经常使用)。
对于温度系数𝜏,当其接近于0时,得到的分桶概率分布接近于one-hot,当其接近于无穷时,得到的分桶概率分布近似于均匀分布。对于不同的连续特征,特征取值分布是不同的,那么应该如何对不同特征选择合适的温度系数𝜏呢?
3.3 Aggregation Function
根据前两个模块,已经得到了每个桶的embedding,以及某个特征取值对应分桶的probability distribution,接下来则是如何选择合适的Aggregation Function对二者进行聚合。论文提出了如下几种方案:
1)Max-Pooling:这种方式即hard selection的方式,选择概率最大的分桶对应的embedding。前面也提到,这种方式会遇到SBD和DBS的问题。
2)Top-K-Sum:将概率最大的K个分桶对应的embedding,进行sum-pooling。这种方式不能从根本上解决DBS的问题,同时得到的最终embedding也没有考虑到具体的概率取值。
3)Weighted-Average:根据每个分桶的概率对分桶embedding进行加权求和,这种方式确保了每个不同的特征取值都能有其对应的embedding表示。同时,相近的特征取值往往得到的分桶概率分布也是相近的,那么其得到的embedding也是相近的,可以有效解决SBD和DBS的问题。
所以,其实就是对 Hj个桶的embedding进行加权求和。
4、实验结果及分析
最后来看一下实验结果,离线和线上均取得了不错的提升
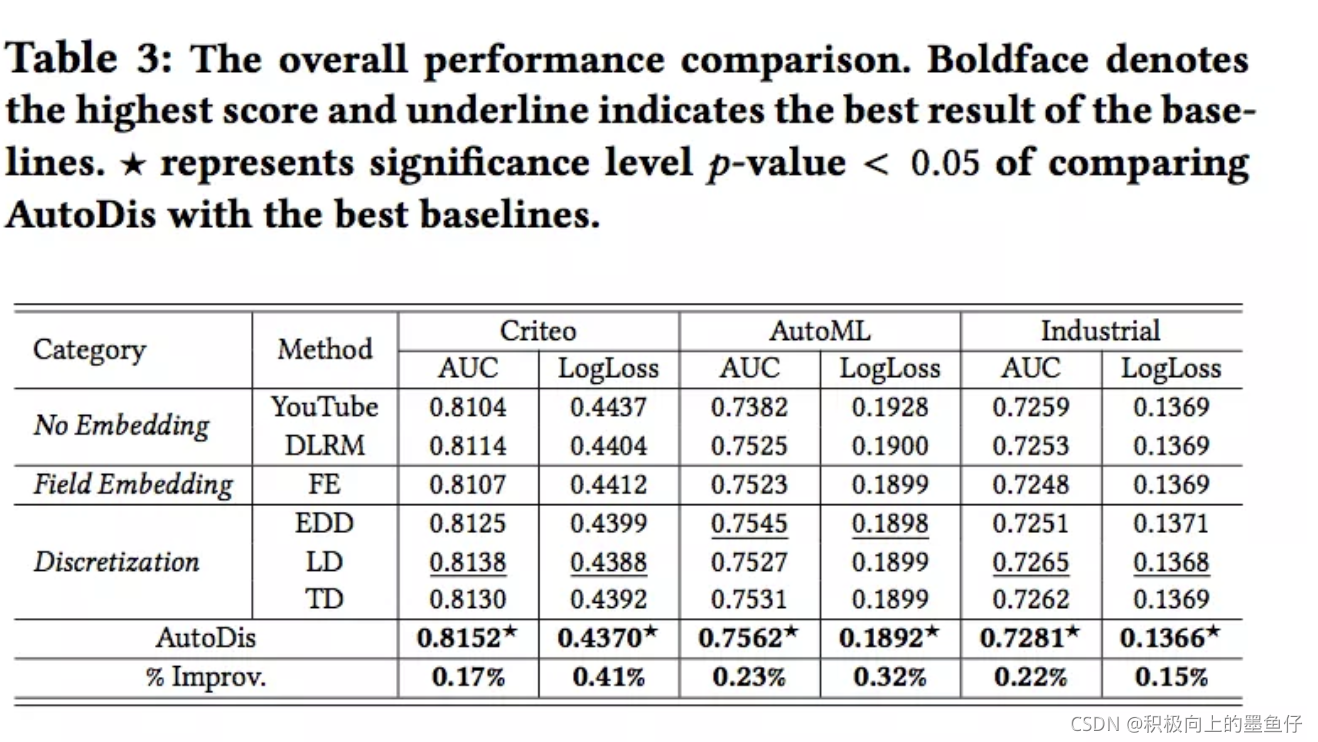
使用AutoDis和其他三种数值型特征处理方法进行对比,CTR预估模型使用DeepFM,结果如下表所示。
- AutoDis在所有数据集上表现最好。
- No Embedding和Field Embedding的表现差于Discretization和AutoDis。因为这两种方法由于低模型容量限制了表达能力。
- 相比于三种Discretization方法,AutoDis的AUC相对于基准分别提高了0.17%、0.23%和0.22%。尽管Discretization方法表现也很不错,但是其存在SBD和DBS问题。hard discretization会导致不平滑的embedding。相反AutoDis解决了这个问题。AutoDis使用一组meta-embedding以及可微的soft discretization和aggregation策略学习到了连续但不同(Continuous-But-Different)的表示。
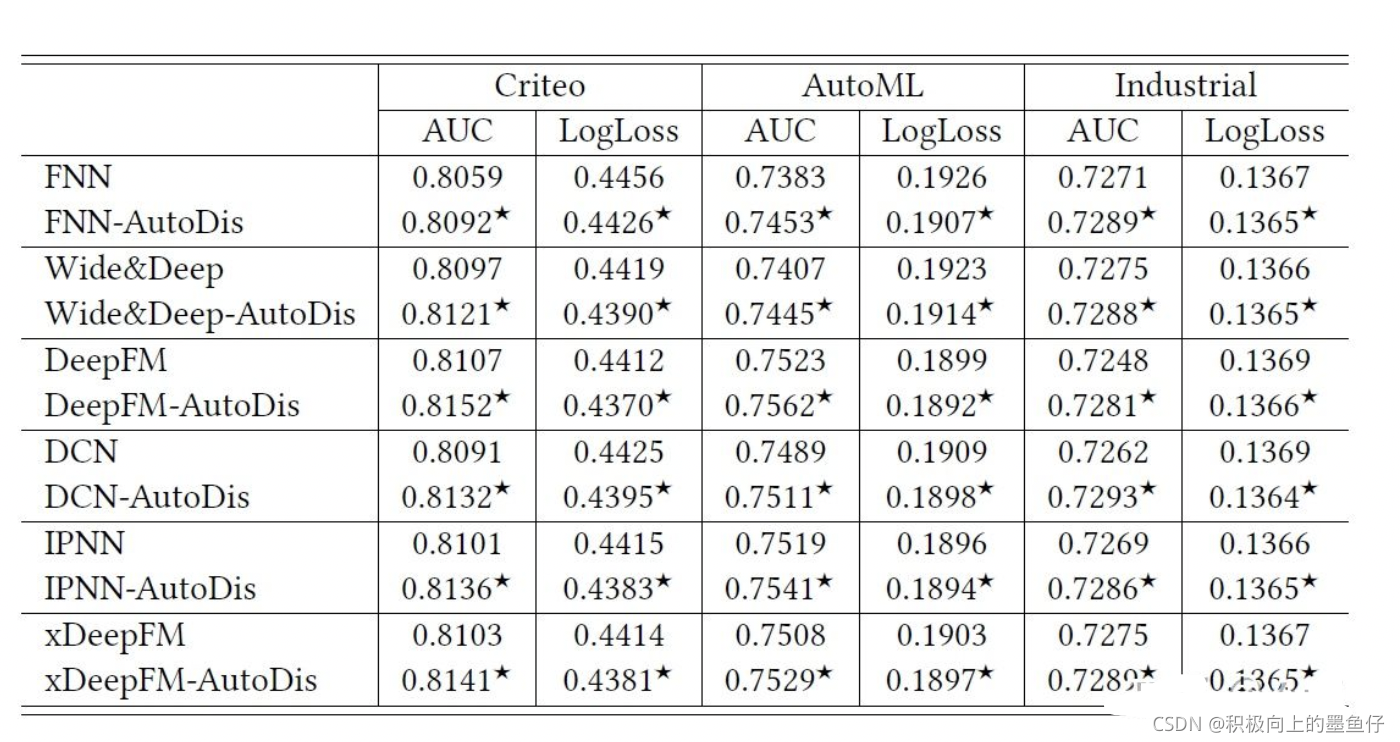
AutoDis框架兼容性
我们将AutoDis框架用于六种CTR预估模型中,测试AutoDis的兼容性。如下表所示,与Field Embedding方法相比,AutoDis显著的提升了这个模型的性能。数值型特征的离散化和embedding的学习过程与模型的最终目标协同训练。所有可以得到更好的表达,因此提升了模型性能。
Embedding分析
为了理解连续但不同(Continuous-But-Different)embedding。我们继续了宏观的embedding分析和微观的embedding分析。
宏观embedding分析:下图是Criteo数据集中第3个数值域特征的可视化,分别是DeepFM-AutoDis和DeepFM-EDD的embedding结果。我们随机选择了250个embedding,将其映射到2为空间(t-SNE算法)。图中颜色相似意味着特征值相近。我们可以看到AutoDis为每个特征值学习了一个独一的表示,同时相近的特征值有着相近的embedding表示(在二维空间中),体现出了Continusous-But-Different的特性。然而EDD对同一个桶中的特征值学习一个embedding,不同桶中的embedding完全不同,不平滑的embedding表现,导致其效果弱于EDD。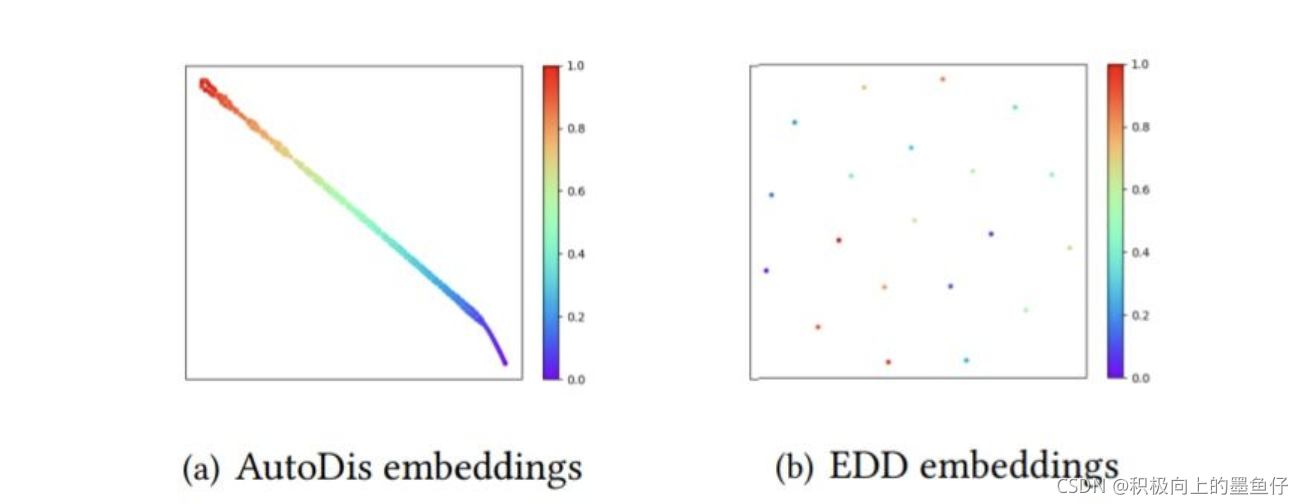
总结
本文,我们提出了AutoDis,一个CTR预估中可插入的用于数值特征的embedding学习框架。AutoDIs解决了现有方法的问题,并取得了更好的效果。其优势主要体现在3方面。
- 高模型容量:在一个特征域中meta-embeddings是共享的。
- 端到端的训练:一个可微的automatic discretization。所有AutoDis可以与CTR预估模型进行协同训练,同一个最终目标。
- 独一的表示:加权平均聚合保证了每个特征值可以学习到连续但不同(Continusous-But-Different)的表示。
KDD2021 | 华为AutoDis:连续特征的Embedding学习框架 - 知乎
 https://zhuanlan.zhihu.com/p/387941498
https://zhuanlan.zhihu.com/p/387941498
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)