【精选】基于Python的B站热门视频数据分析与研究(Hadoop+Hive+Spark)大数据处理、视频趋势分析与用户行为研究 数据挖掘、视频推荐趋势与用户互动分析 视频热度预测与用户参与分析
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围: 我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Js
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅

目录:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
承诺所有开发的项目,全程售后陪伴!!!

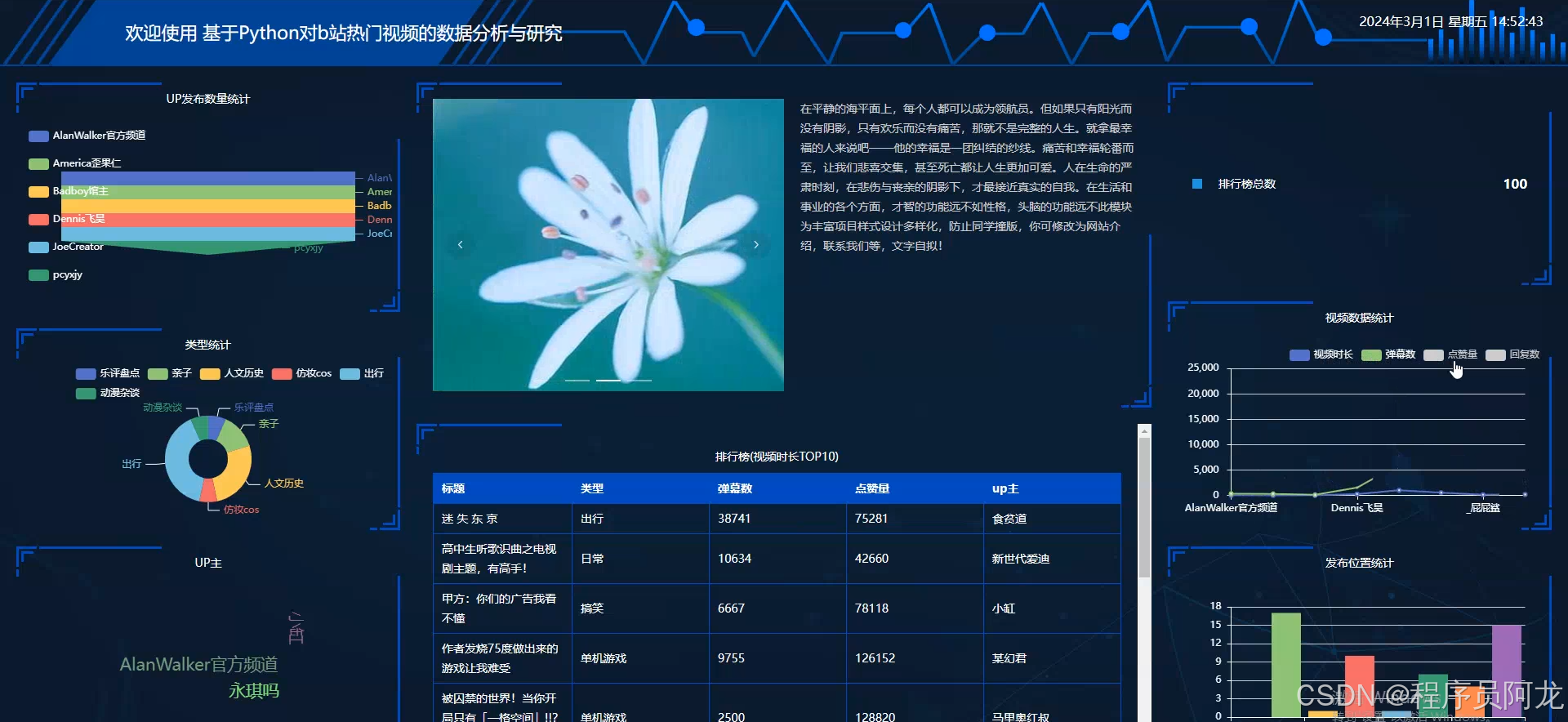
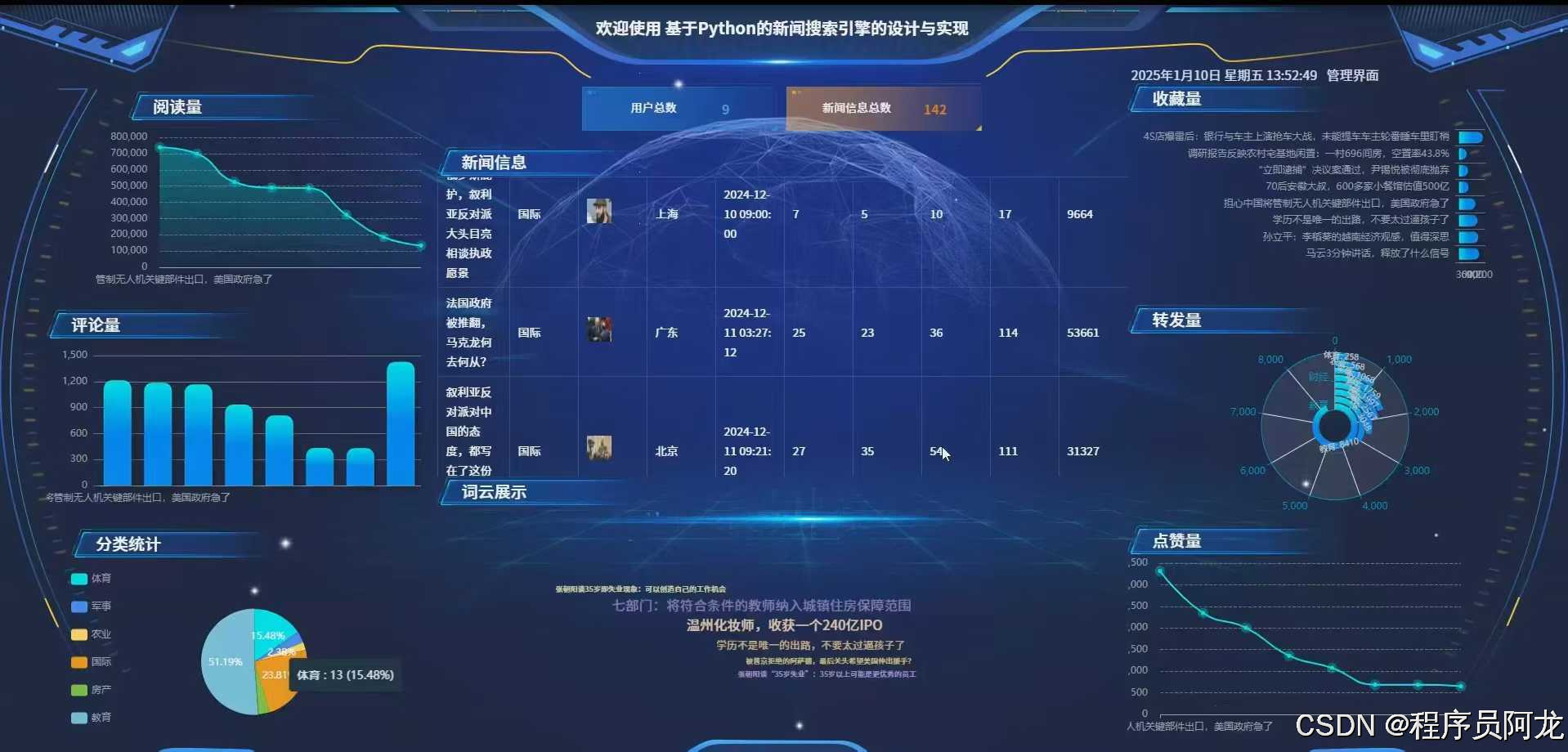
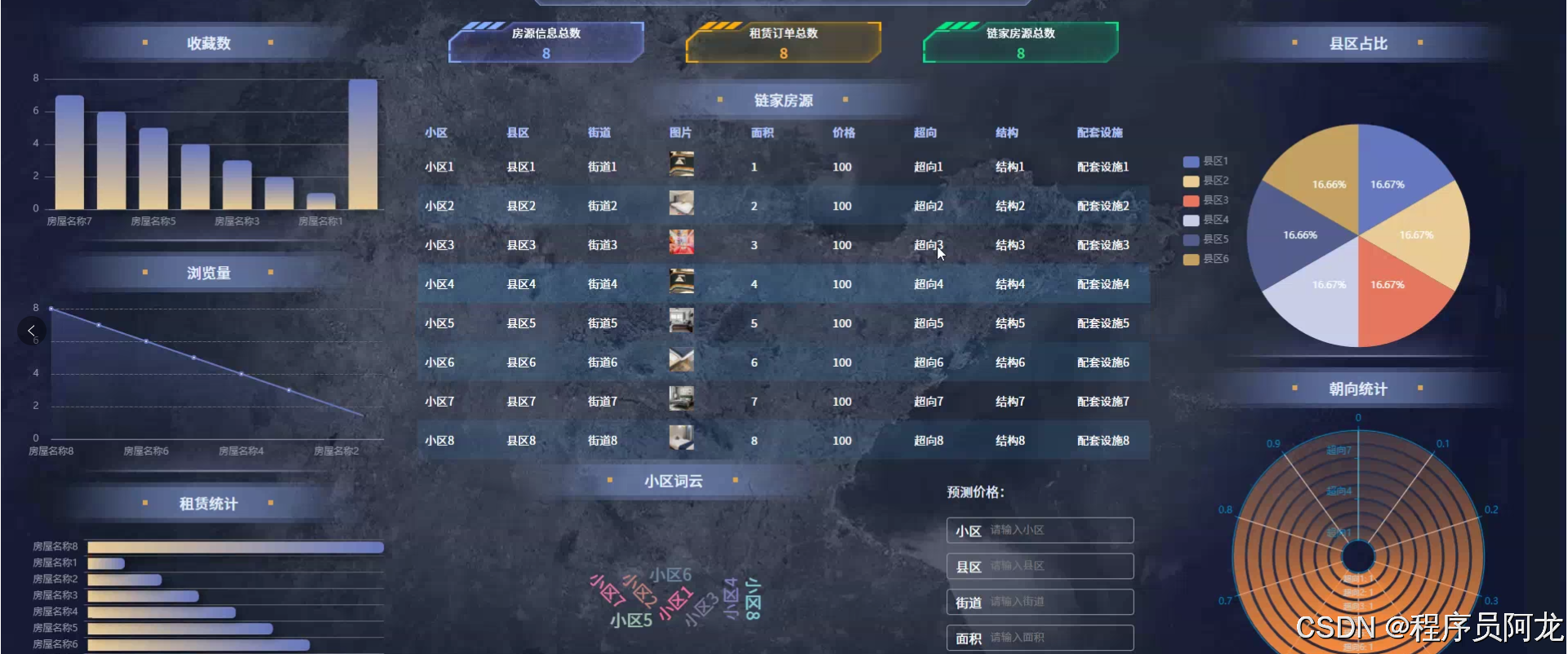
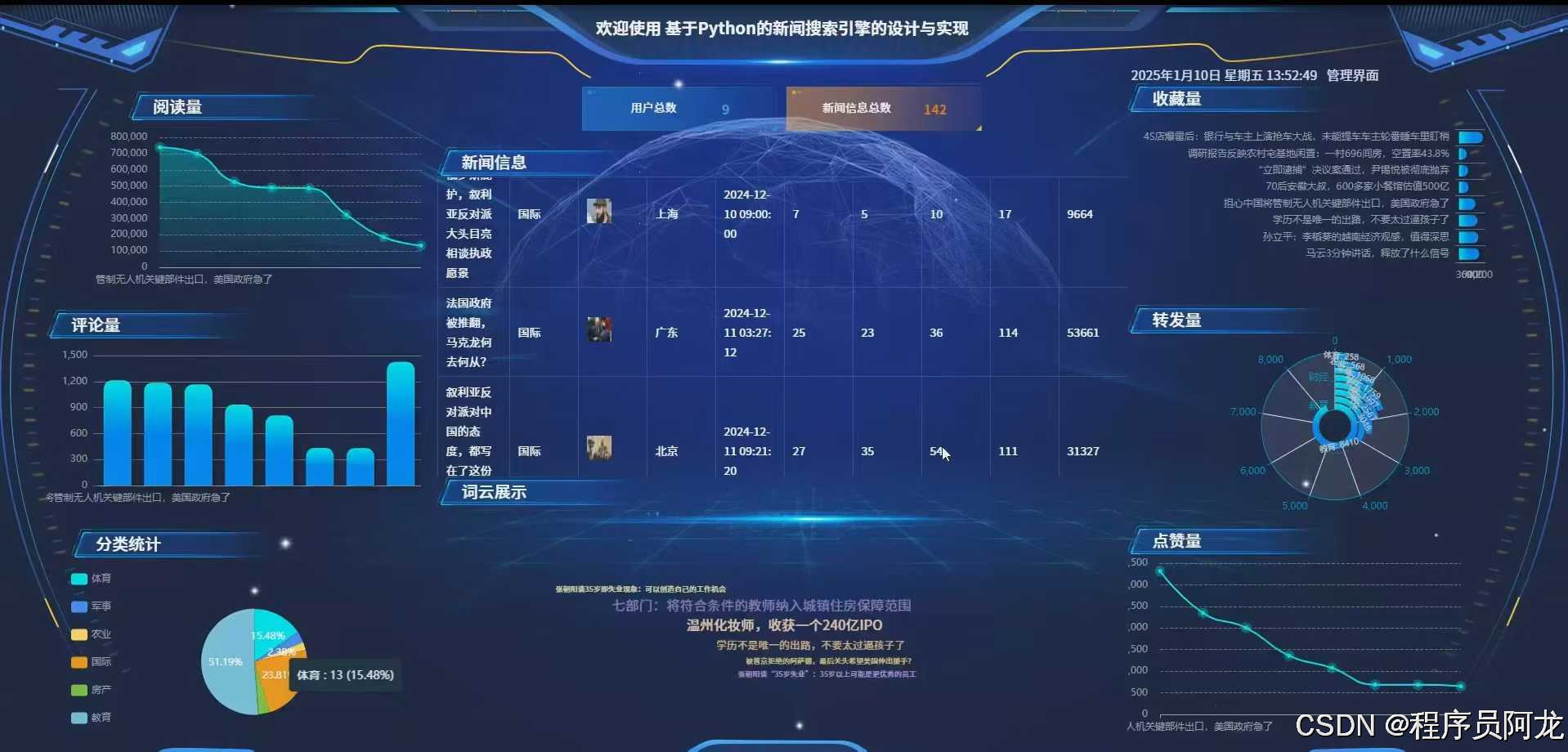
系统实现界面:
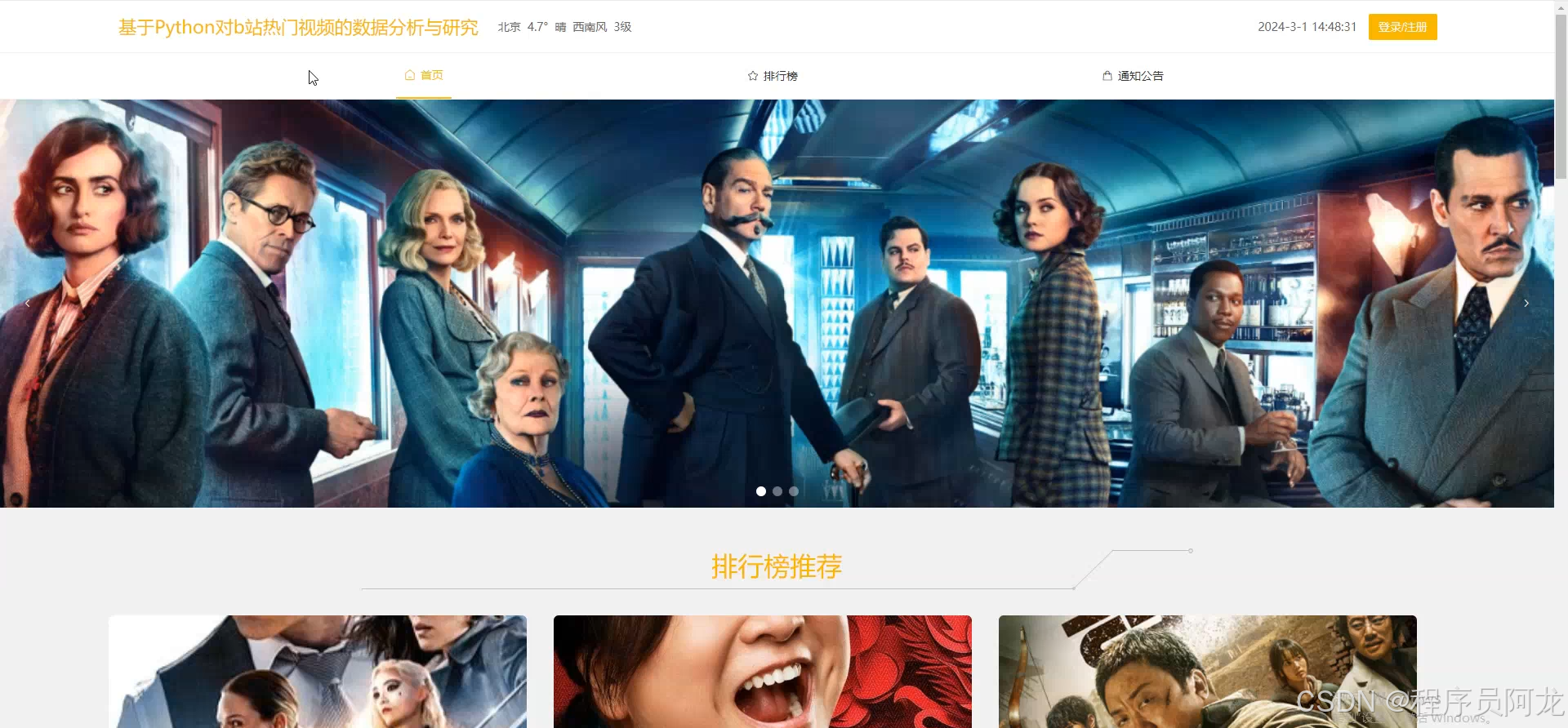
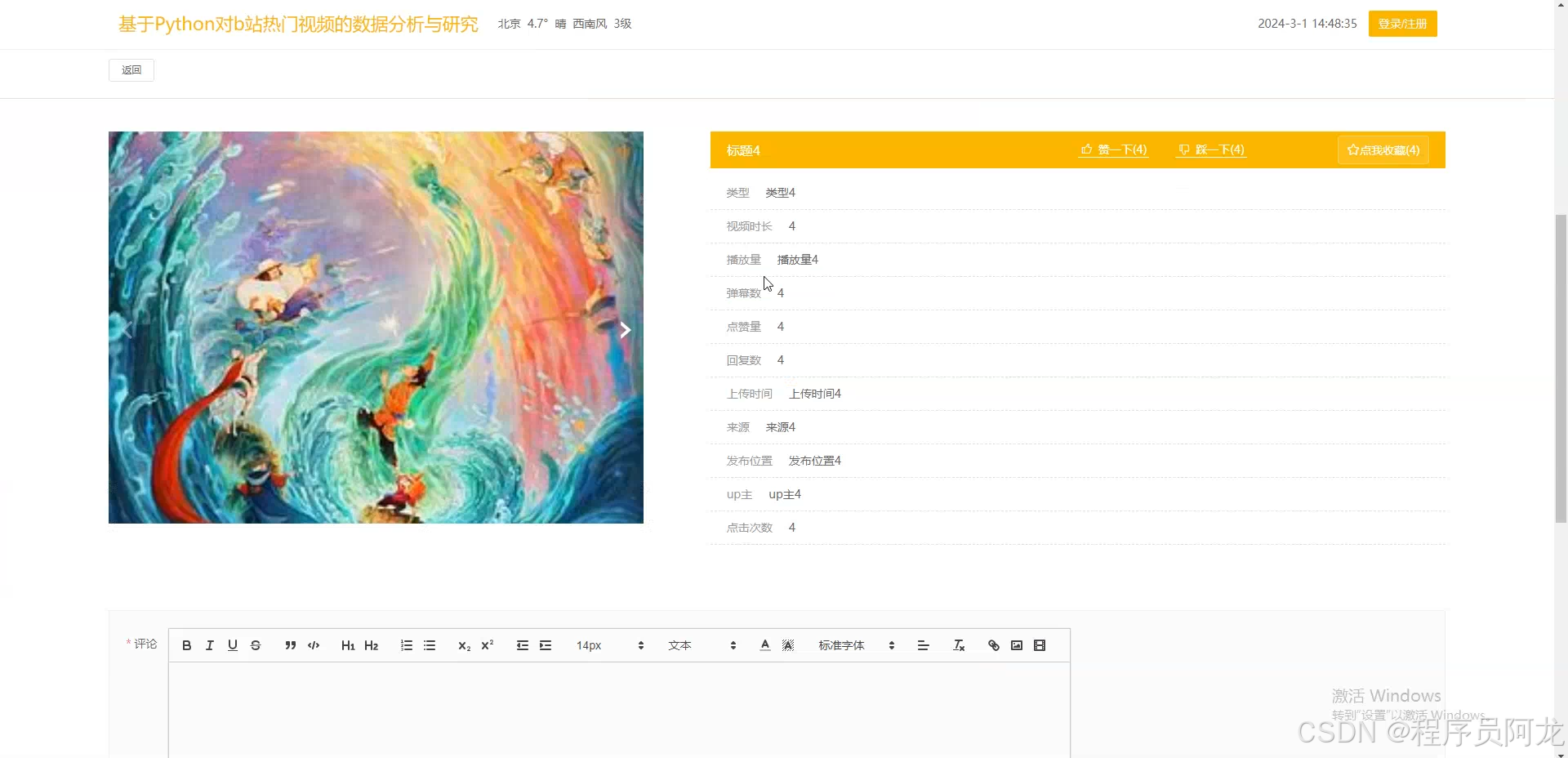
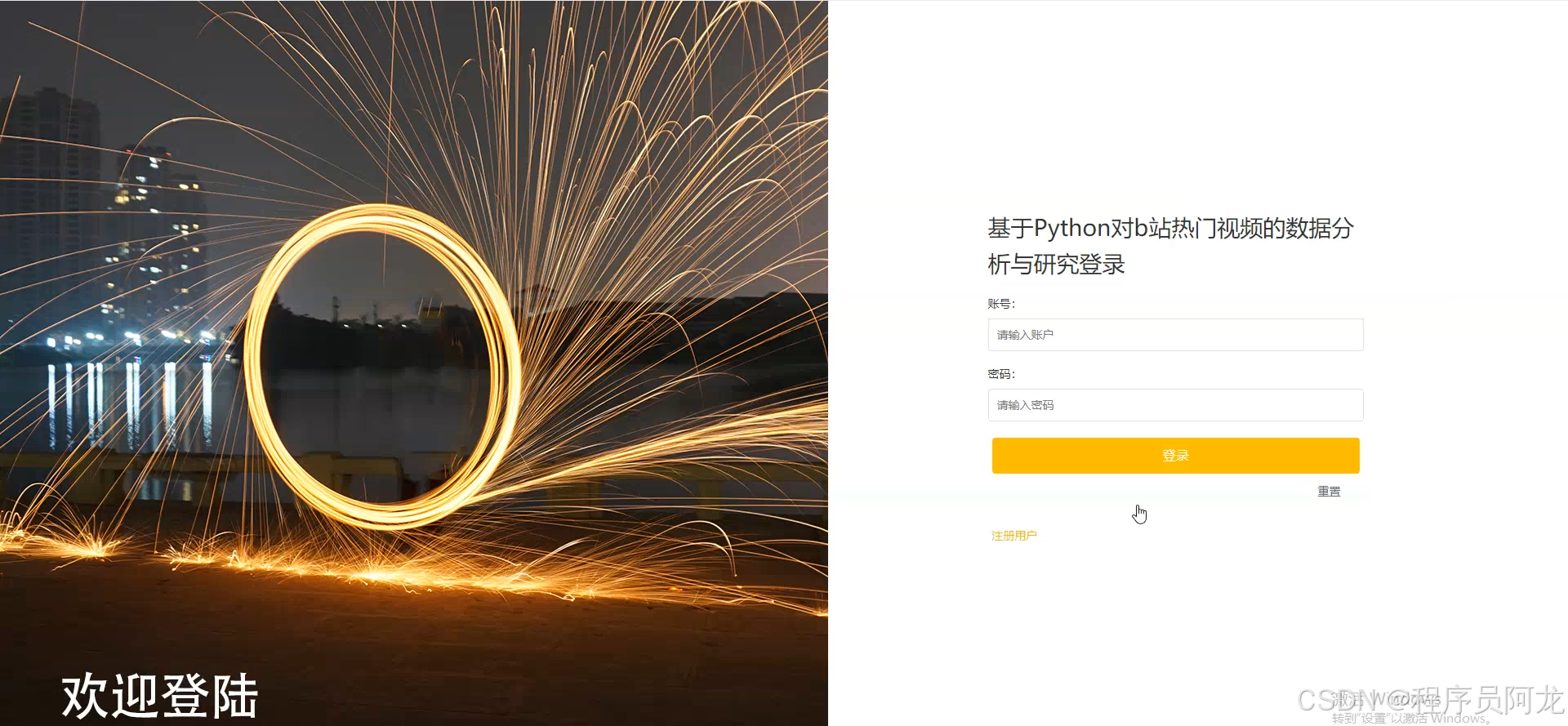
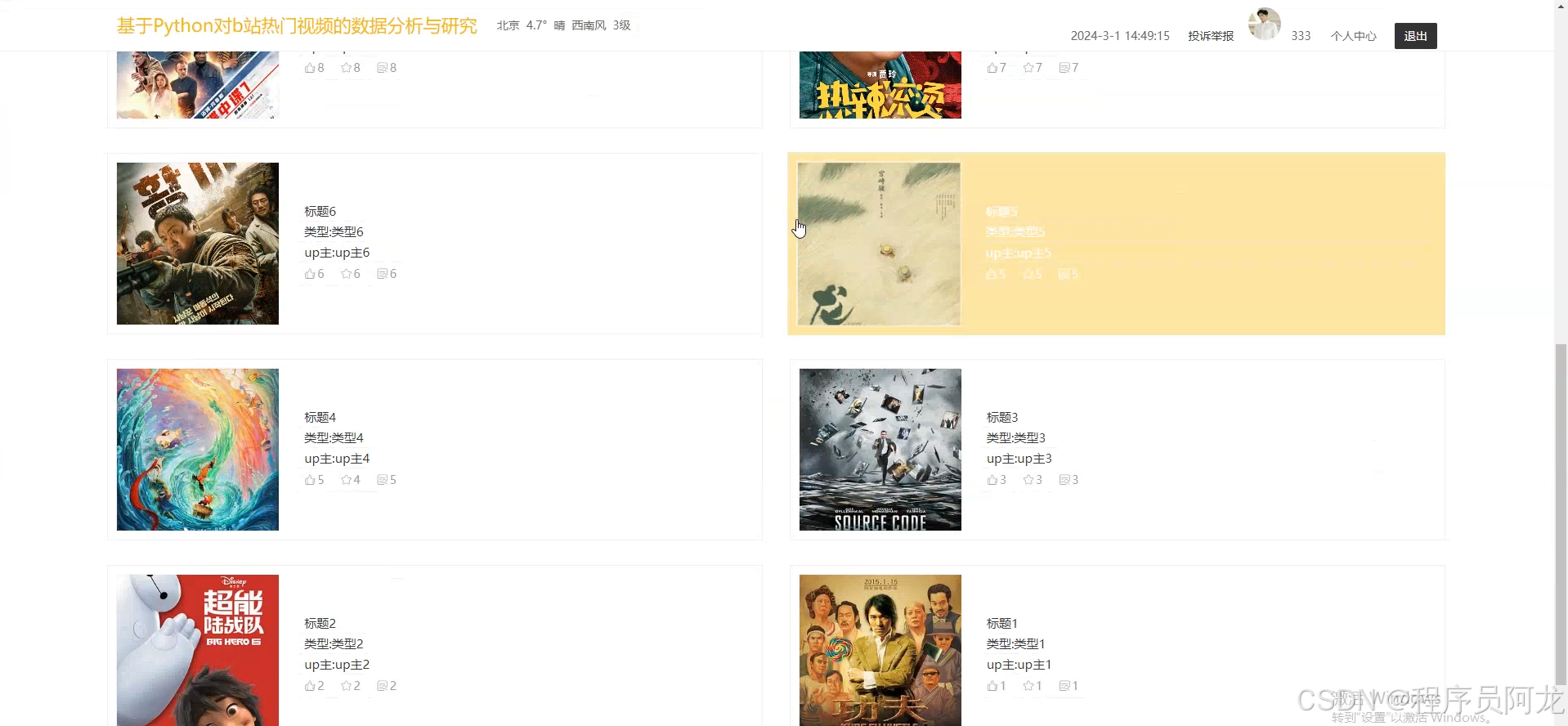

核心代码介绍:
# coding: utf-8
__author__ = 'ila'
import json
from flask import current_app as app
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.sql import SparkSession
def spark_read_mysql(sql, json_filename):
'''
排序
:param sql:
:param json_filename:
:return:
'''
df = app.spark.read.format("jdbc").options(url=app.jdbc_url,
dbtable=sql).load()
count = df.count()
df_data = df.toPandas().to_dict()
json_data = []
for i in range(count):
temp = {}
for k, v in df_data.items():
temp[k] = v.get(i)
json_data.append(temp)
with open(json_filename, 'w', encoding='utf-8') as f:
f.write(json.dumps(json_data, indent=4, ensure_ascii=False))
def linear(table_name):
'''
回归
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
training = spark.read.format("libsvm").table(table_name)
lr = LinearRegression(maxIter=20, regParam=0.01, elasticNetParam=0.6)
lrModel = lr.fit(training)
trainingSummary = lrModel.summary
print("numIterations: %d" % trainingSummary.totalIterations)
print("objectiveHistory: %s" % str(trainingSummary.objectiveHistory))
trainingSummary.residuals.show()
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
result = trainingSummary.residuals.toJSON()
spark.stop()
return result
def cluster(table_name):
'''
聚类
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
dataset = spark.read.format("libsvm").table(table_name)
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(dataset)
centers = model.clusterCenters()
for center in centers:
print(center)
return centers
def selector(table_name, Cols):
'''
分类
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
data = spark.read.table(table_name)
assembler = VectorAssembler(inputCols=Cols, outputCol="features")
data = assembler.transform(data).select("features", "label")
train_data, test_data = data.randomSplit([0.7, 0.3], seed=0)
lr = LogisticRegression(featuresCol="features", labelCol="label")
model = lr.fit(train_data)
predictions = model.transform(test_data)
return predictions.toJSON()
数据库核心代码介绍:
# coding:utf-8
__author__ = 'ila'
import pymysql
sqlDbConn =pymysql.connect(host='127.0.0.1',
user='root',
password='123456',
database='hive')
def createTable(sqlDbConn):
cursor = sqlDbConn.cursor()
cursor.execute('''CREATE TABLE IF not EXISTS `big_data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1` varchar(255) DEFAULT NULL,
`val1` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
''')
sqlDbConn.commit()
def getData(sqlDbConn):
print("Read")
cursor = sqlDbConn.cursor()
cursor.execute("select * from big_data")
for row in cursor:
print(row)
def insertData(sqlDbConn):
print("Insert")
cursor = sqlDbConn.cursor()
cursor.execute(
"INSERT INTO `big_data` (`key1`, `val1`) VALUES (%s, %s)",
('Ram', 'Delhi'))
sqlDbConn.commit()
# Without calling commit data will not saved in database.
def updateData(sqlDbConn):
print("Update")
cursor = sqlDbConn.cursor();
cursor.execute(
'update `big_data` set val1 = %s where key1 = %s',
('Motihari', "Ram"))
sqlDbConn.commit()
def deleteData(sqlDbConn):
print("Delete")
cursor = sqlDbConn.cursor();
cursor.execute(
'delete from big_data where key1 = %s',
('Ram'))
sqlDbConn.commit()
# Call the functions one by one
createTable(sqlDbConn)
insertData(sqlDbConn)
updateData(sqlDbConn)
deleteData(sqlDbConn)
getData(sqlDbConn)
sqlDbConn.close()
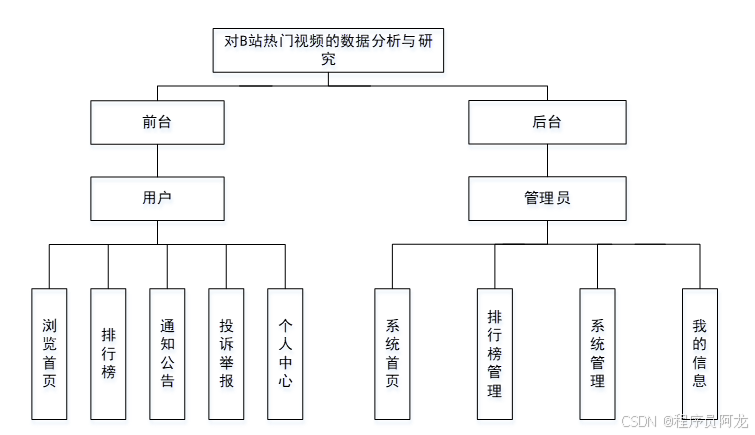
系统总体框架介绍:
2.1 Python语言
Python是由荷兰数学和计算机研究学会的吉多·范罗苏姆于20世纪90年代设计的一款高级语言。Python优雅的语法和动态类型,以及解释型语言的本质,使它成为许多领域脚本编写和快速开发应用的首选语言。Python相比与其他高级语言,开发代码量较小,代码风格简洁优雅,拥有丰富的第三方库。Python的代码风格导致其可读性好,便于维护人员阅读维护,程序更加健壮。Python能够轻松地调用其他语言编写的模块,因此也被成为“胶水语言”。
2.2 hive简介
Hive是一个数据仓库工具,当把特定结构地数据文件存入Hive对应的HDFS目录时,Hive能将其映射成表,并提供类 SQL 查询功能。底层会将sql语句转成MapReduce程序,大大方便程序开发,其中执行引擎可以更换,执行效率大大提高,Hive主要用于解决海量结构化日志的数据统计。
在本课题中,配置Hive为主要数据仓库,有以下几点原因
(1) Hive的操作接口采用类SQL语法,提供快速开发能力。
(2)相对于传统的关系型数据库,Hive更擅长于数据分析。
(3) Hive支持用户自定义函数,用户可根据自己的需求来实现自己的函数。
(4) Hive基于HDFS进行存储,扩展性高,可靠性高。
(5) Hive底层计算引擎可更换。
由于Hive默认底层引擎位MapReduce,MapReduce在遇到迭代式任务时,会将任务落盘至HDFS再进行运算,对于大批量数据处理来说,这很影响效率,所以我们会将引擎改成Tez。
2.3 Django框架简介
Django被官方称之为“完美主义者框架”,只需要很少的代码就能更快的完成一个优秀的Web应用。Django采用了MTV框架模式,此模式根据MVC进行改进形成了更适于Django的设计模式。M为模型(Model)、T为模板(Template)、V为视图(View)。
2.4 hadoop技术
Hadoop 是 Apache 软件基金会下的一个开源分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心。Hadoop提供了一个可靠的共享存储与分析系统[2]。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop拥有以下4大优势:
(1) 高容错性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2) 高扩展性:在集群间分配任务数据,可方便扩展数以千计的节点。
(3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,大大加快了任务的处理速度。
Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
在本课题中,由于其中的Mapreduce框架其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景中存在诸多计算效率等问题,Hadoop框架主要用于数据存储。
2.5 Spark
是一种DAG(有向无环图)的,基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark 是分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),简称RDD,提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,不像MapReduce需要落盘数据才能进行迭代式运算,可支持复杂的数据挖掘算法和图形计算算法[4]。Spark的运行模式包括Local、Standalone、Yarn及Mesos几种。其中Local模式仅用于本地开发,Mesos模式国内几乎不用。在公司中因为大数据服务基本搭载Yarn集群调度,因此Spark On Yarn模式会用的比较多。
Spark是一个基于内存的,用于大规模数据处理的统一分析引擎,其运算速度可以达到Mapreduce的10-100倍。具有如下特点:内存计算。Spark优先将数据加载到内存中,数据可以被快速处理,并可启用缓存。shuffle过程优化。和Mapreduce的shuffle过程中间文件频繁落盘不同,Spark对Shuffle机制进行了优化,降低中间文件的数量并保证内存优先。RDD计算模型。Spark具有高效的DAG调度算法,同时将RDD计算结果存储在内存中,避免重复计算。

为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。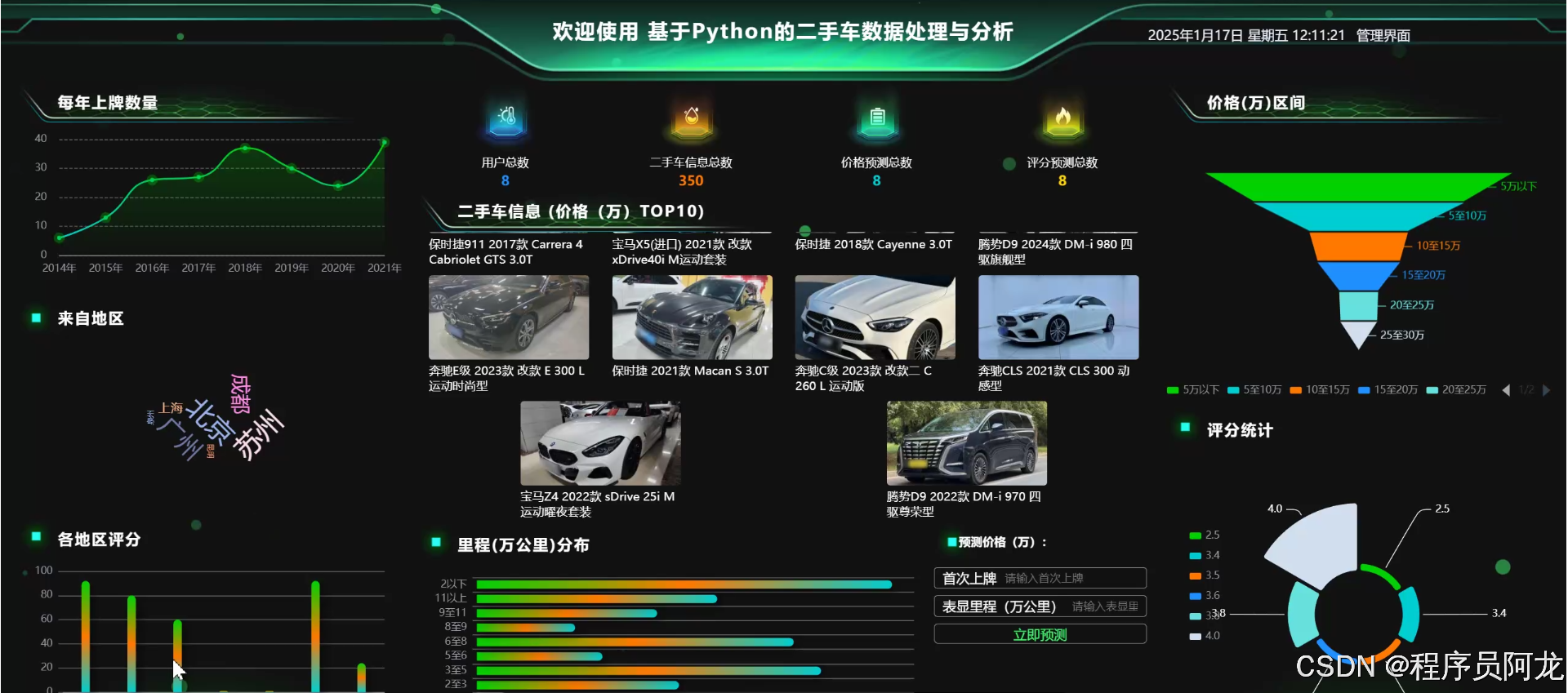

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 12
12 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)