如何使用yolov8训练使用火灾烟雾数据集 Fire和Smoke两类 yaml文件 一万张 训练集、验证集与测试集比例划分,为xt格式,标签图片相对应,用于YOLO系列模型训练 目标检测用 火焰数据集
如何使用yolov8训练使用火灾烟雾数据集 Fire和Smoke两类 yaml文件 一万张 训练集、验证集与测试集比例划分,为xt格式,标签图片相对应,用于YOLO系列模型训练 目标检测用 火焰数据集
火焰数据集,内含Fire和Smoke两种类别,自带yaml文件。整套数据集近一万张图片,训练集、验证集与测试集均已按比例划分完成,数据标记为txt格式,标签与图片一一对应,适用于YOLO系列模型训练,无需进行任何处理即可直接用于训练,数据集实测好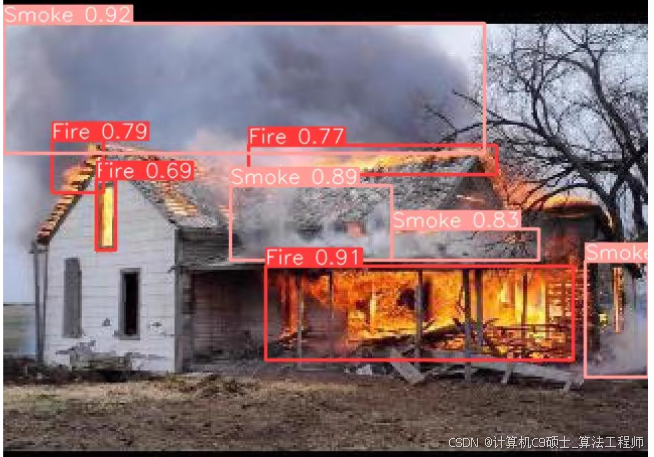
如何使用YOLOv8进行目标检测任务。该数据集适用于AI+火焰和烟雾检测,旨在通过图像识别和分析及时发现火灾隐患,提高安全水平。
火焰数据集
数据背景
火灾是一种常见的安全隐患,及时发现火焰和烟雾对于预防火灾事故至关重要。火焰数据集包含大量的火焰和烟雾图像,这些图像已经进行了标注,可以直接用于训练YOLO系列模型。数据集包含近一万张图片,分为训练集、验证集和测试集,标签格式为YOLOv5兼容的txt格式,标签与图片一一对应。
应用领域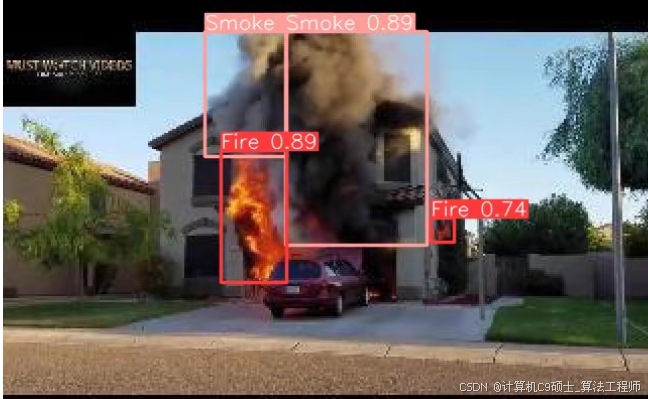
AI+火焰和烟雾检测
文件目录
深色版本
fire_smoke_dataset/
├── train/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── valid/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── test/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── fire_smoke.yaml
├── README.txt
├── models/
│ └── yolov8/
├── src/
│ ├── train.py
│ ├── predict.py
│ ├── utils.py
│ ├── dataset.py
├── weights/
│ └── best_model.pt
├── requirements.txt
└── README.md
数据说明
数据集规模:共包含近一万张火焰和烟雾图像样张。
训练集:包含7000张图像样张(带txt标注)。
验证集:包含1500张图像样张(带txt标注)。
测试集:包含1500张图像样张(带txt标注)。
图像格式:JPG
标签格式:TXT,标签数据以YOLOv5兼容的格式记录。
预处理:数据集已按比例划分完成,标签与图片一一对应,无需进行任何处理即可直接用于训练。
- 安装依赖
首先,确保你已经安装了必要的库。创建一个requirements.txt文件,内容如下:
深色版本
torch
torchvision
numpy
pandas
matplotlib
tqdm
pyyaml
opencv-python
ultralytics
然后,使用以下命令安装依赖:
bash
深色版本
pip install -r requirements.txt
2. 数据集准备
确保你的数据集已经按照以下结构组织:
深色版本
fire_smoke_dataset/
├── train/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── valid/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── test/
│ ├── images/
│ │ └── *.jpg
│ ├── labels/
│ │ └── *.txt
├── fire_smoke.yaml
├── README.txt
每个文件夹中包含对应的图像文件和标签文件。确保所有图像文件都是.jpg格式,标签文件是.txt格式。
- YOLOv8训练代码
3.1 src/train.py
python
深色版本
import torch
from ultralytics import YOLO
def train_model(data_yaml, epochs=100, batch_size=16, img_size=640):
# 加载模型
model = YOLO(‘yolov8n.yaml’) # 使用YOLOv8小模型
# 训练模型
results = model.train(
data=data_yaml,
epochs=epochs,
batch=batch_size,
imgsz=img_size,
device='cuda' if torch.cuda.is_available() else 'cpu'
)
# 保存模型
model.save("weights/best_model.pt")
if name == “main”:
data_yaml = “fire_smoke_dataset/fire_smoke.yaml”
train_model(data_yaml)
4. 模型评估
训练完成后,可以通过测试集来评估模型的性能。示例如下:
4.1 src/predict.py
python
深色版本
import torch
import matplotlib.pyplot as plt
from ultralytics import YOLO
from src.dataset import get_data_loaders
import numpy as np
def predict_and_plot(data_yaml, model_path, num_samples=5):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = YOLO('yolov8n.yaml')
model.load_state_dict(torch.load(model_path))
model = model.to(device)
model.eval()
# 加载测试数据
test_loader = get_data_loaders(data_yaml, split="test")
fig, axes = plt.subplots(num_samples, 2, figsize=(10, 5 * num_samples))
with torch.no_grad():
for i, (images, targets) in enumerate(test_loader):
if i >= num_samples:
break
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
outputs = model(images)
predictions = [output['boxes'].cpu().numpy() for output in outputs]
images = [image.cpu().numpy().transpose((1, 2, 0)) for image in images]
for j in range(len(images)):
ax = axes[j] if num_samples > 1 else axes
ax[0].imshow(images[j])
ax[0].set_title("Input Image")
ax[0].axis('off')
ax[1].imshow(images[j])
for box in predictions[j]:
ax[1].add_patch(plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1], fill=False, edgecolor='red', linewidth=2))
ax[1].set_title("Predicted Bounding Boxes")
ax[1].axis('off')
plt.tight_layout()
plt.show()
if name == “main”:
data_yaml = “fire_smoke_dataset/fire_smoke.yaml”
model_path = “weights/best_model.pt”
predict_and_plot(data_yaml, model_path)
5. 数据加载器
为了方便加载数据,可以创建一个数据加载器类。
5.1 src/dataset.py
python
深色版本
import os
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import numpy as np
class FireSmokeDataset(Dataset):
def init(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.image_files = os.listdir(image_dir)
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.image_files[index])
label_path = os.path.join(self.label_dir, self.image_files[index].replace('.jpg', '.txt'))
image = Image.open(img_path).convert("RGB")
with open(label_path, 'r') as f:
lines = f.readlines()
boxes = []
labels = []
for line in lines:
parts = line.strip().split()
label = int(parts[0])
x_center = float(parts[1])
y_center = float(parts[2])
width = float(parts[3])
height = float(parts[4])
xmin = x_center - width / 2
ymin = y_center - height / 2
xmax = x_center + width / 2
ymax = y_center + height / 2
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
if self.transform:
image = self.transform(image)
return image, target
def get_data_loaders(data_yaml, split=“train”, batch_size=16, num_workers=4):
transform = transforms.Compose([
transforms.Resize((640, 640)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
if split == "train":
image_dir = "fire_smoke_dataset/train/images"
label_dir = "fire_smoke_dataset/train/labels"
elif split == "valid":
image_dir = "fire_smoke_dataset/valid/images"
label_dir = "fire_smoke_dataset/valid/labels"
elif split == "test":
image_dir = "fire_smoke_dataset/test/images"
label_dir = "fire_smoke_dataset/test/labels"
dataset = FireSmokeDataset(image_dir, label_dir, transform=transform)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True if split == "train" else False, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))
return data_loader
- 运行项目
确保你的数据集已经放在相应的文件夹中。
在项目根目录下运行以下命令启动训练:
bash
深色版本
python src/train.py
训练完成后,运行以下命令进行评估和可视化:
bash
深色版本
python src/predict.py - 功能说明
数据集类:FireSmokeDataset类用于加载和预处理数据。
数据加载器:get_data_loaders函数用于创建训练、验证和测试数据加载器。
训练模型:train.py脚本用于训练YOLOv8模型。
评估模型:predict.py脚本用于评估模型性能,并可视化输入图像、真实标签和预测结果。 - 详细注释
dataset.py
数据集类:定义了一个FireSmokeDataset类,用于加载和预处理数据。
数据加载器:定义了一个get_data_loaders函数,用于创建训练、验证和测试数据加载器。
train.py
训练函数:定义了一个train_model函数,用于训练YOLOv8模型。
训练过程:使用YOLOv8的API进行训练,指定数据集路径、训练轮数、批次大小和图像尺寸。
predict.py
预测和可视化:定义了一个predict_and_plot函数,用于在测试集上进行预测,并可视化输入图像、真实标签和预测结果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)