pytorch l2正则化_吴恩达深度学习 编程作业六 正则化(2)
推荐守门员应该将球踢到哪个位置,才能让自己的队员用头击中。1.无正则化模型判别是否有正则化与调用其他计算函数。准确率:0.948/0.915明显过拟合overfiting了。2.L2正则化公式如下,在原有cost函数基础上增加L2项,L2为参数w的均方根根据公式书写代码:增加正则项后,反向传播的导数也会对应改变,其余参数不变。准确率:0.938/0.93,相比没有正则化变好了一些,并且过拟合现象消
推荐守门员应该将球踢到哪个位置,才能让自己的队员用头击中。
1.无正则化模型
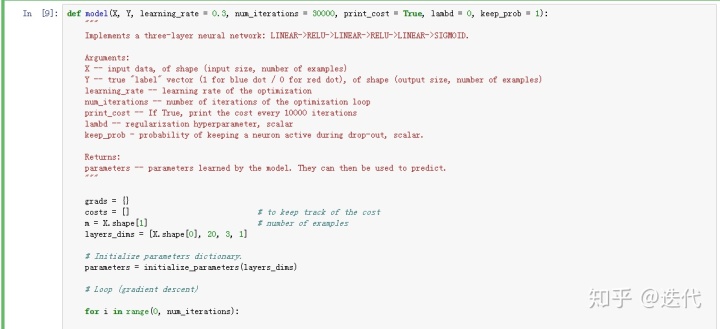


判别是否有正则化与调用其他计算函数。
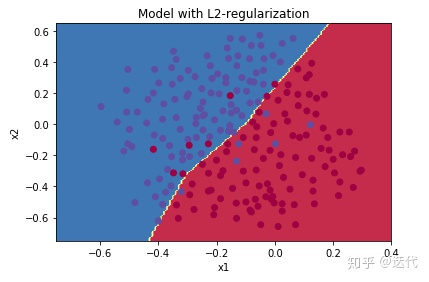
准确率:0.948/0.915
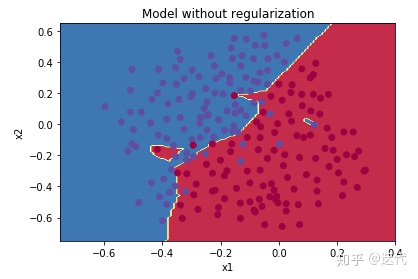
明显过拟合overfiting了。
2.L2正则化
公式如下,在原有cost函数基础上增加L2项,L2为参数w的均方根
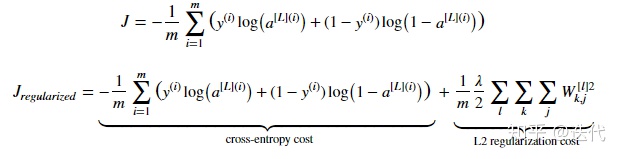
根据公式书写代码:
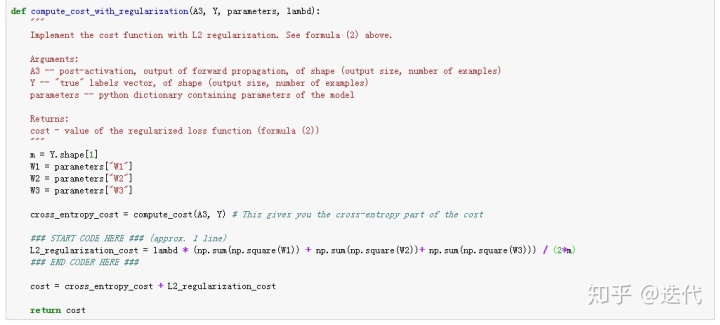
增加正则项后,反向传播的导数也会对应改变,其余参数不变。

准确率:0.938/0.93,相比没有正则化变好了一些,并且过拟合现象消失。
增加超参数
L2正则认为权重越小的函数越简单,越平滑,因此在cost成本函数中增加L2项。
需要改的只有成本函数与反向传播的导数计算公式。
3.Dropout
在深度网络中,每次迭代都以1-keep_prob的概率关闭一些神经元。keep_prob保留神经元的概率。Dropout每次迭代关闭的神经元都不同,因此每次训练的模型其实是不同的,这相当于是另一种神经网络的集成。
步骤:
(1)建立随机数矩阵D,其维度和A输出一样。
(2)将随机数矩阵转化为0,1矩阵,随机数大于keep_prob转换为0,小于keep_prob转换为1。
(3)让矩阵D与矩阵A相乘(对应位置相乘而不是矩阵相乘),得到新的矩阵A,相乘后为0的那些神经元被关闭。
(4)新的矩阵A除以keep_prob,为了使期望值不变。
前向传播+dropout,记得最后计算得到的A要除以keep_prob哦!

反向传播+dropout
反向传播时,对A求导数dA需要乘上同一层的D,在得到新的dA后,还需要除以keep_prob。

准确率:0.929/0.95,比之前效果更好。
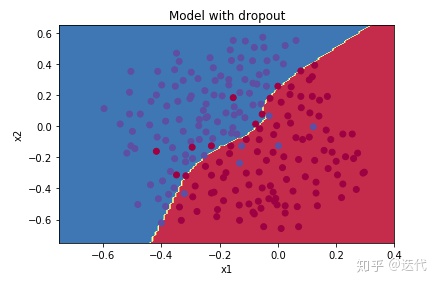
dropout是一种正则化技术;
dropout只在训练时使用,不在测试中使用;
dropout在前向传播与反向传播中均需要参与,切记除以keep_prob;
小结:
正则化帮助处理过拟合问题;
正则化会减小参数,简化模型;
L2、dropout是一种很好的正则化手段。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)