嵌入式性能优化心得
性能优化心得
搞嵌入式,尤其是在DSP上,有时候对实时性要求比较高,对性能要求也就比较高,有时候甚至需要去抠每一个函数的cycle,来达到时间窗。在本文中分享一些通过架构特性的方法来提高性能,总有一款适合你。本文首先介绍一些开销的常见,再描述一些提升性能的方法。
开销
运行开销
除了自己写的代码的开销,还有一些系统上的开销,包括系统调用、进程间通信、进程的上下文切换开销之类。
| 特性 | 影响效果 | 举例 |
|---|---|---|
| 系统调用开销 | 调用内核系统自带的API,是应用系统和系统之间的接口,对性能敏感的系统应该减少使用 | getpid()这种系统函数,每次调用的开销因为涉及用户态内核态之间的切换,本质上是通过软中断,从用户态进入内核态,执行对应的中断处理函数,这时候要把用户态的堆栈消息保存到pc寄存器中,调用完毕后,从内核栈恢复pc寄存器,返回用户态 |
| TLB MISS开销 | CPU中负责物理地址和虚拟地址转换的缓冲表,对性能要求高的场景应该避免触发TLB MISS | 首先TLB表项数目是优先的,每个进程都要维护虚实地址关系,所以TLB表实际上是通过分时复用的方式来工作,当软件访问某个虚拟地址,这个地址在TLB表没有映射关系,那么就会由内核完成TLB重填,这个阶段非常耗时。(不好理解的话,可以用cache的方法来理解,可以理解为cache中没有想要的数据,要从主存中重新读入,耗时一下就提高了)可以参考下图 |
| 进程间切换开销 | 上下文切换耗时导致超时 | 进程切换流程可以理解为:1.切换页表全局目录;2.切换内核态堆栈;3.切换硬件上下文;4.刷新TLB;5.系统调度器代码执行。在进程切换的过程中,cache和TLB需要重新装载,可能会导致上文的TLB或者Cache的消耗比预期大,需要列入考虑 |
| 进程间通信开销 | IPC开销在大部分情况下是无法避免的,只能通过使用更合适的IPC方式或者优化IPC来做到减小开销 | 以管道通信举例,影响管道通信的因素有:系统调用,内存拷贝,调度唤醒 |
TLB表的原理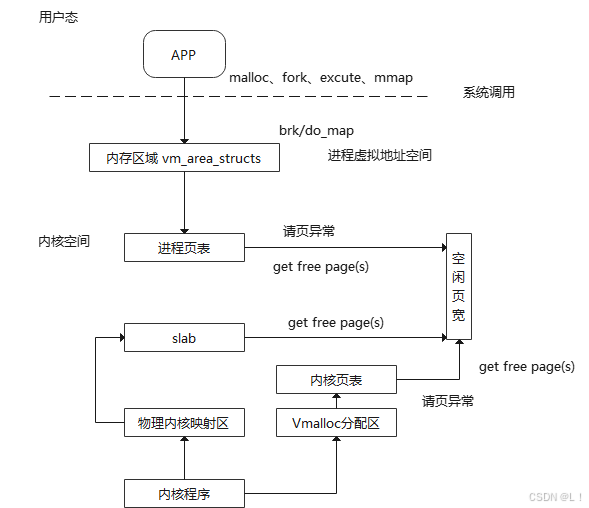
管道通信举例: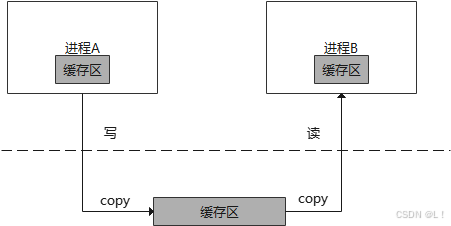
数据结构
下文列举一些简单常用的数据结构,以及适用的场景
| 数据结构 | 适用场景 | 时间复杂度 |
|---|---|---|
| 数组 | 只查找,无随机插入删除场景 | 按下标查找O(1), 按元素值二分查找O(logN) |
| 链表 | 插入删除场景 | 给定前驱插入删除高效O(1),增加多级索引的调表查找O(logN) |
| 红黑树 | 同时需要插入删除查找场景 | 插入删除查找较为均衡O(logN) |
| 哈希表 | 哈希冲突小场景 | 插入删除查找O(1),减少键值相同冲突场景 |
| 字典树 | 前缀重合度高,需要前缀匹配场景 | 插入删除查找O(N) |
提高性能的工具或方法介绍
通过CPU体系架构提高性能
CPU体系架构上主要是依赖一些ARM、X86的特性来实现
| 特性 | 效果 |
|---|---|
| 指令级并行 | 利用流水线的特性,让指令充满流水线,利用多级流水的并行能力 |
| 乱序执行 | 减少指令依赖关系,发挥乱序执行能力 |
| 分支预测 | 有规律分支跳转,减少分支预测失败的可能性,避免丢弃预取指令 |
| Cache | 利用Cache特性,提高数据读写效率,通过一致性协议避免未同步情况 |
| 数据级并行 | 利用一些架构的指令并行特性来提升效率,例如ARM的NEON |
这些特性在https://blog.csdn.net/weixin_44523776/article/details/144930368?spm=1001.2014.3001.5502文中有详细介绍,这里就不赘述了。
通过编译优化或者关键字提升性能
最简单是通过gcc的-o选项,例如-O0、-O1、-O2、-O3:优化级别逐次递增,-Os根据程序空间大小的优化,-Ofast最为激进的优化方法。
- -O0:没有优化,便于调试。
- -O1:基本优化,提升效率的同时不显著增加编译时间,删除一些不必要的代码。
- -O2:更高级的优化,适用于大多数应用,既提高性能,又保持合理的编译时间,大多使用O2的优化,能平衡时间和空间。
- -O3:极致优化,提升性能的同时可能增加代码体积和编译时间,适用于对性能极为关键的场合,但是可能会增加内存的使用,因为过度优化会使得代码体积更大,适用于对性能要求极高的场景。
- -Os:优化空间,减少代码大小,适合内存受限的环境。
- -Ofast:最激进的优化,最大程度提高执行速度,可能牺牲标准和准确性。
函数内联:编译阶段可以将函数展开,减少函数调用所需要的入栈出栈指令,从而提升性能,通常使用static inline来修饰函数。
适用于一些频繁调用的小函数,缺点就是过度使用内联函数会导致代码膨胀。gcc中还支持在代码中强制内联或者强制非内联
__attribute__((noinline))
__attribute__((always_intline))
static inline和宏的差别:
- inline是运行时展开,宏是编译时预处理展开
- 宏不好单步调试,inline可以
- 宏调用是入参不能有副作用,例如出现#define max(a++,b++)这种情况,容易产生二义性。
restrict关键字
restrict关键字的定义是告诉编译器该指针是指向一个唯一的内存位置,并且在该指针的生命周期内,程序不会通过其他指针访问相同的内存区域。当确保这一块地址不会被发生交叠的时候可以使用这个,也能提高访问效率。
反馈式编译
这个方法我基本没用过,感兴趣的可以自行了解,主要是在编译过程中加入 -fprofile-generate, 收集运行时数据,反馈给编译器做针对性优化,进而提升性能。
利用profiling工具查看性能瓶颈做进一步性能优化
在嵌入式开发过程中,会通过一些profiling工具能够提供函数执行的时间、内存使用情况、调用频率等数据,让开发者能够做出更好的决策。
profiling工具核心原理是使用采样或者事件追踪的方式收集程序的执行消息:
1.采样:采样是一种周期性收集程序状态信息的方法。在一定时间间隔内,Profiling工具会记录程序的状态(例如 CPU 寄存器、调用堆栈、内存使用等)。这种方式的优点是性能开销小,因为它并不追踪每一条指令或每一个函数调用,而是定期采样程序的状态。
常见的采样方法包括 CPU 时间采样、调用栈采样等。
2.事件追踪:事件追踪通过修改程序的源代码或二进制文件,在特定的代码路径(如函数入口、出口、内存分配等)插入监控代码,记录每个事件发生的时间、次数和其他信息。
这种方法能提供更精确的性能数据,但会对程序的执行造成更高的性能开销,因为每个事件都被追踪和记录。
perf
在linux环境下的话,可以直接使用linux自带的perf工具,perf工具的本质是按周期读取pc指针的寄存器,从而获取每个函数的执行时长,然后根据每个函数的执行时长再做进一步优化。具体步骤如下:
- perf state ./sample perf state + 二进制文件+ 参数(选填)
- perf record ./sample 采样,对文件进行运行采样,结果保存在perf.data文件中
- perf report 查看性能详情,进而分析性能瓶颈。输出的是一个表格,依次有Overhead, Command, Shared Object, Symbol五列。
• Overhead:指出了该Symbol采样在总采样中所占的百分比。在当前场景下,表示了该Symbol消耗的CPU时间占总CPU时间的百分比
• Command:进程名
• Shared Object:模块名, 比如具体哪个共享库,哪个可执行程序。
• Symbol:二进制模块中的符号名,如果是高级语言,比如C语言编写的程序,等价于函数名。 - perf top,可以看实时的性能数据
- perf trace 跟踪系统调用,有点类似strace,但支持更多性能相关事件。strace专注于调试,记录系统调用及其详细信息,适合调试程序和操作系统的交互;而perf trace 是一个性能分析工具,不仅追踪系统调用,还可以统计性能信息,用于分析和优化。
valgrind
内存分析的神器,主要用于检测内存错误,包括:内存泄漏检测;未初始化内存访问;越界访问;内存错误。常见用法如下:
valgrind --leak-check=full ./sample
--leak-check=full:获取完整的内存泄漏检测报告。
valgrind --tool=callgrind ./sample
用于记录程序调用核CPU缓存使用情况
valgrind --tool=cachegrind ./sample
顾名思义,是用来查看缓存命中率的,帮助优化程序内存访问模式
valgrind --tool=massif ./sample
用于分析堆内存的使用情况
valgrind --tool=helgrind ./sample
用于检测多线程状态的竞态条件,特别是数据竞争问题
笔者比较常接触的主要是上面两种,有的公司可能还会自己封装一些profiling工具,或者通过trace查看芯片的运转流程,但是本质上都和一些常见的基础工具的原理类似。
性能设计的方法论
综上,可以总结几个方案设计时,考虑性能的方法论
- 资源消耗最小化,只要使用资源就是有代价的,减少无效、低价值资源的占用和消耗
- 资源利用最大化,让流水线或者核最大化使用,减小核与流水线的空闲和等待
- 任务处理最优化,这部分主要是编码以及调度,用最少的资源干最多的活
- 大型任务分布化,最直接的例子就是使用多级流水,将大任务划分为小任务,降低对单点资源的要求
进一步地有一些具体的措施:
- 快速通道:减少核心事务的处理量,简化处理过程。这个最简单的例子,就是分支预测,把容易走到的if分支放在主语句中,剩下的异常分支或者不怎么可能触发的场景放在else里,这样能减少由于分支预测失败导致流水线需要重新刷新的时间。
- 批量处理:将一段时间内经常性的任务和数据,累积到一起,批量处理。这个的例子也很好找:看这个描述是不是和乱序执行的概念一样?其实就是将没有数据依赖的指令放在一起,节省开销,虽然看着不起眼,但是在实时性高且数据量大的场景,这种方法的效果还是很明显的。软硬件上具体的收益是:1.减少了公共处理开销,包括前期准备和后续处理;2.保留了cache热度,降低了访存开销;3。减少任务调度批次,降低任务切换开销
- 预处理:将一部分任务提前到关键人物执行前执行,减少对关键任务的依赖。当然这个预处理涉及很多方面:
1.资源预分配:提前申请好资源,关键业务直接从资源池中取。这个最简单的例子就是提前申请好内存,反复使用,减少重复malloc、free的开销
2.业务流程预编排:预先编排好典型业务流程,关键业务请求仅做简单的匹配选择。这个有点抽象,其实也可以看做一种分支预测,当你知道某个业务流程的结果,例如成功or失败,走对应流程,那么可以用类似表驱动的方式做匹配,例如成功,就直接匹配到对应流程。
3.业务数据与初始化。这个也好理解,比如某些任务有一些静态配置,可以提前配置好,存放在内存里,需要的时候通过DMA或者别的方式取用。
上述都是一些设计上、架构上的设计方案,那么在实际编码过程中,可以采取哪些方法来提高代码的性能呢?
从编码原则上来看:
- 降冗余:优化代码实现逻辑,减少编译生成的指令书林,降低运行开销。在迭代开发过程中,很容易会发现之前的代码有点逻辑冗余或者体量冗余,这时候就要动动小手做一些微重构,在不影响结果且确保性能有提升的情况下,尽可能地精简代码。
- 提效率:提高指令效率,采用向量化指令、原子操作、或者在精度满足的情况下多使用整数操作代替浮点操作;提升访存效率,指的是利用多级Cache机制,提升指令或者数据的读取效率;降低执行阻塞,减少锁等竞争性资源的冲突风险,降低调度器的等待时长,以及调度算法优化。
从真正的编码过程看:
1.有的代码量占比小,但是CPU消耗极大,这里可能就需要通过深入根据CPU架构做对应优化,例如用汇编、专用指令、寄存器等方法做深度体系优化,这里我能力有限,没法提供相对于的例子。
2.有一些代码可以通过数据结构的优化设计,例如善用哈希、链表、红黑树等前人实现的好用增删改的方法,减少在这方面的耗时;还有通过数据重排来实现数据读写速率的提示,最简单的例子就是字节对齐,还有利用编码实现寄存器的软流水。
3.剩下的代码就是占程序的绝大部分,就是各种基础代码。这种时候就要使用更优秀的算法、或者减少指令阻塞等方法。
下面是一些对不同情况可能能用到的代码优化方法
| 类型 | 方法 |
|---|---|
| 变量 | 1.基础数据类型直接复制;2.如果有全局变量需要多次访问,建议用局部变量进行缓存 3.慎用volatile修饰全局变量 |
| 语句 | 1.减少冗余初始化;2.减少重复计算;3.减少memset使用,这边的意思是,如果所在的业务代码有封装好的初始化函数,则多使用封装好的,当对大型数据结构或者数组使用memset的时候,它是通过遍历内存对每个字节赋指定的值,会非常的耗时。需要注意的是,对字符串清零的时候,也是因为类似的原因 |
| 表达式 | 复用公共子表达式 |
| 控制语句 | 1.合理地使用分支预测,这个地方上文说过了,不赘述了;2.小范围的情况,switch比if-else快;3.循环变量使用和体系结构匹配的数据类型;4.提取循环体内和循环无关的处理;5.减少循环次数,这里可以通过将重复的循环整合,或者将次数多的循环放在内层 |
| 数据结构 | 字节对齐;利用CacheLine原理将需要同时访问的数据,定义在临近代码附近(这一块的效果并不明显,除非需要多次读取的情况) |
| 锁 | 慎用,在多线程情况,保证锁生效区间最小化,即保证每个线程占用的资源是尽可能小的 |
| 内存 | 1.在嵌入式中,减少动态内存的重新分配,多使用内存池;2.将不同业务流程的读写分开定义,避免伪共享导致数据异常。 |
| 函数设计 | 1.利用好restrict关键字;2.合理设计有返回值和无返回值函数,避免对返回值的冗余检查;3.合理利用static inline来声明简短且多次调用的函数;4.除了日志函数等,最好不要使用带变长参数列表的函数;5.避免直接传递值或者对象,多使用引用和指针,如果直接传递值或者对象的话,会在内存中搞一份副本,然后函数内部对该副本进行操作,而不是原始对象,这种情况会造成不必要的性能和内存开销。适当使用const |
| 字节对齐 | 很容易忽略的一点,和系统相通的对齐方式,能够提高对内存的读写速度。GCC编译选项加上**-fpack-struct[=n]或预编译指令#pragma pack(n),可以限定对齐值的上限**,或者通过变量属性 __attribute((aligned(n))) 可以约定对齐 下限,值得一提的是,通过aligned对一些需要放在CacheLine的数据结构比较友好,因为可以让CacheLine的字节和结构体对齐,加快读写速度,并且只对结构体和全局变量生效。注:大多情况下不建议使用-fpack-struct,因为涉及多组件编译选项统一,如果某个组件没有使用,可能会出现异常。 |
以上就是我对嵌入式性能优化的一些优化心得,后续可能会更新一些实际案例和其他心得。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)