deeplearning.17深层神经网络基础
深层神经网络基础什么是深度神经网络深层神经网络中的前向传播核对矩阵的维数为什么用深度神经网络搭建深层神经网络块实现前向和反向传播参数和超参数什么是深度神经网络不同于浅层神经网络,只有一层隐藏层,图中的神经网络具有2层隐藏层和5层隐藏层。分别被称为三层神经网络和六层神经网络如下图所示的四层神经网络,三个隐藏层。我们用L表示层数L=4。用n的上标[l]表示节点的数量,或者第l(L的小写字母)层上的单元
什么是深度神经网络
不同于浅层神经网络,只有一层隐藏层,图中的神经网络具有2层隐藏层和5层隐藏层。分别被称为三层神经网络和六层神经网络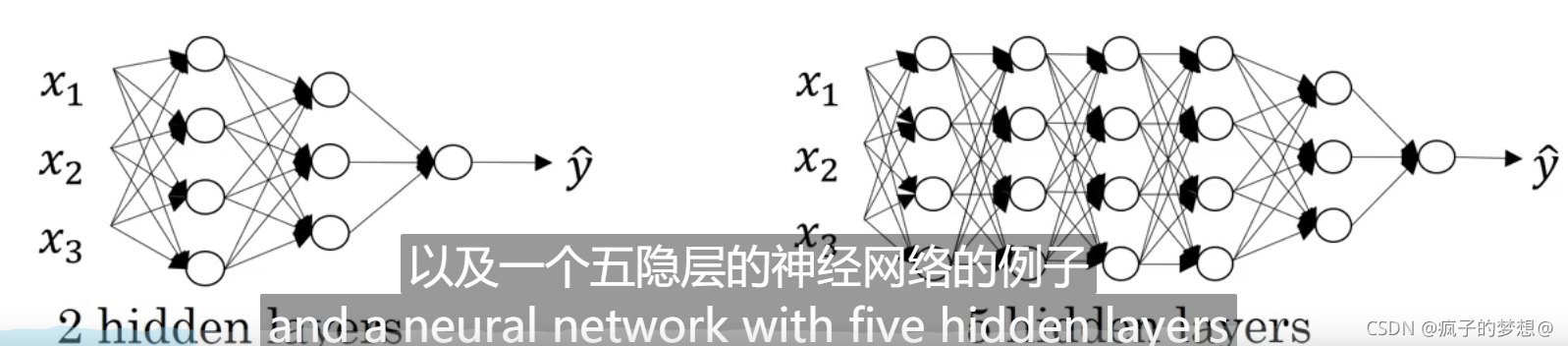
如下图所示的四层神经网络,三个隐藏层。我们用L表示层数L=4。用n的上标[l]表示节点的数量,或者第l(L的小写字母)层上的单元数量,比如n^ [1]=5,表示的是隐藏层的第一层,节点为5。在神经网络中,我们把输入层称为第0层,n ^ [2]=5,n ^ [3]=3,n ^ [4] =1,n^ [0]=3这是输入层。激活函数也是 a^ [l]来表示,a ^ [1]表示第一层隐藏层的激活函数。用w ^ [l]表示在a ^ [l]中计算z ^ [l]的权重,z ^ [l]计算方程里的b ^ [l]也一样。输入层的a[0]=x即输入特征,a[L]表示预测值y^。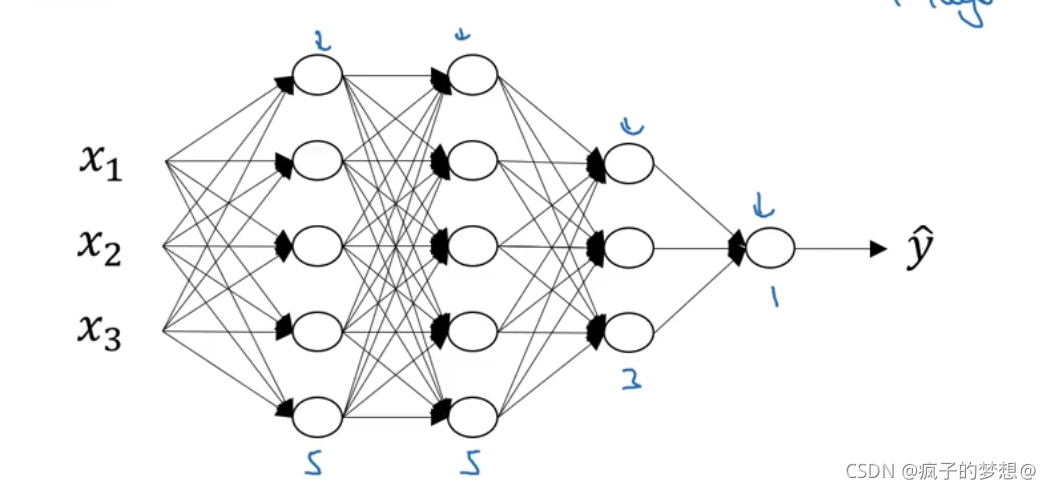
深层神经网络中的前向传播
一、先看对其中的一个训练样本x怎么正向传播
x:z^ [1]=w^ [1]乘x+b^ [1],a^ [1]=g^ [1](z^ [1])这是第一层,其中g()表示的是激活函数。第二层是z^ [2]=w^ [2]乘a^ [1]+b^ [2],a^ [2]=g^ [2](z^ [2]),后续的第三层,第四层都是类似的这样。然后第四层 a^ [4]=g^ [4](z^ [4])=y^ 。那么第0层即输入层,x=a^ [0]。
二、向量化的计算
这里的大写Z和大写A,大写X都表示的是矩阵向量,把所有训练样本的相同意义的参数写成列向量存储进去,如所有训练样本的输入特征。
第一层隐藏层计算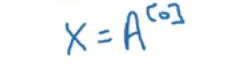
因为X=A^ [0],所以下图中的X可以替换为A^ [0]。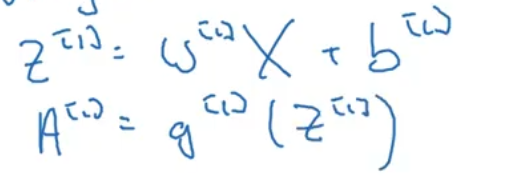
第二层隐藏层计算
其他层的计算类似,可以逐渐递推。
核对矩阵的维数
下图中,除去输入层X,L=5,叫五层神经网络,有四层隐藏层。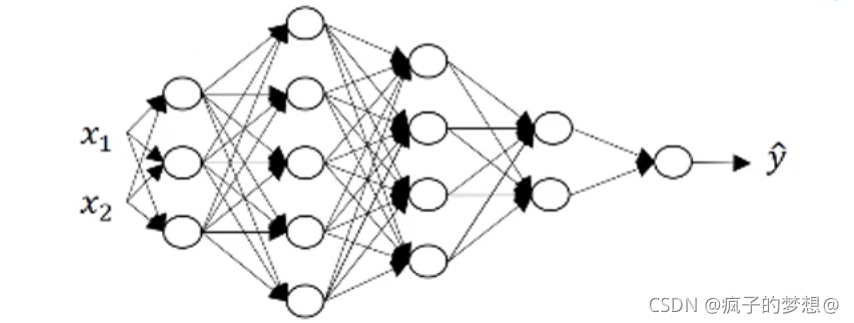 我们现在根据下图的公式,我们已知第一层隐藏层有三个隐藏单元。
我们现在根据下图的公式,我们已知第一层隐藏层有三个隐藏单元。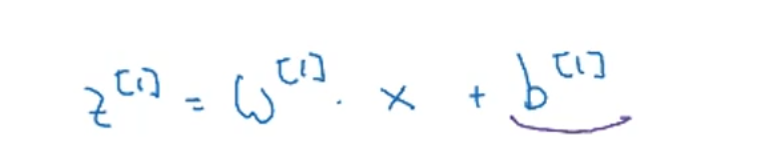
对于单个样本来说:z是第一隐藏层的激活函数的输入,所以这里的维度是(3,1),输入特征x在这里有两个,所以x的维度是(2,1),所以我们需要w乘以x得到z,(2,1)维度的矩阵x乘以(?,?)维度的w才能得到(3,1)维度的z,就是我们需要核对的。根据矩阵乘法运算法则,我们需要w的维度是(3,2)。所以在计算的时候 我们推出一个w矩阵维度的通式:
计算第l层时 ,w ^ [l]:(n^ [l],n^ [l-1])。
b是一个常数值,我们看第一层,因为z是(3,1)维度,那么矩阵相加的法则,b必须也是(3,1)的维度才能相加。所以推出一个b矩阵维度的通式,在计算第l层的时候,b^ [l]:(n^ [l],1)。
注意:实现反向传播的时候,dw应该和w有相同的维度,db和b有相同的维度。
因为a=g(z),所以A的维度应该和Z的维度相同。g()是激活函数。A和Z的维度在计算前后可能会发生变化。
对于m个训练样本,Z的维度(n[l],m),w的维度(n[l],n[l-1]),b的维度(n[l],m)。
为什么用深度神经网络
深度网络在计算什么,比如在人脸检测时,第一层可以当做一个特征探测器,或者边缘探测器,即去找人脸图的照片边缘。然后第二层,我们把找到的边缘组合,组成要检测的面部的图像,比如说第二层的一个隐藏单元找眼睛部分,一个单元在找鼻子部分,第三层,在把这些人体的部位组合在一起,最后输出层(第四层)就可以探测不同的人脸。
在深层神经网络中,前几层都是做一些简单任务,然后后几层,把一些简单的结果组合起来,就实现了复杂任务。
搭建深层神经网络块
这是一个深层神经网络,我们从蓝框圈出的这一层计算入手。
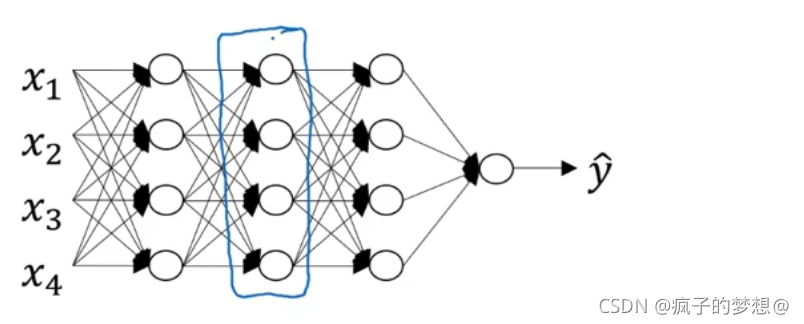
在这一层,假设是第l层,我们有参数w【l】,b【l】,正向传播输入的激活函数,其输入的前一层是a【l-1】,其激活函数输出是a【l】。还有如下两个通式:
z【l】=w【l】*a【l-1】+b【l】
a【l】=g【l】(z【l】)
我们还要把z【l】的值缓存起来,因为在后续的正向和反向传播中有非常重要的作用。
在反向传播中,我们有输入da【l】产生da【l-1】。
下图是深层神经网络训练的计算过程,共有两行方框,那么每一列的方框表示一层神经网络。其中各个参数的中括号内的数为该层神经网络的层数,如z【2】表示第二层神经网络的参数。第一行是正向传播,第二行是反向传播。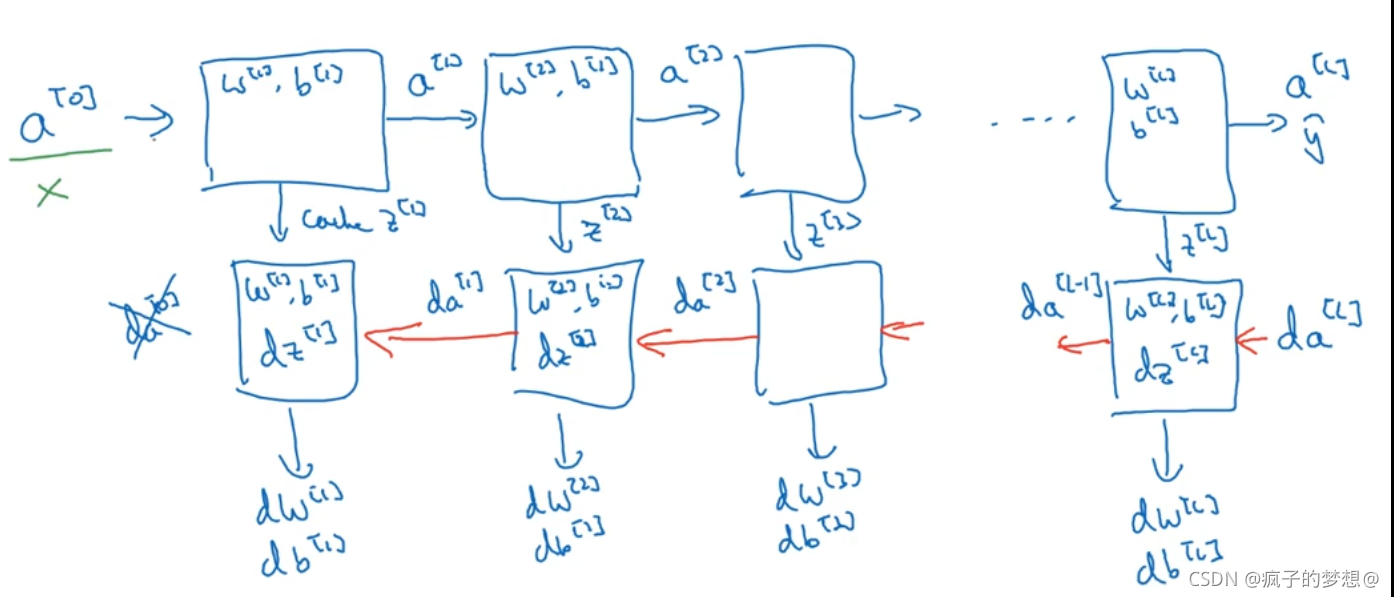
反向传播计算出的dw和db,被用做下边的通式来更新参数:
w【l】=w【l】-αdw【l】,这里的α我们设定为学习率,可以设定为一个常数。
b【l】=b【l】-αdb【l】。
注意:神经网络正向传播时得到的z【l】要缓存下来,是有重要意义的,比如可以存储进入矩阵中。
实现前向和反向传播
在前向传播中,我们输入a【l-1】,输出a【l】,缓存z【l】。也可以把w【l】和b【l】缓存。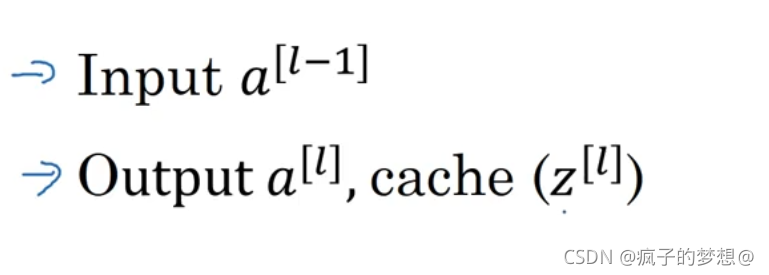
向量化的实现步骤,其中的Z,W,A,b都是矩阵。A【l-1】=A【0】的时候,这个A【0】就是我们的输入层的输入特征。
在反向传播中我们输入da【l】,输出da【l-1】,dw【l】,db【l】。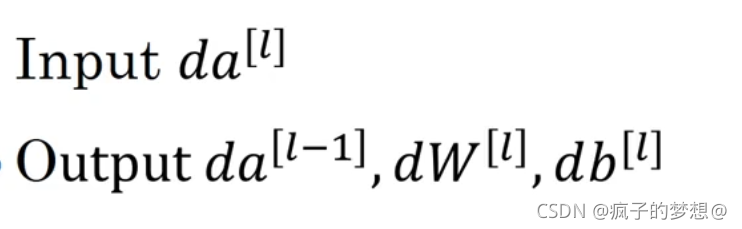
反向传播的过程,其实就是一个求导的过程,如下所示,其中的w ^ [l]T表示矩阵w^ [l]的转置。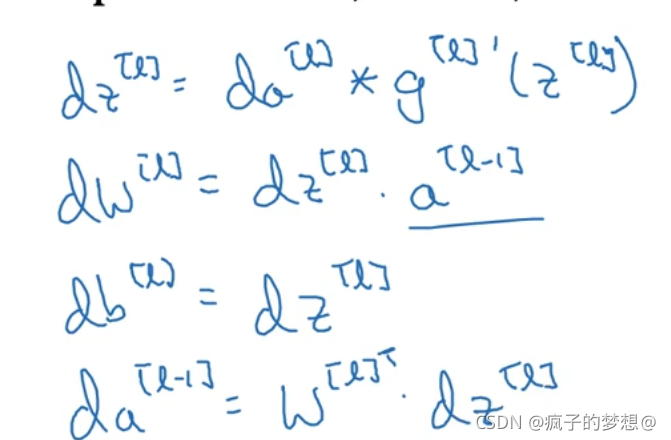
参数和超参数
超参数:比如学习率α,隐藏层数L,隐藏单元数,激活函数,循环的数量。
下图中是参数: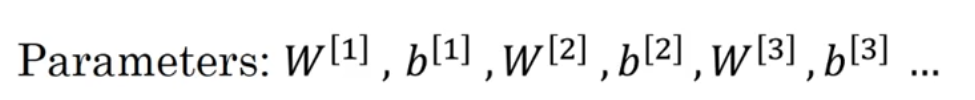
如何设定超参数的值,比如学习率α,我们可以试着设置比如0.1,然后看成本函数J的值居然发散升高了,那么我们可以尝试降低学习率α,或者升高α,继续观看成本函数J,直到他有收敛降低的趋势,定下此时的α。
提示:当开发新应用的时候,我们对于超参数的设置可能凭借经验来,但多数情况下还是不断的去尝试一些数值,慢慢的改变修正。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)