递归神经网络简介
把它想象成读一个句子,当你试图预测下一个单词时,你不仅要看当前的单词,还需要记住前面的单词才能做出准确的猜测。与传统的深度神经网络不同,每个密集层都有不同的权重矩阵,而 RNN 跨时间步使用共享权重,使它们能够记住序列中的信息。这种设计计算效率很高,通常与 LSTM 的性能类似,并且在简单性和快速训练有益的任务中非常有用。在展开过程中,序列的每个步骤都表示为序列中的一个单独层,用于说明信息如何在每
递归神经网络 (RNN) 的工作方式与常规神经网络略有不同。在神经网络中,信息从输入流向输出。然而,在 RNN 中,信息在每个步骤后都会反馈到系统中。把它想象成读一个句子,当你试图预测下一个单词时,你不仅要看当前的单词,还需要记住前面的单词才能做出准确的猜测。
RNN 允许网络通过将一个步骤的输出馈送到下一步来“记住”过去的信息。 这有助于网络了解已经发生的事情的背景,并基于此做出更好的预测。 例如,在预测句子中的下一个单词时,RNN 使用前面的单词来帮助确定哪个单词最有可能出现在下一个单词。

递归神经网络
此图展示了 RNN 的基本架构和反馈回路机制,其中输出作为下一个时间步的输入传回。
RNN 与前馈神经网络有何不同?
前馈神经网络 (FNN) 从输入到输出沿一个方向处理数据,而不保留先前输入的信息。这使得它们适用于具有独立输入的任务,例如图像分类。但是,由于 FNN 缺乏内存,因此难以处理顺序数据。
递归神经网络 (RNN) 通过整合循环来解决这个问题,这些循环允许将前面步骤的信息反馈到网络中。这种反馈使 RNN 能够记住之前的输入,使其成为上下文很重要的任务的理想选择。
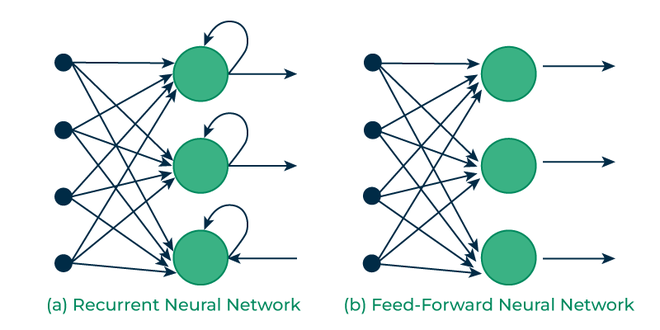
递归与前馈网络
RNN 的关键组成部分
1. 复发神经元
RNN 中的基本处理单元是循环单元。 Recurrent units 具有隐藏状态,用于维护有关序列中先前 Importing 的信息。递归单元可以通过反馈其隐藏状态来“记住”先前步骤中的信息,从而允许它们捕获跨时间的依赖关系。
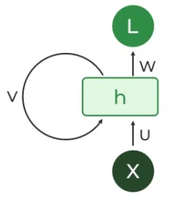
Recurrent Neuron
2. RNN 展开
RNN 展开或展开是随时间步长扩展循环结构的过程。在展开过程中,序列的每个步骤都表示为序列中的一个单独层,用于说明信息如何在每个时间步中流动。
这种展开实现了时间反向传播 (BPTT),这是一个学习过程,其中错误跨时间步传播以调整网络的权重,从而增强 RNN 学习顺序数据中依赖关系的能力。
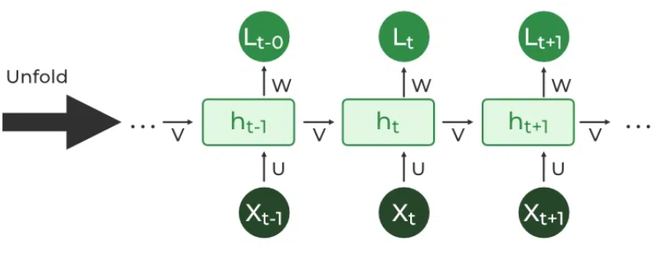
RNN 展开
递归神经网络架构
RNN 在输入和输出结构方面与其他深度学习架构有相似之处,但在信息从输入流向输出的方式上却有很大不同。与传统的深度神经网络不同,每个密集层都有不同的权重矩阵,而 RNN 跨时间步使用共享权重,使它们能够记住序列中的信息。
在 RNN 中,隐藏状态H我H我针对每个输入进行计算X我X我以保留顺序依赖关系。计算遵循以下核心公式:
1. 隐藏状态计算:
![]()
这里hh表示当前隐藏状态,UU和WW是权重矩阵,而BB是偏差。
2. 输出计算:
Y=O(V⋅h+C)
输出YY是通过应用OO,激活函数,设置为加权隐藏状态,其中VV和CC表示权重和偏差。
3. 整体功能:
Y=f(X,h,W,U,V,B,C)
此函数定义整个 RNN作,其中状态矩阵SS保存每个元素s我s我表示每个时间步的网络状态我我.
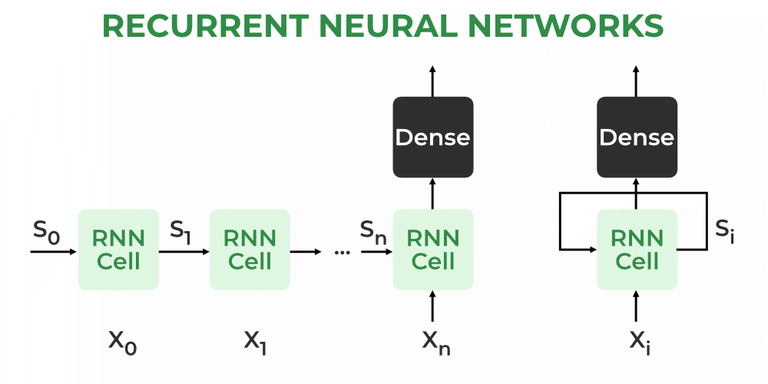
递归神经架构
RNN 的工作原理是什么?
在每个时间步 RNN 处理具有固定激活函数的单元。这些单元具有内部隐藏状态,该状态充当内存,用于保留先前时间步长的信息。这种内存允许网络存储过去的知识并根据新的输入进行调整。
更新 RNN 中的 Hidden 状态
当前隐藏状态ht取决于之前的状态ht−1和电流输入xt,并使用以下关系进行计算:
1. 状态更新:
![]()
哪里:
- ht是当前状态
- ht−1是以前的状态
- xt是当前时间步长的输入
2. 激活函数应用:
![]()
这里WhhWHH是循环神经元的权重矩阵,并且WxhWxh是输入神经元的权重矩阵。
3. 输出计算:
yt=Why⋅ht
哪里yt是输出,而Why哎呀是输出层的权重。
这些参数使用反向传播进行更新。但是,由于 RNN 处理顺序数据,因此我们使用更新的反向传播,这称为时间反向传播。
RNN 中的时间反向传播 (BPTT)
由于 RNN 处理顺序数据,因此使用时间反向传播 (BPTT) 来更新网络的参数。损失函数 L(θ) 取决于最终的隐藏状态 h3并且每个隐藏状态都依赖于前面的状态,形成一个连续的依赖链:
h3 取决于 h2 ,h2取决于 h1,…,h1 取决于 h0取决于h2,h2取决于h1,...、h1取决于h0.

RNN 中的时间反向传播 (BPTT)
在 BPTT 中,梯度在每个时间步长中反向传播。这对于根据时态依赖关系更新网络参数至关重要。
- 简化的梯度计算:
![]()
- 处理 Layers 中的依赖:
每个隐藏状态都会根据其依赖进行更新:
h3=σ(W⋅h2+b) - 然后计算每个状态的梯度,考虑先前隐藏状态的依赖关系。
- Gradient Calculation with Explicit and Implicit Parts(具有显式和隐式部分的梯度计算):梯度被分解为显式和隐式部分,以总结从每个隐藏状态到权重的间接路径。
∂h3∂W=∂h3+∂W+∂h3∂h2⋅∂h2+∂W∂W∂h3=∂W∂h3++∂h2∂h3⋅∂W∂h2+
![]()
最终梯度表达式:
计算损失函数关于权重矩阵 W 的最终导数:
![]()
这个迭代过程是随时间反向传播的本质。
递归神经网络的类型
根据网络中输入和输出的数量,有四种类型的 RNN:
1. 一对一 RNN
这是最简单的神经网络架构类型,其中有单个输入和单个输出。它用于简单的分类任务,例如不涉及顺序数据的二元分类。

一对一 RNN
2. 一对多 RNN
在一对多 RNN 中,网络处理单个输入,以随着时间的推移产生多个输出。这在一个输入触发一系列预测(输出)的任务中非常有用。例如,在图像字幕中,可以将单个图像用作输入,以生成单词序列作为字幕。

一对多 RNN
3. 多对一 RNN
多对一 RNN 接收一系列输入并生成单个输出。当需要 input sequence 的整体上下文来进行一次预测时,此类型非常有用。在情感分析中,模型接收一系列单词(如句子)并生成单个输出,如 positive、negative 或 neutral。

多对一 RNN
4. 多对多 RNN
多对多 RNN 类型处理一系列输入并生成一系列输出。在语言翻译任务中,一种语言的单词序列作为输入,并生成另一种语言的相应序列作为输出。

多对多 RNN
递归神经网络 (RNN) 的变体
RNN 有几种变体,每种变体都旨在解决特定挑战或针对特定任务进行优化:
1. 原版 RNN
这种最简单的 RNN 形式由一个隐藏层组成,其中权重在时间步长之间共享。原版 RNN 适用于学习短期依赖关系,但受到梯度消失问题的限制,这阻碍了长序列学习。
2. 双向 RNN
双向 RNN 处理正向和反向的输入,捕获每个时间步的过去和未来上下文。此体系结构非常适合整个序列可用的任务,例如命名实体识别和问答。
3. 长短期记忆网络 (LSTM)
长短期记忆网络 (LSTM) 引入了一种记忆机制来克服梯度消失问题。每个 LSTM 单元都有三个门:
- Input Gate:控制应向 cell 状态添加多少新信息。
- Forget Gate:决定应该丢弃哪些过去的信息。
- Output Gate(输出门):调节当前步长应输出的信息。这种选择性内存使 LSTM 能够处理长期依赖关系,使其成为早期上下文至关重要的任务的理想选择。
4. 门控循环单元 (GRU)
门控循环单元 (GRU) 通过将输入门和遗忘门组合到单个更新门中并简化输出机制来简化 LSTM。这种设计计算效率很高,通常与 LSTM 的性能类似,并且在简单性和快速训练有益的任务中非常有用。
使用递归神经网络 (RNN) 实现文本生成器
在本节中,我们使用 TensorFlow 和 Keras 中的递归神经网络 (RNN) 创建一个基于字符的文本生成器。我们将实现一个 RNN,它从文本序列中学习模式,以逐个字符生成新的文本。
第 1 步:导入必要的库
我们首先导入用于数据处理和构建神经网络的基本库。
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import SimpleRNN, Dense 第 2 步:定义输入文本并准备字符集
我们定义输入文本并识别文本中的唯一字符,我们将为模型编码这些字符。
text = "This is GeeksforGeeks a software training institute" chars = sorted(list(set(text))) char_to_index = {char: i for i, char in enumerate(chars)} index_to_char = {i: char for i, char in enumerate(chars)} 第 3 步:创建序列和标签
为了训练 RNN,我们需要固定长度的序列 () 和每个序列后面的字符作为标签。seq_length
seq_length = 3 sequences = [] labels = [] for i in range(len(text) - seq_length): seq = text[i:i + seq_length] label = text[i + seq_length] sequences.append([char_to_index[char] for char in seq]) labels.append(char_to_index[label]) X = np.array(sequences) y = np.array(labels) 第 4 步:将序列和标签转换为 One-Hot 编码
对于训练,我们将 和 转换为 one-hot 编码张量。Xy
X_one_hot = tf.one_hot(X, len(chars)) y_one_hot = tf.one_hot(y, len(chars))
第 5 步:构建 RNN 模型
我们创建了一个简单的 RNN 模型,其中包含一个 50 个单元的隐藏层和一个具有 softmax 激活的 Dense 输出层。
model = Sequential() model.add(SimpleRNN(50, input_shape=(seq_length, len(chars)), activation='relu')) model.add(Dense(len(chars), activation='softmax')) 第 6 步:编译和训练模型
我们使用损失编译模型 并训练 100 个 epoch。categorical_crossentropy
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_one_hot, y_one_hot, epochs=100) 输出:
纪元 1/100
2/2 ━━━━━━━━━━━━━━━━━━━━ 4s 23ms/步 – 精度:0.0243 – 损失:2.9043
纪元 2/100
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/步 – 精度:0.0139 – 损失:2.8720
纪元 3/100
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 10ms/步 – 精度:0.0243 – 损失:2.8454。
。
。
纪元 99/100
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/步 – 精度:0.8889 – 损耗:0.5060
Epoch 100/100
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/步 – 精度:0.9236 – 损耗:0.4934
第 7 步:使用经过训练的模型生成新文本
训练后,我们使用起始序列逐个字符生成新的文本。
start_seq = "This is G" generated_text = start_seq for i in range(50): x = np.array([[char_to_index[char] for char in generated_text[-seq_length:]]]) x_one_hot = tf.one_hot(x, len(chars)) prediction = model.predict(x_one_hot) next_index = np.argmax(prediction) next_char = index_to_char[next_index] generated_text += next_char print("Generated Text:") print(generated_text) 输出:
生成的文本:This is Geeks a software training instituteais is is is
完整代码
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import SimpleRNN, Dense text = "This is GeeksforGeeks a software training institute" chars = sorted(list(set(text))) char_to_index = {char: i for i, char in enumerate(chars)} index_to_char = {i: char for i, char in enumerate(chars)} seq_length = 3 sequences = [] labels = [] for i in range(len(text) - seq_length): seq = text[i:i + seq_length] label = text[i + seq_length] sequences.append([char_to_index[char] for char in seq]) labels.append(char_to_index[label]) X = np.array(sequences) y = np.array(labels) X_one_hot = tf.one_hot(X, len(chars)) y_one_hot = tf.one_hot(y, len(chars)) model = Sequential() model.add(SimpleRNN(50, input_shape=(seq_length, len(chars)), activation='relu')) model.add(Dense(len(chars), activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_one_hot, y_one_hot, epochs=100) start_seq = "This is G" generated_text = start_seq for i in range(50): x = np.array([[char_to_index[char] for char in generated_text[-seq_length:]]]) x_one_hot = tf.one_hot(x, len(chars)) prediction = model.predict(x_one_hot) next_index = np.argmax(prediction) next_char = index_to_char[next_index] generated_text += next_char print("Generated Text:") print(generated_text) 递归神经网络的优势
- 顺序内存:RNN 保留来自先前输入的信息,使其成为过去数据至关重要的时间序列预测的理想选择。此功能通常称为长短期记忆 (LSTM)。
- 增强的像素邻域:RNN 可以与卷积层相结合,以捕获扩展的像素邻域,从而提高图像和视频数据处理的性能。
递归神经网络 (RNN) 的局限性
虽然 RNN 擅长处理顺序数据,但它们面临两个主要的训练挑战,即梯度消失和梯度爆炸问题:
- 消失梯度:在反向传播期间,梯度在通过每个时间步长时会减小,从而导致权重更新最小。这限制了 RNN 学习长期依赖关系的能力,这对于语言翻译等任务至关重要。
- 梯度爆炸:有时,梯度不受控制地增长,导致过大的权重更新,从而破坏训练的稳定性。渐变剪裁是解决此问题的常用技术。
这些挑战会阻碍标准 RNN 在复杂的长序列任务上的性能。
递归神经网络的应用
RNN 用于数据顺序或基于时间的各种应用程序:
- 时间序列预测:RNN 擅长预测任务,例如股票市场预测和天气预报。
- 自然语言处理 (NLP):RNN 是语言建模、情感分析和机器翻译等 NLP 任务的基础。
- 语音识别:RNN 捕获语音数据中的时间模式,有助于语音转文本和其他与音频相关的应用程序。
- 图像和视频处理:当与卷积层结合使用时,RNN 有助于分析视频序列、面部表情和手势识别。
有关递归神经网络的常见问题 (FAQ)
RNN 可以解决哪类问题?
使用递归神经网络可以对瞬态和顺序数据问题进行建模,例如文本生成、机器翻译和股票市场预测。然而,你会发现梯度问题使 RNN 难以训练。梯度消失问题会影响 RNN。
RNN 有哪些类型?
RNN 有四种类型:
- 一对一
- 一对多
- 多对一
- 多对多
RNN 和 CNN 有什么区别?
以下是 CNN 和 RNN 之间的主要区别:CNN 经常用于解决涉及空间数据的问题,例如图像。RNN 可以更好地分析时间上和顺序组织的文本和视频数据。RNN 和 CNN 的设计并不相同。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)