使用bert实现中文情感分析
【代码】使用bert实现中文情感分析。
·
from transformers import BertModel
import torch
DEVICE=torch.device("cuda" if torch.cuda.is_available() else "cpu")
pretrained = BertModel.from_pretrained("bert-base-chinese").to(DEVICE)
print(pretrained.encoder)
# 定义下游任务将主干网络提取的特征进行分类
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.linear(768,2)
def forward(self,inputs_ids,attention_mask,token_type_ids):
# 上游任务不参与训练
with toech.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
# 下游任务参与训练
out = self.fc(out.last.hidden_state[:,0])
out = out.softmax(dim=1)
return out

from torch.utils.data import Dataset
from datasets import load_from_disk
class Mydataset(Dataset):
# 初始化数据
def __init__(self,split):
self.dataset= load_from_disk(r'/kaggle/input/huggingface/demo_15/data/ChnSentiCorp')
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset['test']
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据集名称错误")
#获取数据集大小
def __len__(self):
return len(self.dataset)
#对数据做定制化处理
def __getitem__(self,item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
# 数据示例
# {"text:"你这俄格啥子","label":"0"}
if __name__ == "__main__":
dataset = Mydataset("validation")
print(dataset)
for data in dataset:
print(data)
print(len(dataset))

import torch
import os
from transformers import BertTokenizer
from transformers import BertModel
from torch.utils.data import DataLoader
from torch.optim import AdamW
os.makedirs("params",exist_ok=True)
# from torch.utils.data import Dataset
# from mydata.py import Mydataset
class Mydataset(Dataset):
# 初始化数据
def __init__(self,split):
self.dataset= load_from_disk(r'/kaggle/input/huggingface/demo_15/data/ChnSentiCorp')
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset['test']
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据集名称错误")
#获取数据集大小
def __len__(self):
return len(self.dataset)
#对数据做定制化处理
def __getitem__(self,item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
# 数据示例
# {"text:"你这俄格啥子","label":"0"}
# from net import Model
DEVICE=torch.device("cuda" if torch.cuda.is_available() else "cpu")
pretrained = BertModel.from_pretrained("bert-base-chinese").to(DEVICE)
print(pretrained.encoder)
# 定义下游任务将主干网络提取的特征进行分类
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768,2)
def forward(self,inputs_ids,attention_mask,token_type_ids):
# 上游任务不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
# 下游任务参与训练
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
EPOCH=100
token = BertTokenizer.from_pretrained("bert-base-chinese")
# 自定义函数,对数据进行编码处理
def collate_fn(data):
sentes = [i[0] for i in data]
label = [i[1] for i in data]
data = token.batch_encode_plus(
batch_text_or_text_pairs=sentes,
truncation=True,
padding = "max_length",
max_length=350,
return_tensors='pt',
return_length=True
)
input_ids=data['input_ids']
attention_mask=data['attention_mask']
token_type_ids =data['token_type_ids']
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
train_dataset = Mydataset("train")
train_loader= DataLoader(train_dataset,batch_size=32,shuffle=True,collate_fn=collate_fn) # Added shuffle=True
if __name__ == "__main__":
print(DEVICE)
model = Model().to(DEVICE)
optimizer= AdamW(model.parameters(),lr=5e-4)
loss_func = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(EPOCH):
for i ,(input_ids,attention_mask,token_type_ids,labels) in enumerate(train_loader):
input_ids,attention_mask,token_type_ids,labels = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),labels.to(DEVICE)
# 执行前向计算得到输出
out = model(input_ids,attention_mask,token_type_ids)
loss = loss_func(out,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%5==0:
out = out.argmax(dim=1)
acc = (out==labels).sum().item()/len(labels)
print(epoch,i,loss.item(),acc)
# 保存模型参数
torch.save(model.state_dict(),f"params/{epoch}bert.pt")
print(epoch,"参数保存成功") 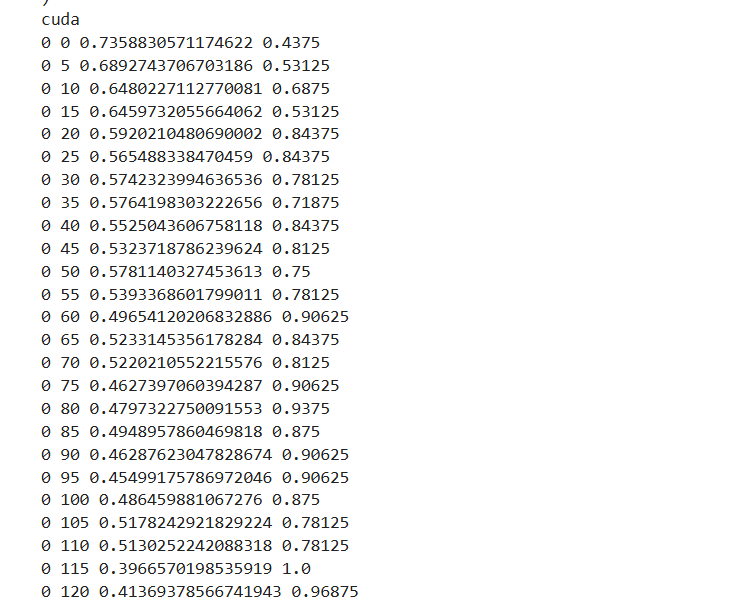
import torch
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoader
from torch.optim import AdamW
class Mydataset(Dataset):
# 初始化数据
def __init__(self, split):
self.dataset = load_from_disk(r'/kaggle/input/huggingface/demo_15/data/ChnSentiCorp')
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset['test']
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据集名称错误")
# 获取数据集大小
def __len__(self):
return len(self.dataset)
# 对数据做定制化处理
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text, label
# 定义下游任务将主干网络提取的特征进行分类
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
# 上游任务不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 下游任务参与训练
out = self.fc(out.last_hidden_state[:, 0])
out = out.softmax(dim=1)
return out
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pretrained = BertModel.from_pretrained("bert-base-chinese").to(DEVICE)
EPOCH = 100
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
# 自定义函数,对数据进行编码处理
def collate_fn(data):
sentences = [i[0] for i in data]
labels = [i[1] for i in data]
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sentences,
truncation=True,
padding="max_length",
max_length=350,
return_tensors='pt',
return_length=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return input_ids, attention_mask, token_type_ids, labels
train_dataset = Mydataset("test")
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
if __name__ == "__main__":
acc = 0 # 初始化为整数
total = 0 # 初始化为整数
print(DEVICE)
model = Model().to(DEVICE)
model.load_state_dict(torch.load("params/1bert.pt", weights_only=True))
model.eval()
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(train_loader):
input_ids, attention_mask, token_type_ids, labels = input_ids.to(DEVICE), attention_mask.to(DEVICE), token_type_ids.to(DEVICE), labels.to(DEVICE)
# 执行前向计算得到输出
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
acc += (out == labels).sum().item() # 确保 acc 是整数
total += len(labels)
print(acc / total)
import torch
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoader
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
# 上游任务不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 下游任务参与训练
out = self.fc(out.last_hidden_state[:, 0])
out = out.softmax(dim=1)
return out
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pretrained = BertModel.from_pretrained("bert-base-chinese").to(DEVICE)
EPOCH = 100
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
from transformers import BertTokenizer
DEVICE =torch.device("cuda" if torch.cuda.is_available() else"cpu")
names = ['负向评价','正向评价']
print(DEVICE)
model = Model().to(DEVICE)
token = BertTokenizer.from_pretrained("bert-base-chinese")
# 自定义函数,对数据进行编码处理
def collate_fn(data):
sentences = []
sentences.append(data)
data = token.batch_encode_plus(
batch_text_or_text_pairs=sentences,
truncation=True,
padding="max_length",
max_length=350,
return_tensors='pt',
return_length=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
# labels = torch.LongTensor(labels)
return input_ids, attention_mask, token_type_ids, labels
# def test():
# model.load_state_dict(torch.load("params/2bert.pt"))
# model.eval()
# while True:
# data = input("请输入测试数据(输入"q"退出):")
# if data =='q':
# print("测试结束")
# break
# input_ids,attention_mask,token_type_ids = collate_fn(data)
# input_ids,attention_mask,token_type_ids= input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE)
# with torch.no_grad():
# out = model(inputs_ids,attention_mask,token_type_ids)
# out = out.argmax(dim=1)
# print("模型判定:",names[out],"\n")
def test():
model.load_state_dict(torch.load("params/1bert.pt")) # 修正拼写错误
model.eval()
while True:
data = input("请输入测试数据(输入'q'退出): ") # 修正引号
if data == 'q':
print("测试结束")
break
# 将输入数据转换为模型可以处理的格式
inputs = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[data],
truncation=True,
padding="max_length",
max_length=350,
return_tensors='pt'
)
input_ids = inputs['input_ids'].to(DEVICE)
attention_mask = inputs['attention_mask'].to(DEVICE)
token_type_ids = inputs['token_type_ids'].to(DEVICE)
with torch.no_grad():
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
print(f"模型判定: {names[out.item()]}\n") # 修正打印语句
if __name__=="__main__":
test()


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)