

深度学习 下采样层
说明 (Explanation)
Convolutional Neural Networks (CNN) have characteristics that enable invariance to the affine transformations of images that are fed through the network. This provides the ability to recognize patterns that are shifted, tilted or slightly warped within images.
卷积神经网络(CNN)具有使通过网络馈送的图像的仿射变换具有不变性的特征。 这提供了识别图像中偏移,倾斜或略微扭曲的图案的能力。
These characteristics of affine invariance are introduced due to three main properties of the CNN architecture.
仿射不变性的这些特征是由于CNN架构的三个主要属性而引入的。
-
Spatial Sub-sampling
空间子采样
In this article, we’ll be exploring spatial sub-sampling and understanding their purpose and the advantages they serve within CNN architectures.
在本文中,我们将探索空间子采样,并了解它们的目的以及它们在CNN架构中的优势。
This article is aimed at all levels of individuals that practice machine learning or more specifically deep learning.
本文针对从事机器学习或更具体地讲深度学习的所有层次的个人。
介绍 (Introduction)
Sub-sampling is a technique that has been devised to reduce the reliance of precise positioning within feature maps that are produced by convolutional layers within a CNN.
二次采样是一种旨在减少对CNN中卷积层产生的特征图内精确定位的依赖的技术。
CNN internals contains kernels/filters of fixed dimensions, and these are referred to as feature detectors. Once features from an image are detected, the information in regards to the position of the feature within the image can actually be disregarded, and there are benefits to this.
CNN内部包含固定尺寸的内核/过滤器,这些被称为特征检测器。 一旦检测到图像中的特征,实际上就可以忽略关于特征在图像中的位置的信息,这是有好处的。
It turns out that specific feature positioning reliance is a disadvantage to building and developing a network that can perform relatively well on input data that have undergone some form of an affine transformation. We mostly don’t want the weights within the networks learning patterns that are too specific to the training data.
事实证明,特定特征定位依赖对构建和开发可以对经过某种形式的仿射变换的输入数据执行相对较好的网络是不利的。 我们大多不希望网络学习模式中的权重过于特定于训练数据。
So, the information that matters in terms of positioning of features is the relative position of a feature to other features within the feature map, as opposed to the exact location of the feature within the feature map.
因此,与特征定位有关的重要信息是特征与特征图中其他特征的相对位置,而不是特征在特征图中的确切位置。
To reduce the reliance on the exact positioning of features within networks, the reduction of spatial resolution is undertaken.
为了减少对网络中要素的精确定位的依赖,降低了空间分辨率。
Spatial resolution reduction is merely reducing the number of pixels within the feature map, and in this case, this is achieved through sub-sampling.
空间分辨率的降低只是减少了特征图中的像素数量,在这种情况下,这是通过子采样实现的。
Sub-sampling is incorporated within CNN by adding a sub-sampling layer where each unit within the layer has a receptive field of a fixed size that is imposed on the input (feature maps from previous layer), where an operation is performed on the pixels that are in the scope of the receptive field of the unit, the result of the operations becomes the new value of the output from the subsampling layer.
通过添加子采样层将子采样合并到CNN中,其中该层中的每个单元都有一个固定大小的接收场,该接收场被施加到输入上(来自上一层的特征图),其中对像素执行操作在单元接受域范围内,运算结果将成为子采样层输出的新值。
Sub-sampling is a method to downsample feature maps as we move along the network
子采样是一种随着我们在网络上移动而对特征图进行下采样的方法
平均池化 (Average Pooling)
Average pooling is a variant of sub-sampling where the average of pixels that fall within the receptive field of a unit within a sub-sampling layer is taken as the output.
平均池化是子采样的一种变体,其中,将子采样层内某个单元的接收场内的像素平均值作为输出。
Below is a depiction of average pooling.
以下是平均池化的描述。
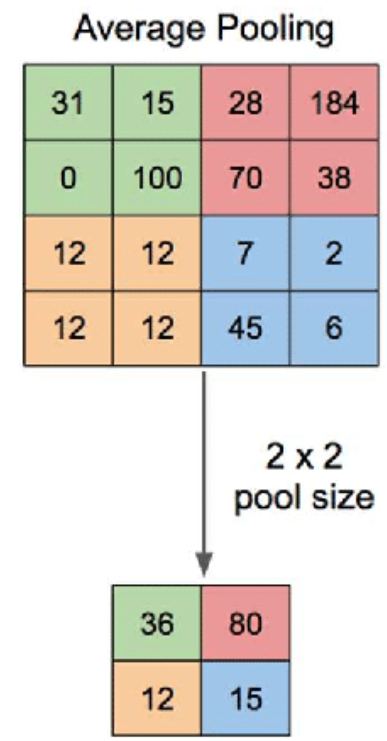
The average pooling operation above has a window of 2x2 and slides across the input data, outputting an average of the pixels within the receptive field of the kernel.
上面的平均池化操作具有2x2的窗口,并且在输入数据上滑动,输出内核接受域内像素的平均值。
Below is a snippet of code that utilizes TensorFlow deep learning library to implement an average pooling layer.
以下是利用TensorFlow深度学习库来实现平均池化层的代码片段。
import tensorflow as tfaverage_pooling = tf.keras.layers.AveragePooling2D( pool_size=(2, 2), strides=None, padding='valid')I won’t dive into too many details of the code snippet above, as it’s outside the scope of this article. But below are some necessary information:
我不会在上面的代码片段中介绍太多细节,因为它不在本文的讨论范围之内。 但是下面是一些必要的信息:
-
The average pooling layer is created using the class constructor of the ‘AveragePooling2D’ class. The constructor takes some arguments.
平均池层是使用“ AveragePooling2D ”类的类构造函数创建的。 构造函数接受一些参数。
-
Pool size is the dimensions of the sliding window that performs the averaging operation within pixel values that falls within it. The tuple (2,2) subsequently halves the input data
池大小是滑动窗口的尺寸,该滑动窗口在其内的像素值内执行平均操作。 元组(2,2)随后将输入数据减半
-
Stride indicate the amount the pooling window moves across the input data after the evaluation of each pooling operation. The value ‘None’ that is assigned to it means that the stride value will take the default value of the pool size.
大步表示在评估每个合并操作之后,合并窗口在输入数据上移动的数量。 为其分配的值“无”表示跨步值将采用池大小的默认值。
最大池 (Max Pooling)
Max pooling is a variant of sub-sampling where the maximum pixel value of pixels that fall within the receptive field of a unit within a sub-sampling layer is taken as the output.
最大池化是子采样的一种变体,其中将处于子采样层内某个单元的接收域内的像素的最大像素值作为输出。
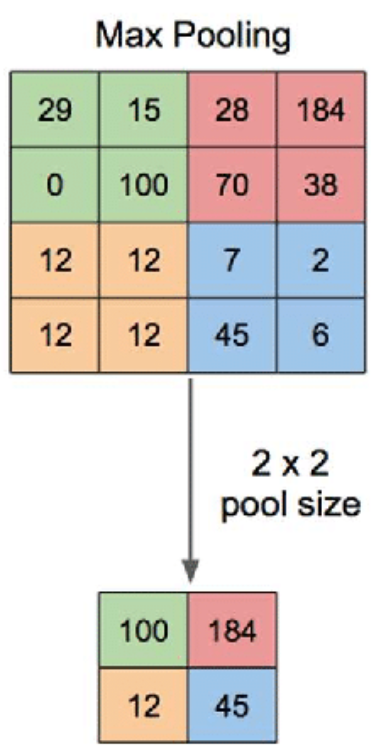
The max-pooling operation below has a window of 2x2 and slides across the input data, outputting an average of the pixels within the receptive field of the kernel.
下面的最大池化操作具有2x2的窗口,并在输入数据上滑动,输出内核接受域内像素的平均值。
import tensorflow as tf
tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=None, padding='valid')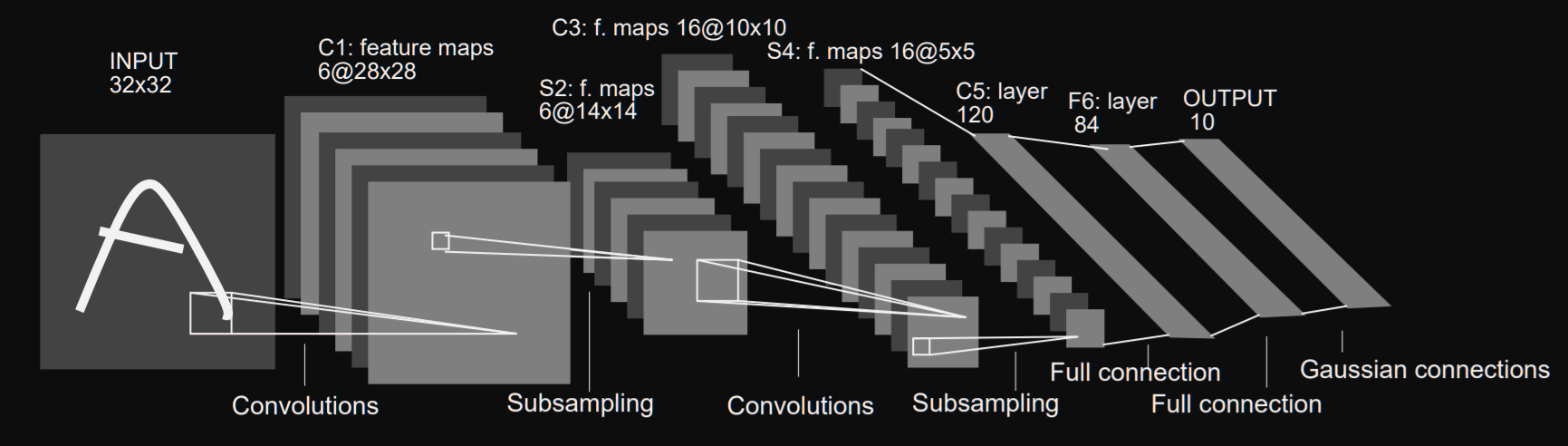
The first sub-sampling layer is identified in the image above by the label ‘S2’, and it’s the layer just after the first conv layer (C1).
上图中的第一子采样层由标签“ S2 ”标识,它是紧靠第一转换层( C1 )的层。
From the diagram, we can observe that the sub-sampling layer produces six feature map output with the dimensions 14x14, each feature map produced by the ‘S2’ sub-sampling layer corresponds to a feature map produced by the ‘C1’ layer.
从图中可以看出,子采样层产生了六个尺寸为14x14的特征图输出, “ S2”子采样层产生的每个特征图对应于“ C1”层产生的特征图。
This is a pattern that we observe through the architecture of the LeNet-5 as other sub-sampling layers produce feature maps equal to the number of feature maps produced by the previous conv layer.
这是我们在LeNet-5架构中观察到的一种模式,因为其他子采样层产生的特征图等于上一个conv层产生的特征图的数量。
The sub-sampling variant that the layer ‘S2’ utilizes is an average pooling. As described earlier, the units within the sub-sampling layer all have a receptive field of 2x2, which subsequently corresponds to the pool size, in the implementation example given above. When values fall within the 2x2 pooling kernel, an average of the four numbers within the kernel is used as an output.
层“ S2 ”利用的子采样变体是平均池。 如前所述,在上面给出的实施例中,子采样层内的单元都具有2x2的接收场,该接收场随后对应于池大小。 当值落在2x2池内核中时,内核中四个数字的平均值将用作输出。
As we proceed through the layers within LeNet-5, we reach a second sub-sampling layer ‘S4, and this layer has more feature maps than ‘S2’, a total of 16 feature maps is outputted by the ‘S4’ sub-sampling layer.
当我们遍历LeNet-5中的各层时,我们到达第二个子采样层' S4,并且该层具有比' S2 '更多的特征图,' S4'子采样总共输出了16个特征图层。
Noticeably the dimensions(5x5) of the feature maps are much smaller than features maps from the previous conv layers(10x10), this is due to the fact that as the input data is fed-foward through the network, sub-sampling layer averaging (2x2) pool size halves the dimensions of the feature maps it receives as input. This is known as downsampling.
值得注意的是,特征图的尺寸(5x5)比之前的conv层(10x10)的特征图小得多,这是由于以下事实:当输入数据通过网络前馈时,子采样层平均( 2x2)池大小将其接收为输入的要素地图的尺寸减半。 这称为下采样。
A reduction of the feature maps sizes(downsampling) as we move through the network enables the possibility of reducing the spatial resolution of the feature map. You might be thinking this technique is counterintuitive to ensuring the features within the feature maps contain enough detailed patterns to learn.
随着我们在网络中移动,减少特征图的大小( 下采样 )可以降低特征图的空间分辨率。 您可能会认为此技术与确保要素图中的要素包含足够的详细模式以供学习是违反直觉的。
But learning intrinsic patterns from images within a training set can be detrimental. Although we enforce and promote the learning of patterns from input images, actually having a network that learns the intrinsic patterns of images as they pass through the network will reduce the generalization capability of the network to data it hasn’t seen during its training phase.
但是,从训练集中的图像中学习内在模式可能是有害的。 尽管我们加强并促进了从输入图像中学习模式的学习,但实际上拥有一个可以在图像通过网络时学习图像的固有模式的网络,会降低网络对其在训练阶段未看到的数据的泛化能力。
Images have a large variety of artistic style. For example, there are several different ways individuals can write the number ‘8’; having a network focus on the detailed patterns from images within the training set will affect it’s generalization capability negatively.
图像具有多种艺术风格。 例如,个人可以用几种不同的方式写数字“ 8 ”。 将网络集中在训练集中图像的详细图案上将对它的泛化能力产生负面影响。
Finally, as a result of subsampling, there is the added benefit of an increase of feature maps generated within the network.
最后,作为二次采样的结果,增加了在网络内生成的特征图的额外好处。
我希望您觉得这篇文章有用。 (I hope you found the article useful.)
To connect with me or find more content similar to this article, do the following:
要与我联系或查找更多类似于本文的内容,请执行以下操作:
深度学习 下采样层






 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)